Reports of AI eating entry level jobs are greatly exaggerated.
My guess is current and near-future LLMs are more likely to increase the demand for programmers, not decrease demand (Jevons Paradox).
18.07.2025 17:06 — 👍 1 🔁 0 💬 1 📌 0
There isn't a canonical version, but there are retrieval models from GTE and Nomic which might work for your task.
GTE: huggingface.co/Alibaba-NLP/...
Nomic: huggingface.co/nomic-ai/mod...
20.02.2025 16:35 — 👍 1 🔁 0 💬 0 📌 0
For more details, including our simple training method, see Benjamin Clavié's twitter announcement, our model, blog post, and paper.
Twitter: x.com/bclavie/stat...
Model: huggingface.co/answerdotai/...
Blog: www.answer.ai/posts/2025-0...
Paper: arxiv.org/abs/2502.03793
10.02.2025 18:13 — 👍 1 🔁 0 💬 0 📌 0

Can all encoders be instruction-tuned? Can we replicate ModernBERT's results with an older model like RoBERTa or peer model like GTE-en-MLM?
No. And it's not close.
10.02.2025 18:13 — 👍 2 🔁 0 💬 2 📌 0

When we finetune ModernBERT-Large-Instruct on task specific datasets, the generative MLM head is better or nearly equal to standard classification heads.
10.02.2025 18:13 — 👍 0 🔁 0 💬 1 📌 0
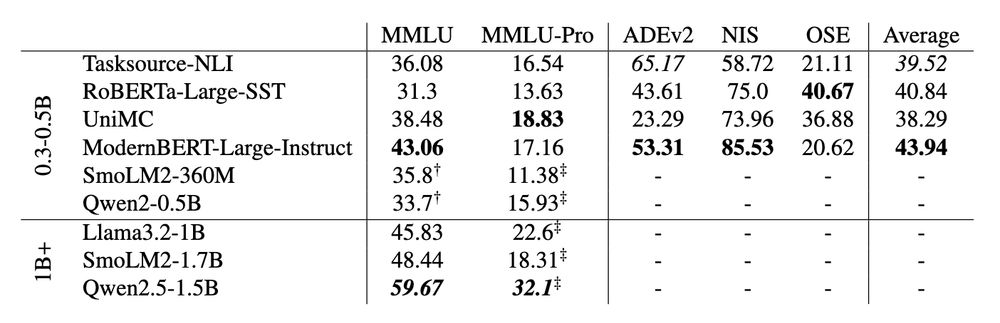
After instruction tuning on Flan, ModernBERT-Large-Instruct outperforms similarly sized LLMs on MMLU & MMLU-Pro, and achieves ~90 percent of Llama 3.2 1B's performance with ~65 percent fewer parameters.
10.02.2025 18:13 — 👍 1 🔁 0 💬 1 📌 0
![from transformers import pipeline
model_name = "answerdotai/ModernBERT-Large-Instruct"
fill_mask = pipeline("fill-mask", model=model_name, tokenizer=model_name)
text = """You will be given a question and options. Select the right answer.
QUESTION: If (G, .) is a group such that (ab)^-1 = a^-1b^-1, for all a, b in G, then G is a/an
CHOICES:
- A: commutative semi group
- B: abelian group
- C: non-abelian group
- D: None of these
ANSWER: [unused0] [MASK]"""
results = fill_mask(text)
answer = results[0]["token_str"].strip()
print(f"Predicted answer: {answer}") # Answer: B](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:psfkl7gi24rg5rhvv7z6mly3/bafkreid6ko23ckgz2mwpp7zj3p6n333vmg5c2r5bghon77g4el6322z6oa@jpeg)
from transformers import pipeline
model_name = "answerdotai/ModernBERT-Large-Instruct"
fill_mask = pipeline("fill-mask", model=model_name, tokenizer=model_name)
text = """You will be given a question and options. Select the right answer.
QUESTION: If (G, .) is a group such that (ab)^-1 = a^-1b^-1, for all a, b in G, then G is a/an
CHOICES:
- A: commutative semi group
- B: abelian group
- C: non-abelian group
- D: None of these
ANSWER: [unused0] [MASK]"""
results = fill_mask(text)
answer = results[0]["token_str"].strip()
print(f"Predicted answer: {answer}") # Answer: B
One of the questions we debated while training ModernBERT was whether a modern trained encoder would unlock zero-shot reasoning using only it's generative head?
Spoilers: the answer is yes.
