
GitHub - facebookresearch/dinov3: Reference PyTorch implementation and models for DINOv3
Reference PyTorch implementation and models for DINOv3 - facebookresearch/dinov3
… @timdarcet.bsky.social, Theo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, @jmairal.bsky.social, Herve Jegou, Patrick Labatut, Piotr Bojanowski
And of course, it’s open source! github.com/facebookrese...
📜 Paper: ai.meta.com/research/pub...
14.08.2025 18:50 —
👍 2
🔁 0
💬 0
📌 0

Immensely proud to have been part of this project. Thank you to the team: @oriane_simeoni, @huyvvo, @baldassarrefe.bsky.social, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michael Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, …
14.08.2025 18:50 —
👍 1
🔁 0
💬 1
📌 0

And here’s my favorite figure from the paper, showing high resolution DINOv3 representations in all their detail-capturing glory ✨
14.08.2025 18:50 —
👍 1
🔁 0
💬 1
📌 0

To recap:
1) The promise of SSL is finally realized, enabling foundation models across domains
2) High quality dense features enabling SotA applications
3) A versatile family of models for diverse deploy scenarios
So many great ideas (Gram anchoring!) to how we got there, please read the paper!
14.08.2025 18:50 —
👍 2
🔁 0
💬 1
📌 0

Satellite you said? Yes, the same DINOv3 algorithm trained on satellite imagery produces a SotA model for geospatial tasks like canopy height estimation. And of course, learns beautiful feature maps. This is the magic of SSL 🪄
14.08.2025 18:50 —
👍 1
🔁 0
💬 1
📌 0
3) DINOv3 is a family of models covering all use cases:
• ViT-7B flagship model
• ViT-S/S+/B/L/H+ (21M-840M params)
• ConvNeXt variants for efficient inference
• Text-aligned ViT-L (dino.txt)
• ViT-L/7B for satellite
All inheriting the great dense features of the 7B!
14.08.2025 18:50 —
👍 1
🔁 0
💬 1
📌 0

Well, Jianyuan Wang of VGGT fame simply dropped DINOv3 into his pipeline and off-handedly got a new SotA 3D model out. Seems promising enough?
14.08.2025 18:50 —
👍 2
🔁 0
💬 1
📌 0
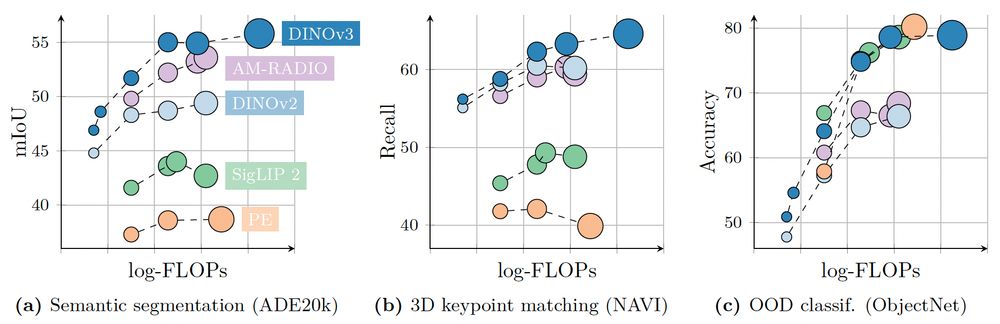
But what do these great features bring us? We reached SotA on three long-standing vision tasks, simply by building on a frozen ❄️ (!) DINOv3 backbone: detection (66.1 mAP@COCO), segmentation (63 mIoU@ADE), depth (eg 4.3 ARel@NYU). Not convinced yet?
14.08.2025 18:50 —
👍 1
🔁 0
💬 1
📌 0


