Thanks! :)
17.10.2025 06:44 — 👍 0 🔁 0 💬 0 📌 0
Yes! Next Wednesday! 🙏
16.10.2025 16:33 — 👍 1 🔁 0 💬 1 📌 0
Congratulations! 🎉🎉 And welcome to Frankfurt!
16.10.2025 08:37 — 👍 1 🔁 0 💬 1 📌 0

Psychological measurement of subjective visual experiences through image reconstruction. (a) Mapping of brain, stimulus, and mind. Dots represent instances of visual experience (e.g., an image, perception, and corresponding brain activity). Veridical perception assumes that the mind accurately represents stimuli. The brain–mind mapping is considered fixed, while the brain–stimulus relationship is empirically identified. (b) Nonveridical perception (e.g., mental imagery, attentional modulation, and illusions) occurs when perceived content diverges from physical properties. The fixed brain–mind mapping and decoders trained on brain activity under veridical conditions allow the reconstruction of mental content as an image. (c) Reconstruction of mental imagery is achieved using models trained on brain activity from natural images.
Visual image reconstruction from brain activity via latent representation www.annualreviews.org/content/jour... by @ykamit.bsky.social et al.; mental imagery, #neuroscience
18.09.2025 09:11 — 👍 9 🔁 1 💬 1 📌 0
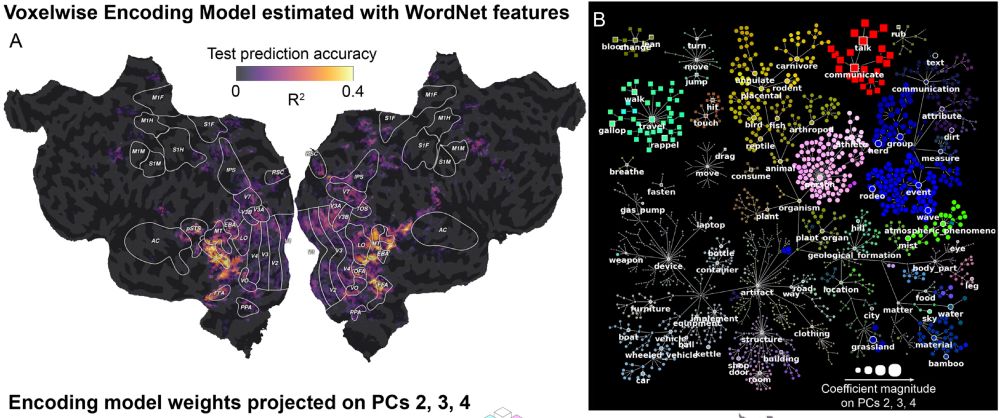
New paper in Imaging Neuroscience by Tom Dupré la Tour, Matteo Visconti di Oleggio Castello, and Jack L. Gallant:
The Voxelwise Encoding Model framework: A tutorial introduction to fitting encoding models to fMRI data
doi.org/10.1162/imag...
16.05.2025 02:08 — 👍 26 🔁 9 💬 0 📌 0
(1/6) Thrilled to share our triple-N dataset (Non-human Primate Neural Responses to Natural Scenes)! It captures thousands of high-level visual neuron responses in macaques to natural scenes using #Neuropixels.
11.05.2025 13:33 — 👍 122 🔁 42 💬 2 📌 1
Yes indeed. It probably has something to do with learning dynamics that favors increasing the complexity gradually. Or it could be that the loss landscape has edges between high and low complexity volumes
15.03.2025 13:31 — 👍 3 🔁 0 💬 0 📌 0
In AlexNet, however, the first layers are the most predictive. That's because they have bigger filters at earlier layers (see Miao and Tong 2024)
15.03.2025 12:35 — 👍 1 🔁 0 💬 1 📌 0
V1 is usually predicted by more intermediate layers than early layers but it depends on the architecture of the model. In Cadena et al 2019 block3_conv1 in VGG19 was the most predictive. Early layers in VGG have very small receptive fields which makes it difficult to capture V1-like features.
15.03.2025 12:35 — 👍 1 🔁 0 💬 1 📌 0
This was the most predictive layer of V1 in the VGG16 model. Same for IT, it was block4_conv2.
15.03.2025 10:58 — 👍 0 🔁 0 💬 1 📌 0
and then starts increasing again with further training to fit the target function. This is the most likely explanation for the initial drop in V1 prediction.
