Shoutout to the authors of the wonderful papers i.e. CtRNet-X, DUSt3R, Segment Anything, CLIP and Pytorch3D and for open-sourcing their codebase to advance science and make this effort happen!
Please check these works out if you haven’t already!
24.04.2025 00:33 — 👍 1 🔁 0 💬 0 📌 0
We have released our improved extrinsics. Try it out now at droid-dataset.github.io and read more details about it in the updated DROID paper at arxiv.org/abs/2403.12945
This was a fun collaboration with
@vitorguizilini, @SashaKhazatsky and @KarlPertsch!
23.04.2025 23:50 — 👍 1 🔁 0 💬 1 📌 0
There’s room to improve. Future work could explore:
• Extending to in-the-wild scenes via foundation models for robot segmentation & keypoints.
• Ensembling predictions over time for better temporal consistency.
• Fine-tuning pointmap models on real robot data to handle cluttered tabletops.
8/n
23.04.2025 23:50 — 👍 1 🔁 0 💬 1 📌 0
Large-scale auto calibration in robotics is challenging, and our pipeline has some limits:
• CtRNet-X is trained on Panda; generalization to other robots is untested.
• DUSt3R struggles with clutter or minimal view overlap.
• Steps 2️⃣ & 3️⃣ may yield false positives in tough lighting or geometry.
7/n
23.04.2025 23:50 — 👍 0 🔁 0 💬 1 📌 0

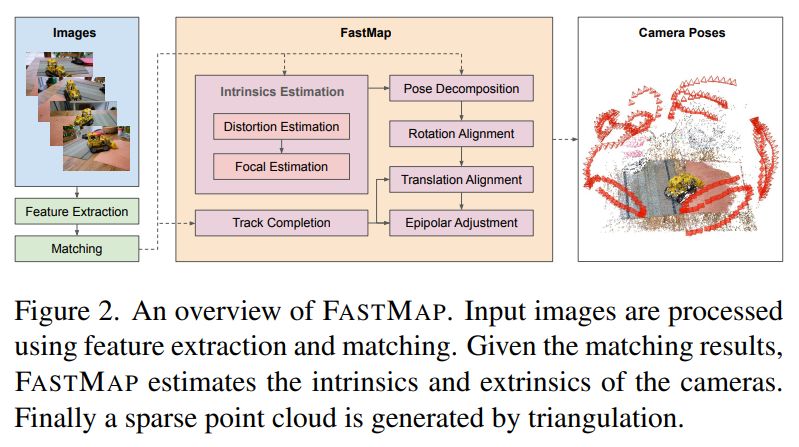
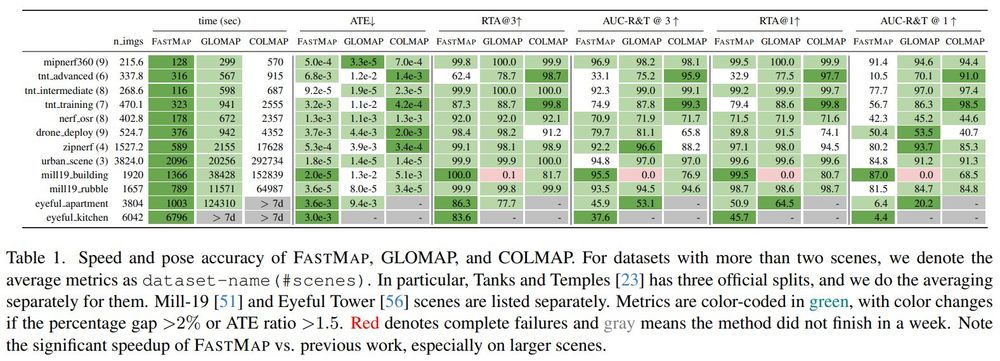
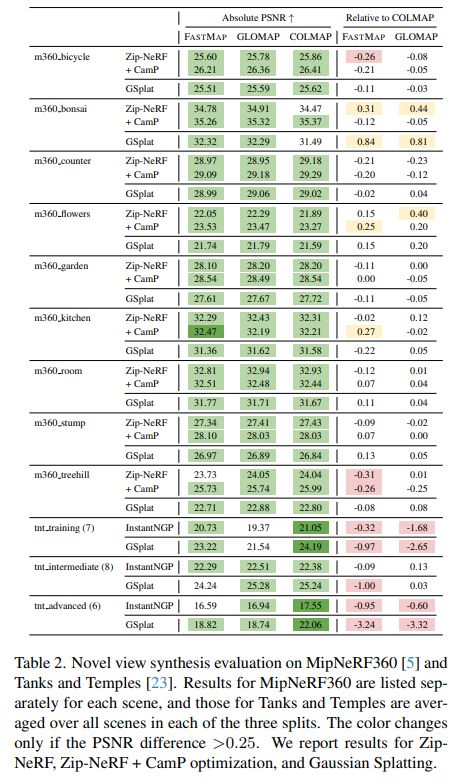
Similarly, we plot the distribution of number of matched points and cumulative curve after 3️⃣, helping to identify the top quantile of well-calibrated camera pairs within each lab.