10.02.2025 18:13 — 👍 29 🔁 6 💬 3 📌 0

The latest open artifacts (#6): Reasoning models, China's lead in open-source, and a growing multimodal space
Artifacts log 6 The open LM ecosystem yet again accelerates.
If you want to quickly catch up on all the open modeling things (DeepSeek, ModernBERT, etc.), this was a great overview, by @natolambert.bsky.social.
I somehow got into an argument last week with someone who was insisting that all models are industrial blackboxes... and I wish I'd had this on hand.
27.01.2025 15:05 — 👍 49 🔁 10 💬 0 📌 1
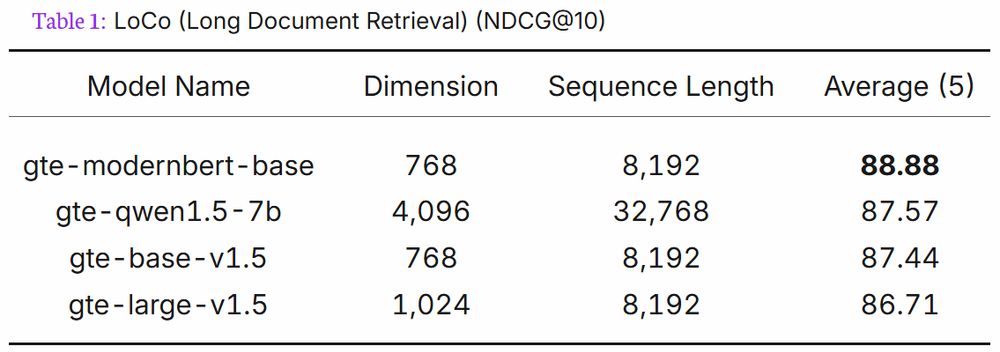
In addition to being the best retrieval model under 300M params on METB (without extra work), and top 10 for under 1B, here's a fun tidbit from Alibaba's GTE ModernBERT model card:
gte-modernbert-base beats gte-qwen1.5-7b on LoCo long context retrieval with 7B less parameters.
23.01.2025 19:22 — 👍 3 🔁 0 💬 1 📌 0
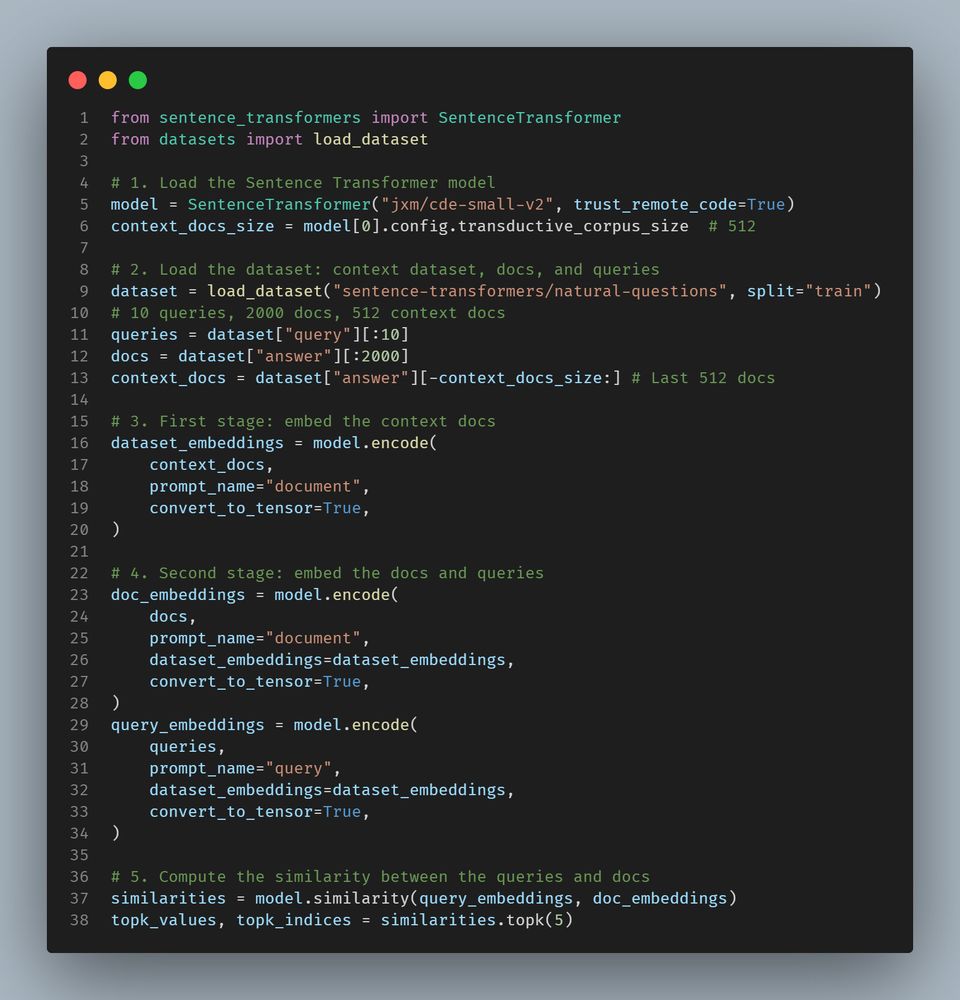
The newest extremely strong embedding model based on ModernBERT-base is out: `cde-small-v2`. Both faster and stronger than its predecessor, this one tops the MTEB leaderboard for its tiny size!