15.03.2025 10:57 — 👍 1 🔁 0 💬 1 📌 0
We also observed in separate experiments on the simple CNN models that the complexity of the models "resets" to a low value (lower than its random-weight complexity) after the first training epoch (likely using the linear part of the activation function)
15.03.2025 10:57 — 👍 1 🔁 0 💬 1 📌 0
Thanks for your interest! Object recognition performance increases directly starting from the first training epoch and nevertheless V1 prediction drops considerably so this drop supports the non significance of object recognition training for V1.
15.03.2025 10:57 — 👍 1 🔁 0 💬 1 📌 0

The legend of the left plot was missing!
14.03.2025 17:32 — 👍 0 🔁 0 💬 0 📌 0
15/15
It is also important to use various ways to assess model strengths and weaknesses, not just one like prediction accuracy.
13.03.2025 21:32 — 👍 1 🔁 0 💬 1 📌 0
14/15
Our results also emphasize the importance of rigorous controls when using black box models like DNNs in neural modeling. They can show what makes a good neural model, and help us generate hypotheses about brain computations
13.03.2025 21:32 — 👍 2 🔁 0 💬 1 📌 0
13/15
Our results suggest that the architecture bias of CNNs is key to predicting neural responses in the early visual cortex, which aligns with results in computer vision, showing that random convolutions suffice for several visual tasks.
13.03.2025 21:32 — 👍 0 🔁 0 💬 1 📌 0
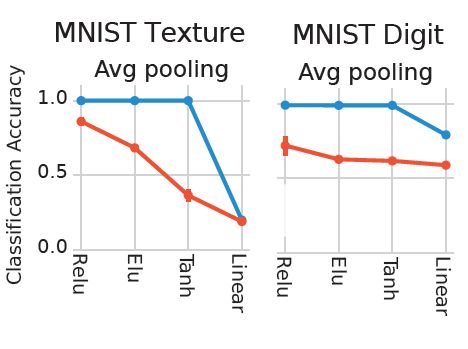
12/15
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
13.03.2025 21:32 — 👍 0 🔁 0 💬 1 📌 0

11/15
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination
13.03.2025 21:32 — 👍 0 🔁 0 💬 1 📌 0
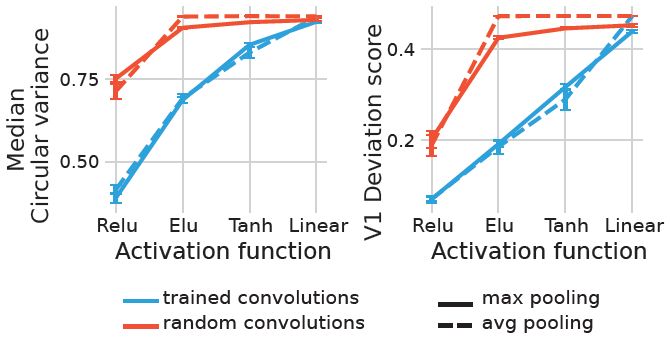
10/15
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.
13.03.2025 21:32 — 👍 0 🔁 0 💬 1 📌 0
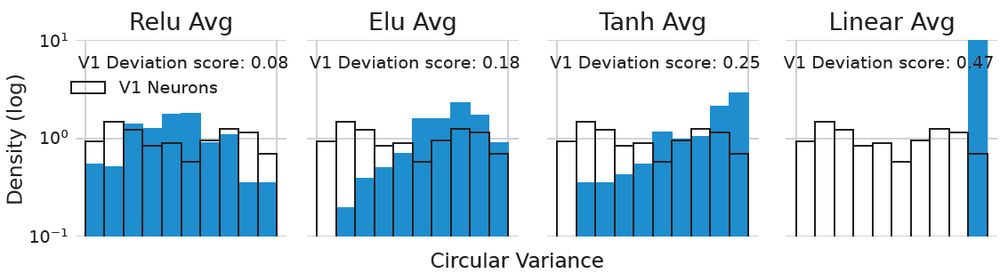
9/15
We quantified the orientation selectivity (OS) of artificial neurons using circular variance and calculated how their distribution deviates from the distribution of an independent dataset of experimentally recorded v1 neurons
13.03.2025 21:32 — 👍 0 🔁 0 💬 1 📌 0
8/15
ReLU was introduced to DNN models inspired by sparsity of biological neural systems and the i/o function of biological neurons.
To test its biological relevance, we looked for characteristic of early visual processing: orientation selectivity and the capacity to support texture discrimination
13.03.2025 21:32 — 👍 0 🔁 0 💬 1 📌 0
7/15
Importantly, these findings hold true both for firing rates in monkeys and human fMRI data, suggesting their generalizability.