6/n
23.04.2025 23:50 — 👍 0 🔁 0 💬 1 📌 0

Automatically calibrating a large-scale dataset is challenging. We provide quality assessment metrics across all three stages, with flexibility to narrow bounds for downstream tasks as needed.
1️⃣ and 2️⃣ quality metrics show IOU and Reprojection-error distributions post-calibration.
5/n
23.04.2025 23:50 — 👍 0 🔁 0 💬 1 📌 0

Below we show the Camera-to-Camera transformations, post-calibration improves the alignment of obtained pointclouds!
4/n
23.04.2025 23:50 — 👍 0 🔁 0 💬 1 📌 0
We provide:
🤖 ~36k calibrated episodes with good-quality extrinsic calibration
🦾 ~24k calibrated multi-view episodes with good-quality multi-view camera calibration
✅ Quality assessment metrics for all provided camera poses
3/n
23.04.2025 23:50 — 👍 0 🔁 0 💬 1 📌 0
To achieve this, we utilize:
1️⃣ Auto Segment Anything (SAM) based filtering (Camera-to-Base Calibration)
2️⃣ Tuned CtRNet-X for bringing in additional cams (Camera-to-Base Calibration)
3️⃣ Pretrained DUST3R with depth-based pose optimization (Camera-to-Camera Calibration)
2/n
23.04.2025 23:50 — 👍 0 🔁 0 💬 1 📌 0
Introducing ✨Posed DROID✨, results of our efforts at automatic post-hoc calibration of a large-scale robotics manipulation dataset.
Try it out at: droid-dataset.github.io
Learn more at:
🌐 arXiv: arxiv.org/pdf/2403.12945
📄 Blog: medium.com/p/4ddfc45361d3
🧵 1/n
23.04.2025 23:50 — 👍 5 🔁 1 💬 1 📌 0
3D Vision Language Models (VLMs) for Robotic Manipulation: Opportunities and Challenges
🔗 Learn more & submit your work: robo-3dvlms.github.io
Join us in shaping the future of robotics, 3D vision, and language models! 🤖📚 #CVPR2025
10.02.2025 17:00 — 👍 3 🔁 0 💬 0 📌 0
🎤 We’re honored to host top experts in the field:
⭐ Angel Chang (Simon Fraser University)
⭐ Chelsea Finn (Stanford University)
⭐ Hao Su (UC San Diego)
⭐ Katerina Fragkiadaki (CMU)
⭐ Yunzhu Li (Columbia University)
⭐ Ranjay Krishna (University of Washington)
5/N
10.02.2025 17:00 — 👍 3 🔁 0 💬 1 📌 0
🎯 Key Topics:
✅ 3D Vision-Language Policy Learning
✅ Pretraining for 3D VLMs
✅ 3D Representations for Policy Learning
✅ 3D Benchmarks & Simulation Frameworks
✅ 3D Vision-Language Action Models
✅ 3D Instruction-Tuning & Pretraining Datasets for Robotics
4/N
10.02.2025 17:00 — 👍 2 🔁 0 💬 1 📌 0
📢 Call for Papers: Submission opens today!
📅 Deadline: April 15, 2024 (11:59 PM PST)
📜 Format: Up to 4 pages (excluding references/appendices), CVPR template, anonymized submissions
🏆 Accepted papers: Poster presentations, with selected papers receiving spotlight talks!
3/N
10.02.2025 17:00 — 👍 0 🔁 0 💬 1 📌 0
🔍 Explore how 3D perception and language models can enhance robotic manipulation in the era of foundation models. Engage with leading experts and be part of this new frontier in 3D-based VLMs/VLAs for robotics.
2/N
10.02.2025 17:00 — 👍 0 🔁 0 💬 1 📌 0

🚀Exciting News! Join us at the inaugural #CVPR2025 Workshop on 3D Vision Language Models (VLMs) for Robotics Manipulation on June 11, 2025, in Nashville, TN! 🦾
robo-3dvlms.github.io
1/N
@cvprconference.bsky.social
10.02.2025 17:00 — 👍 13 🔁 0 💬 1 📌 1
Welcome onboard!
18.01.2025 02:08 — 👍 3 🔁 0 💬 0 📌 0
Done, welcome aboard!
17.01.2025 18:55 — 👍 4 🔁 0 💬 0 📌 0
Welcome on board!
20.12.2024 09:16 — 👍 5 🔁 0 💬 0 📌 0
Congrats on the release, demos look cool and it's open source 👏
04.12.2024 08:51 — 👍 9 🔁 2 💬 1 📌 0
In a world full of AI, authenticity will be the most valuable thing in the universe.
