RapidQ - Wikipedia
Je sais pas si ça fonctionne encore : en.wikipedia.org/wiki/RapidQ
29.11.2025 22:13 — 👍 0 🔁 0 💬 1 📌 0
📢 Statement from ACL and EACL 2026 Organizers
On Nov 27, OpenReview was notified of a software bug that allowed unauthorized access to authors, reviewers, and area chairs. We are grateful to the OpenReview team for fixing the issue quickly. (🧵 1/3)
29.11.2025 09:28 — 👍 8 🔁 11 💬 1 📌 0
Statement by OpenReview on X
28.11.2025 00:04 — 👍 16 🔁 10 💬 2 📌 2

ndicateur 1.5 : Admission dans l'enseignement supérieur
(du point de vue de l'usager)
Unité 2022 2023 2024
(Cible PAP
2024)
2025
(Cible)
2026
(Cible)
2027
(Cible)
Part des néo-bacheliers ayant obtenu au moins
une proposition à la fermeture de Parcoursup
% 94,8 95 94,5 93,5 93,5 93,5

Dans ce contexte, la part
de néo-bacheliers recevant au moins une proposition
diminue légèrement (93,5 %, -1,0 point par rapport à 2024).
[ #VeilleESR #Parcoursup ] Il vient de se passer un truc extraordinaire : le gouvernement a atteint un de ses objectifs.
Celui de baisser la part des néobachliers recevant une proposition dans Parcoursup.
C'est sans doute une date historique, le début de démassification éducative, .
🧵
15.11.2025 16:43 — 👍 112 🔁 125 💬 5 📌 14
Cool seminar coming up at @inriaparisnlp.bsky.social. If you guys can't make it on site, a visio link will be provided (check out the seminar webpage 30mn before the talk)
09.11.2025 17:26 — 👍 1 🔁 1 💬 0 📌 0
Pourquoi pas Instagram ?
06.11.2025 12:26 — 👍 0 🔁 0 💬 1 📌 0

You need this fixed logsumexp function, otherwise you will have NaN gradients for the neural network. I personnaly came across this bug when building a CRF with the following transition structure for discontinuous named entity recognition, see here: aclanthology.org/2024.emnlp-m...
04.11.2025 09:12 — 👍 3 🔁 0 💬 0 📌 0
The use case: conditional random fields with forbidden transitions between tags. Altough implementing the forward function is trivial with Pytorch, see for example here: github.com/FilippoC/lig...
04.11.2025 09:12 — 👍 2 🔁 0 💬 1 📌 0

But now the backward pass works as expected, and you get null gradients for w1.
04.11.2025 09:12 — 👍 2 🔁 0 💬 1 📌 0

Yes: implement your own logsumexp function that fixes this bug. I found the workaround by coming across this github issue: github.com/pytorch/pyto...
The forward pass is basically the same, but using the custom logsumexp function.
04.11.2025 09:12 — 👍 2 🔁 0 💬 1 📌 0

But this will give you NaN gradient for w1 ! If you look at the gradient of w2, masked values have a null gradient, as expected. But for w1, instead of having a vector of null gradients, we have a vector of NaNs. This completly breaks gradient backprop and grad descent. So, is there a nice solution?
04.11.2025 09:12 — 👍 2 🔁 0 💬 1 📌 0