Details in 🧵
14.01.2025 13:21 — 👍 30 🔁 7 💬 1 📌 1
ModernBERT-embed-base is awesome because it allows to use ModernBERT-base for various tasks out-of-the-box
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!
14.01.2025 15:32 — 👍 12 🔁 2 💬 1 📌 0

Finally, a Replacement for BERT: Introducing ModernBERT
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
What's ModernBERT? It's a drop-in replacement for existing BERT models, but smarter, faster, and supports longer context.
Check out our announcement post for more details: huggingface.co/blog/modernb...
10.01.2025 18:28 — 👍 2 🔁 0 💬 0 📌 0
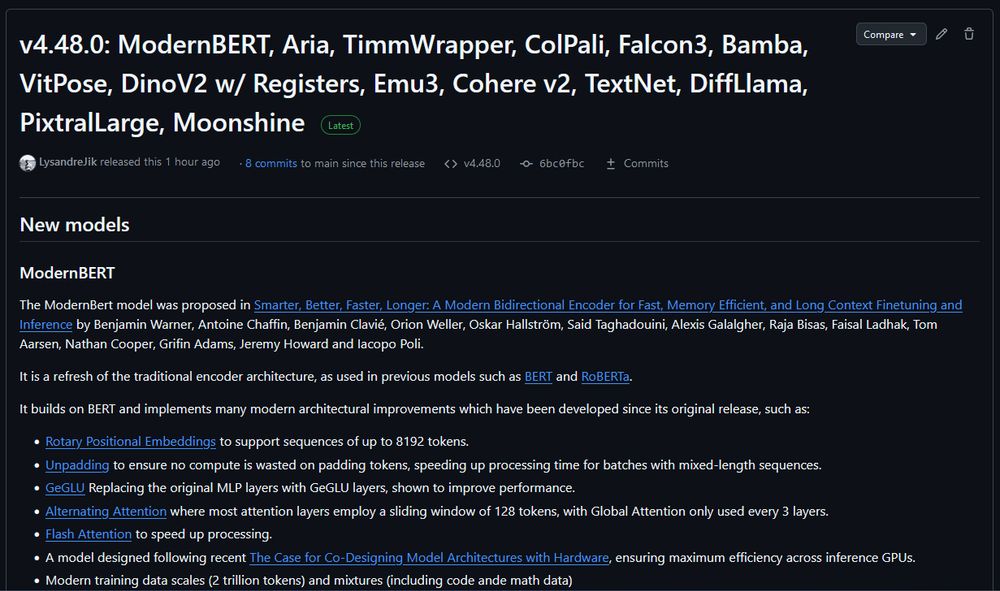
Transformers v4.48.0: ModernBERT, Aria, TimmWrapper, ColPali, Falcon3, Bamba, VitPose, DinoV2 w/ Registers, Emu3, Cohere v2, TextNet, DiffLlama, PixtralLarge, Moonshine
ModernBERT is officially released on Transformers v4.48.0. You no longer need to install from git to use.
If you are plugging ModernBERT into an existing encoder finetuning pipeline, try increasing the learning rate. We've found that ModernBERT tends to prefer a higher LR than older models.
10.01.2025 18:28 — 👍 11 🔁 3 💬 1 📌 0
*Actually, that’s good compared to the 4090’s PCIe 4 without NVLink
07.01.2025 07:12 — 👍 0 🔁 0 💬 0 📌 0
The good: 32GB
The bad: $2,000
The Ugly*: PCIe 5 without NVLink
07.01.2025 07:12 — 👍 0 🔁 0 💬 1 📌 0

Basically, a frontier model like OpenAI’s O1 is like a Ferrari SF-23. It’s an obvious triumph of engineering, designed to win races, and that’s why we talk about it. But it takes a special pit crew just to change the tires and you can’t buy one for yourself. In contrast, a BERT model is like a Honda Civic. It’s also an engineering triumph, but more subtly, since it is engineered to be affordable, fuel-efficient, reliable, and extremely useful. And that’s why they’re absolutely everywhere.