13.03.2025 21:32 — 👍 1 🔁 0 💬 1 📌 0
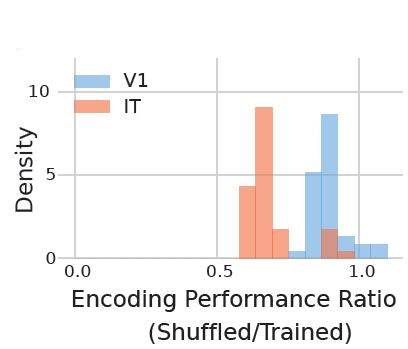
6/15
Even when we shuffled the trained weights of the convolutional filters, V1 models were way less affected than IT
13.03.2025 21:32 — 👍 0 🔁 0 💬 1 📌 0
5/15
This means that predicting responses in higher visual areas (e.g., IT, VO) strongly depends on precise weight configurations acquired through training in contrast to V1, highlighting the functional specialization of those areas.
13.03.2025 21:32 — 👍 0 🔁 0 💬 1 📌 0
Comp neuro @ Champalimaud
Mathematics Sorceror (sensory alchemist) at the Arctangent Transpetroglyphics Algra Laboratory (ATAL), I transflarnx mathematics into living rainbows. http://owen.maresh.info https://github.com/graveolensa
Psoeppe-Tlaxtlal, (an undreamt splendour?)
Associate Professor in Machine Learning, Aalto University. ELLIS Scholar.
http://arno.solin.fi
Senior Fellow at @brookings.edu. Previously Chief Economist at IIF and Chief FX Strategist at Goldman Sachs.
Comp Neuro, ML, Dynamical Systems 🧠🤖PhD student at Harvard & Kempner Institute. Prev at McGill, Mila, EPFL.
A platform for life sciences. Publications, research protocols, news, events, jobs and more. Sign up at https://www.lifescience.net.
neuromantic - ML and cognitive computational neuroscience - PhD student at Kietzmann Lab, Osnabrück University.
⛓️ https://init-self.com
(she/her) UKRI FLF - Professor in Neuroscience. Started doing robotic/AI before it was cool, moved on to Neuroscience and now obsessed with Transcranial Ultrasound Stimulation.
PhD student @edinburgh-uni.bsky.social
NeuroRSE intern @flatironinstitute.org
NeuroAI intern @cshlnews.bsky.social
Trying to understand spatial computation and memory in biological neural networks.
I run a lot. wulfdewolf.github.io
PhD student in visual representation learning at Valeo.ai and Sorbonne Université (MLIA)
Spatial+systems neuroscientist | Working out how the 🧠 generates 🌐 to find its 🧭 | Incoming Lecturer (Asst Prof) at the University of Manchester | Big fan of ancient things 🏺📜
This is the channel of the Max Planck Institute for Biological Cybernetics. We conduct basic research in the neurosciences and belong to the Max Planck Society, a global top 5 research organization with its 84 Max Planck Institutes and 31 Nobel Laureates.
In search of computational principles of natural adaptive behavior. Postdoc with Peter Dayan @mpicybernetics.bsky.social
Website: http://roxanazeraati.org/
Neuroscientist obsessed with brain structure and comparative neuroanatomy.
They’re not circuits. It’s not wiring. Cortex is a resonant mesh.
https://www.researchgate.net/profile/Matt-Kirkcaldie [ image by https://mattcoyle.net ]
Research Fellow, University of Oxford
Theology, philosophy, ethics, politics, environmental humanities
Associate Director @LSRIOxford
Anglican Priest
https://www.theology.ox.ac.uk/people/revd-dr-timothy-howles
👨🔬 Neuroscientist at the Donders Institute in the Battaglia lab.
🧠 Previously: International Brain Laboratory
Using Neuropixels and virtual-reality to understand how the brain creates internal models of the world.
www.guidomeijer.com
PhD candidate in cognitive neuroscience
(auditory) working memory | MEG | she/her
🗺️ CoBIC, frankfurt
Postdoc @ Princeton AI Lab
Natural and Artificial Minds
Prev: PhD @ Brown, MIT FutureTech
Website: https://annatsv.github.io/
I’m not like the other Bayesians. I’m different.
Thinks about philosophy of science, AI ethics, machine learning, models, & metascience. postdoc @ Princeton.
Tenure-track assistant professor (RTD-b) CIMeC - #UniTrento and co-founder of Mountain Maps.
🌍: https://paolorota.eu