30.11.2024 02:39 — 👍 75 🔁 6 💬 7 📌 1
Hello 👋
28.11.2024 14:53 — 👍 1 🔁 0 💬 1 📌 0
YouTube video by BMVA: British Machine Vision Association
1 Andrew Davison, Imperial College London - BMVA Symposium: Robotics Foundation & World Models
For my first post on Bluesky, this recent talk I did at the recent BMVA one day meeting on World Models is a good summary of my work on Computer Vision, Robotics and SLAM, and my thoughts on a bigger picture of #SpatialAI.
youtu.be/NLnPG95vNhQ?...
28.11.2024 14:22 — 👍 90 🔁 23 💬 5 📌 2
Just included :) Welcome @ajdavison.bsky.social!
go.bsky.app/HcQYMj
28.11.2024 14:51 — 👍 5 🔁 0 💬 0 📌 0
Check out this BEAUTIFUL interactive blog about cameras and lenses
ciechanow.ski/cameras-and-...
27.11.2024 02:54 — 👍 75 🔁 16 💬 6 📌 1
Hello 👋 Would love to join!
26.11.2024 02:39 — 👍 1 🔁 0 💬 0 📌 0
GitHub - SLAM-Handbook-contributors/slam-handbook-public-release: Release repo for our SLAM Handbook
Release repo for our SLAM Handbook. Contribute to SLAM-Handbook-contributors/slam-handbook-public-release development by creating an account on GitHub.
We are in the process of editing a SLAM handbook, to be published by Cambridge University Press, with many *stellar* contributors. Part 1 is available as an online draft for public comments. Help us find bugs/problems!
Link to release repo is here: lnkd.in/gZhTkaxb
16.11.2024 15:45 — 👍 84 🔁 26 💬 5 📌 2
Added you!
25.11.2024 10:12 — 👍 0 🔁 0 💬 0 📌 0
Welcome onbaord!
25.11.2024 09:59 — 👍 1 🔁 0 💬 0 📌 0
ML & CV for robot perception
assistant professor @ Uni Bonn & Lamarr Institute
interested in self-learning & autonomous robots, likes all the messy hardware problems of real-world experiments
https://rpl.uni-bonn.de/
https://hermannblum.net/
Professor of Computer Vision and AI at TU Munich, Director of the Munich Center for Machine Learning mcml.ai and of ELLIS Munich ellismunich.ai
cvg.cit.tum.de
PhD student with Andreas Geiger and IMPRS-IS.
Studying embodied intelligence via autonomous driving.
2nd year PhD at UCSD w/ @rajammanabrolu.bsky.social
Prev: @ltiatcmu.bsky.social @umich.edu
Research: Agents🤖, Reasoning🧠, Games👾
PhD in 3D Vision @Stanford | MSc CS @ETH | Ex @Qualcomm, @MercedesBenz
W: sayands.github.io
Entrepreneur | Manufacturing | Design
Discussing strategies and tools for building products more effectively. 3D printing, Robotics, computer vision, AI
🔬 PhD Industrial Engineering
📈 Startup Founder
🏎️ Car Nerd
🔧 Maker
🏳️🌈 San Francisco
Research Scientist at Meta
thodan.github.io
Senior Research Scientist @ NVIDIA
(Lead: https://github.com/NVlabs/DoRA)
Ph.D. @ Georgia Tech | Multimodal AI
https://minhungchen.netlify.app/
AI & Transportation | MIT Associate Professor
Interests: AI for good, sociotechnical systems, machine learning, optimization, reinforcement learning, public policy, gov tech, open science.
Science is messy and beautiful.
http://www.wucathy.com
Curated feed of interesting and novel robotics papers.
See lists tab if you are into robotics research.
Starter pack -> https://go.bsky.app/SxrgryM
A "doctor" courtesy of the Stanford AI Lab 🤖
Working at a tiny startup focused on letting people make fun little games with AI
Co-creator of The Gradient and Last Week in AI
fan of fun, Russian
www.andreykurenkov.com/
Large-Scale Robot Decision Making @GoogleDeepMind European @ELLISforEurope - imitation interaction transfer - priors: @oxfordrobots @berkeley_ai @ETH @MIT
PhD - Research @hf.co 🤗
TRL maintainer
PhD Student 🤖 Cognitive Robotics @ UCI
Lecturer and researcher at the Costa Rica Institute of Technology.
Currently I play with robot swarms. Somedays I love them, others I hate them...
Member of technical staff @periodiclabs
Open-source/open science advocate
Maintainer of torchrl / tensordict / leanrl
Former MD - Neuroscience PhD
https://github.com/vmoens
PhD student at @real.itu.dk studying soft modular robotics and distributed manipulation.
Neuro-AI Research Scientist. Brains-Minds-Machines, Self-Awareness, Consciousness for Robotics and Health. 🧠🤖🦾
UMich 〽️ x USC ✌️ x NSU 🔰
Assistant Teaching Professor, Northeastern University (Robotics)
From SLAM to Spatial AI; Professor of Robot Vision, Imperial College London; Director of the Dyson Robotics Lab; Co-Founder of Slamcore. FREng, FRS.