Via @simonwillison.net's excellent blog, I found this great quote about AI models, from @benjaminwarner.dev et al. www.answer.ai/posts/2024-1...
It seems to me that AI will be most relevant in people's lives because the Honda Civic is ubiquitous, not so much because everyone is driving a Ferrari.
01.01.2025 16:04 — 👍 2 🔁 1 💬 1 📌 0
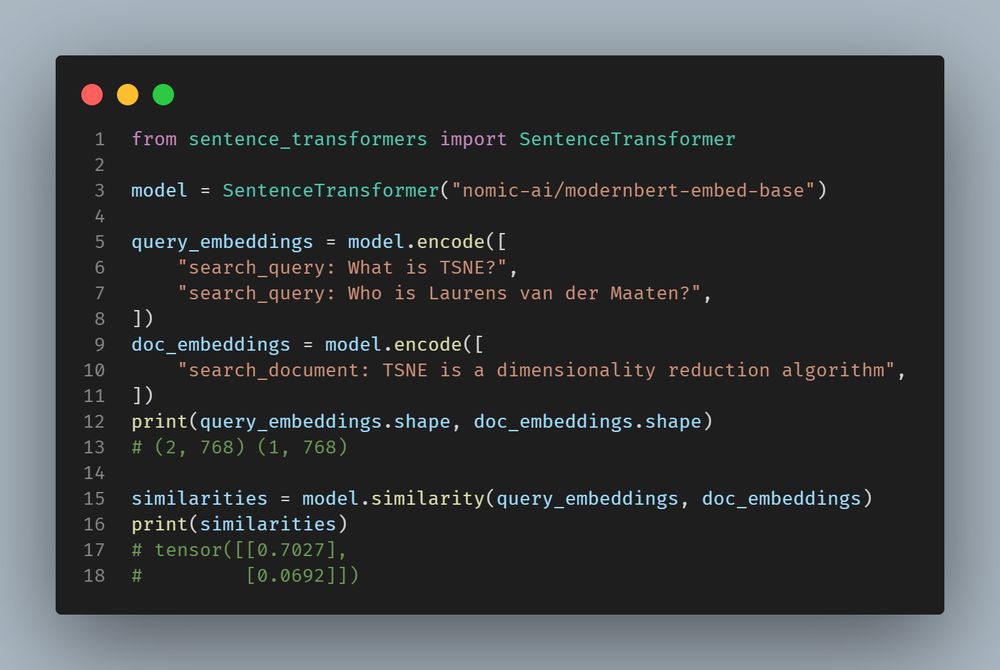
That didn't take long! Nomic AI has finetuned the new ModernBERT-base encoder model into a strong embedding model for search, classification, clustering and more!
Details in 🧵
31.12.2024 15:43 — 👍 37 🔁 10 💬 2 📌 1
ModernBERT is a “foundation model” so you’ll either need to finetune it for entailment/NLI or wait for someone else to finetune it. I suspect it would be good at NLI once finetuned.
24.12.2024 22:24 — 👍 3 🔁 0 💬 2 📌 0
We evaluated ModernBERT on MLDR using ColBERT-style retrieval using that code. That process was smaller scale than a full ColBERT finetune, which would need additional contrastive training, likely use multiple teacher models, etc as detailed here by @bclavie.bsky.social www.answer.ai/posts/2024-0...
24.12.2024 07:47 — 👍 1 🔁 0 💬 2 📌 0
Thanks. ModernBERT is a base model. It’ll need additional contrastive pretraining to really shine as a retrieval model, but our early results in the paper look promising. Hopefully there will be multiple open source retrieval tuned models to choose from early next year, including ColBERT finetunes.
24.12.2024 07:26 — 👍 2 🔁 0 💬 2 📌 0
Thanks for the kind words. We tried to fit as much information within our page limit as possible and have a comprehensive appendix.
As far as the name goes, all I’ll say is be careful not to use an overly strong code name.
22.12.2024 23:15 — 👍 3 🔁 0 💬 0 📌 0
(early results in our paper)
22.12.2024 22:08 — 👍 1 🔁 0 💬 0 📌 0
Thanks. It’ll need additional contrastive pretraining to really shine as a retrieval model, but our early results look promising. Hopefully there will be multiple open source retrieval tuned models to choose from early next year.