2) DINOv3’s global understanding is strong, but its dense representations truly shine! There’s a clear gap between DINOv3 and prior methods across many tasks. This matters as pretrained dense features power many applications: MLLMs, video&3D understanding, robotics, generative models, …
14.08.2025 18:50 —
👍 1
🔁 0
💬 1
📌 0
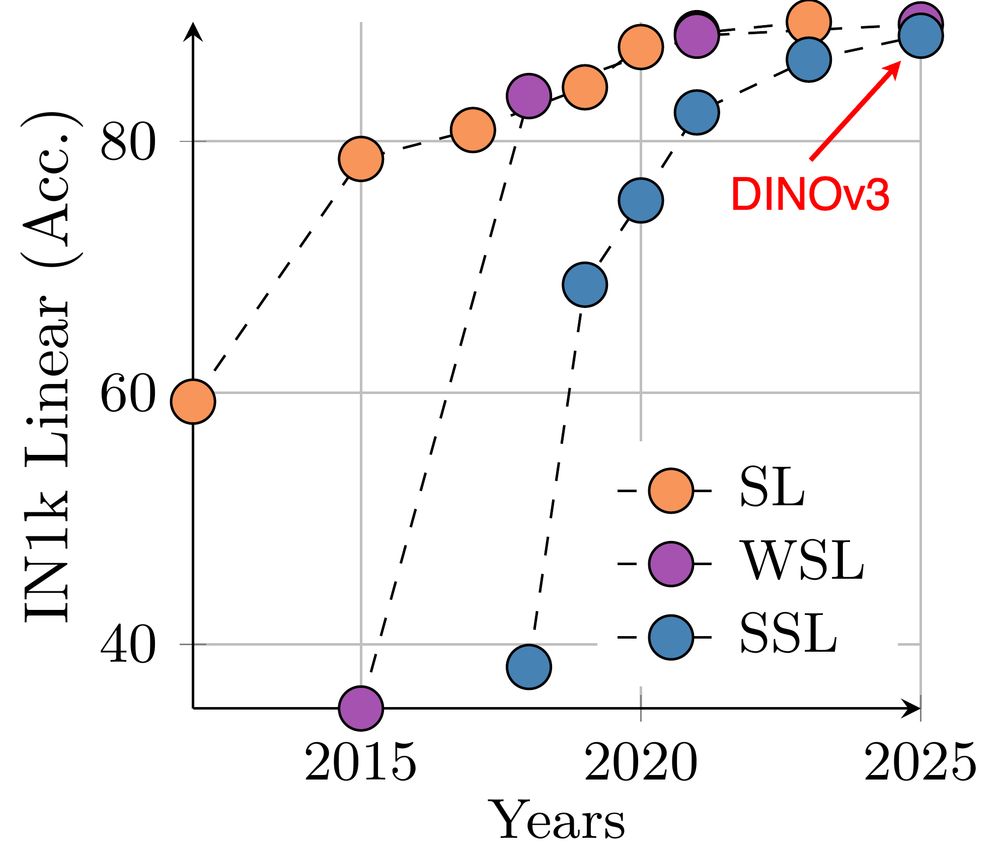
1) Some history: on ImageNet classification, supervised and weakly-supervised models converged to the same plateau over the last years. With DINOv3, SSL finally reaches that level. This alone is a big deal: no more reliance on annotated data!
14.08.2025 18:50 —
👍 2
🔁 0
💬 1
📌 0

Introducing DINOv3 🦕🦕🦕
A SotA-enabling vision foundation model, trained with pure self-supervised learning (SSL) at scale.
High quality dense features, combining unprecedented semantic and geometric scene understanding.
Three reasons why this matters👇
14.08.2025 18:50 —
👍 25
🔁 8
💬 2
📌 2
✨Introducing SENSEI✨ We bring semantically meaningful exploration to model-based RL using VLMs.
With intrinsic rewards for novel yet useful behaviors, SENSEI showcases strong exploration in MiniHack, Pokémon Red & Robodesk.
Accepted at ICML 2025🎉
Joint work with @cgumbsch.bsky.social
🧵
14.07.2025 08:02 —
👍 21
🔁 5
💬 1
📌 4

Scaling 4D Representations
Scaling 4D Representations
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d
10.07.2025 11:52 —
👍 20
🔁 8
💬 0
📌 0
Introducing 3DGSim🧩— an end-to-end 3D physics simulator trained only on multi-view videos. It achieves spatial & temporal consistency w/o ground truth 3D info or heavy inductive biases— enabling scalability & generalization🚀
Kudos to Mikel + @andregeist.bsky.social
www.youtube.com/watch?v=3Ar3...
04.04.2025 09:08 —
👍 7
🔁 6
💬 1
📌 0