22.12.2024 22:07 — 👍 2 🔁 0 💬 1 📌 0
PS: BlueSky needs to make their really long account tags not count against the character limit.
22.12.2024 06:12 — 👍 5 🔁 0 💬 1 📌 0
I'm looking forward to seeing what you all will build with a modern encoder.
22.12.2024 06:12 — 👍 1 🔁 0 💬 1 📌 0
A big thanks to Iacopo Poli and @lightonai.bsky.social for sponsoring the compute to train ModernBERT, @bclavie.bsky.social for organizing the ModernBERT project, and to everyone who offered assistance and advice along the way. Also h/t to Johno Whitaker for the illustrations.
22.12.2024 06:12 — 👍 3 🔁 0 💬 1 📌 0
Thanks to my two co-leads: @nohtow.bsky.social , @bclavie.bsky.social , & the rest of our stacked author cast: @orionweller.bsky.social, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, @tomaarsen.com , @ncoop57.bsky.social , Griffin Adams, @howard.fm , & Iacopo Poli
22.12.2024 06:12 — 👍 6 🔁 1 💬 1 📌 0
Postdoc at Amazon on MLLM - ex CMU, PoliTo, IIT
https://gmberton.github.io/
PhD - Research @hf.co 🤗
TRL maintainer
🌐 https://ai.intellectronica.net/
👩💻 Expert AI Leadership (ex- Google, Microsoft, startups, ...)
👉 Follow me for ideas in AI engineering / strategy, and lots more...
•PhD student @ https://www.ucl.ac.uk/gatsby 🧠💻
•Masters Theoretical Physics UoM|UCLA🪐
•Intern @zuckermanbrain.bsky.social|
@SapienzaRoma | @CERN | @EPFL
https://linktr.ee/Clementine_Domine
Research Scientist at Google DeepMind, interested in multiagent reinforcement learning, game theory, games, and search/planning.
Lover of Linux 🐧, coffee ☕, and retro gaming. Big fan of open-source. #gohabsgo 🇨🇦
For more info: https://linktr.ee/sharky6000
Associate Professor @ UBC
computational sociology
machine learning is feminist
You only have to look at the Medusa straight on to see her. And she’s not deadly. She’s beautiful and she’s laughing.
www.lauraknelson.com
E-learning dev & AI educator at U of Arizona Libraries. Former head of UX at MIT Libraries. Winner of MIT Excellence Award. nicolehennig.com. Digital nomad from 2013-17, locationflexiblelife.com.
- vegetarian
- car-free
- universal basic income: yes
Developing AI for planetary health. Postdoc at Oxford with the Leverhulme Centre for Nature Recovery & assistant prof at Columbia IEOR (starting fall 2025).
https://lily-x.github.io
Ph.D. student at University of Washington CSE. NLP. IBM Ph.D. fellow (2022-2023). Meta student researcher (2023-) . ☕️ 🐕 🏃♀️🧗♀️🍳
Researcher in NLP, ML, computer music. Prof @uwcse @uwnlp & helper @allen_ai @ai2_allennlp & familiar to two cats. Single reeds, tango, swim, run, cocktails, מאַמע־לשון, GenX. Opinions not your business.
Professor of social computing at UW CSE, leading @socialfutureslab.bsky.social
social.cs.washington.edu
Researching planning, reasoning, and RL in LLMs. Previously: Google DeepMind, UC Berkeley, MIT. I post about: AI 🤖, flowers 🌷, parenting 👶, public transit 🚆. She/her.
http://www.jesshamrick.com
cs phd student and kempner institute graduate fellow at harvard.
interested in language, cognition, and ai
soniamurthy.com
Incoming faculty at the Max Planck Institute for Software Systems
Postdoc at UW, working on Natural Language Processing
Recruiting PhD students!
🌐 https://lasharavichander.github.io/
Building Astral: Ruff, uv, and other high-performance Python tools, written in Rust.
AI Architect | North Carolina | AI/ML, IoT, science
WARNING: I talk about kids sometimes
🤗 LLM whisperer @huggingface
📖 Co-author of "NLP with Transformers" book
💥 Ex-particle physicist
🤘 Occasional guitarist
🇦🇺 in 🇨🇭
Principal Ethicist @hf.co | Philosophy Ph.D. @sorbonne-universite.fr
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗






