The input of the first logsumexp is completly masked, the second one is partially masked, the last one has no masked applied on it. Obviously, the first logit is equal to -inf. This means a "masked output probability" after softmax. We can then just compute a loss and backpropagate gradient.
04.11.2025 09:12 — 👍 2 🔁 0 💬 1 📌 0
One of the hardest Pytorch bug I had to debug is due to how the logsumexp behave with -inf masked inputs. Consider the following example. I build a vector of 3 logits, and each logit is the result of a logsumexp.
04.11.2025 09:12 — 👍 3 🔁 1 💬 2 📌 0
Hallucinant. C'est inacceptable. J'ai une ERC, que rétrospectivement j'ai eu la chance de rédiger à l'étranger avec un dispositif bien meilleur que ceux qui sont proposés en France et SURTOUT avec de quoi produire des résultats préliminaires que ce soit en terme de mentiring ou de moyens #esr
31.10.2025 10:29 — 👍 68 🔁 32 💬 2 📌 3
Universities across the world seeing this:
"its only wrong 45% of the time!!
Lets buy free licenses for our students, staff and faculty!!
Lets lock into contracts with rapacious predatory AI companies with shitty technofascist politics, sucking up water and jacking up electricity prices!!"
23.10.2025 13:19 — 👍 502 🔁 226 💬 5 📌 19
Qu'est ce que ça va être quand ils vont découvrir l'existence du manifeste ou de l'état et la revolution. 🙃
02.10.2025 20:07 — 👍 0 🔁 0 💬 1 📌 0
Not all scaling laws are nice power laws. This month’s blog post: Zipf’s law in next-token prediction and why Adam (ok, sign descent) scales better to large vocab sizes than gradient descent: francisbach.com/scaling-laws...
27.09.2025 14:57 — 👍 47 🔁 12 💬 1 📌 0
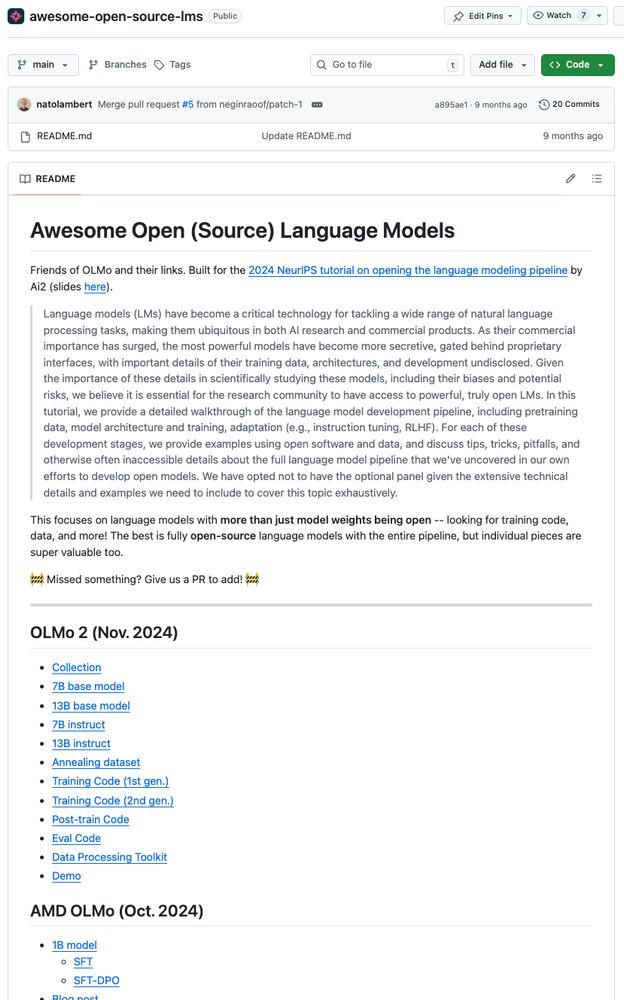

~9 months ago I spent some time with Luca Soldaini making a list of models and resources for language models that were more than just open weights (data, code, logs, etc included). It's getting out of date, could use some community contributions :)
14.09.2025 17:05 — 👍 24 🔁 3 💬 1 📌 0
J'ai pas encore testé, mais le dernier Mafia à l'air ultra stylé
30.08.2025 23:49 — 👍 1 🔁 0 💬 1 📌 0
For updates on AI, I increasingly just advise people to pick a discord they like and stick with it. Twitter stopped having interesting science chat ages ago, it’s just companies announcing their products and getting a bunch of meme QTs.
23.08.2025 14:29 — 👍 26 🔁 2 💬 2 📌 1
New Desk Rejection Practice for EMNLP 2025
For some time there has been substantial concern within the community regarding many aspects of reviewing, from poor quality, to too few reviewers in the pool, to poor quality reviews, to reviewers no...
This year, EMNLP ended up desk rejecting ~100 papers. For more insight into the process, and potential future changes, please see this blog post from the PCs: 2025.emnlp.org/desk-rejecti...
@christos-c.bsky.social @carolynrose.bsky.social @tanmoy-chak.bsky.social @violetpeng.bsky.social
20.08.2025 16:22 — 👍 13 🔁 4 💬 1 📌 1

Merge transducers for a BPE tokenizer.
My paper "Tokenization as Finite-State Transduction" was accepted to Computational Linguistics.
This was my final PhD degree requirement :)
The goal was to unify the major tokenization algorithms under a finite-state automaton framework. For example, by encoding a BPE tokenizer as a transducer.
15.08.2025 07:25 — 👍 30 🔁 6 💬 2 📌 1
#ClubContexte L'École Normale Supérieure de Paris-Saclay (à ne pas confondre avec l'École Normale Supérieure, ou «Ulm», qui est à Paris et pas à Ulm) est l'ancienne École Normale Supérieure de Cachan qui a déménagé: elle n'est située ni à Paris, ni à Saclay, mais à Gif-sur-Yvette …
14.08.2025 21:18 — 👍 31 🔁 4 💬 4 📌 1
2 weeks is always unreasonable. 🙃
14.08.2025 00:10 — 👍 3 🔁 0 💬 0 📌 0
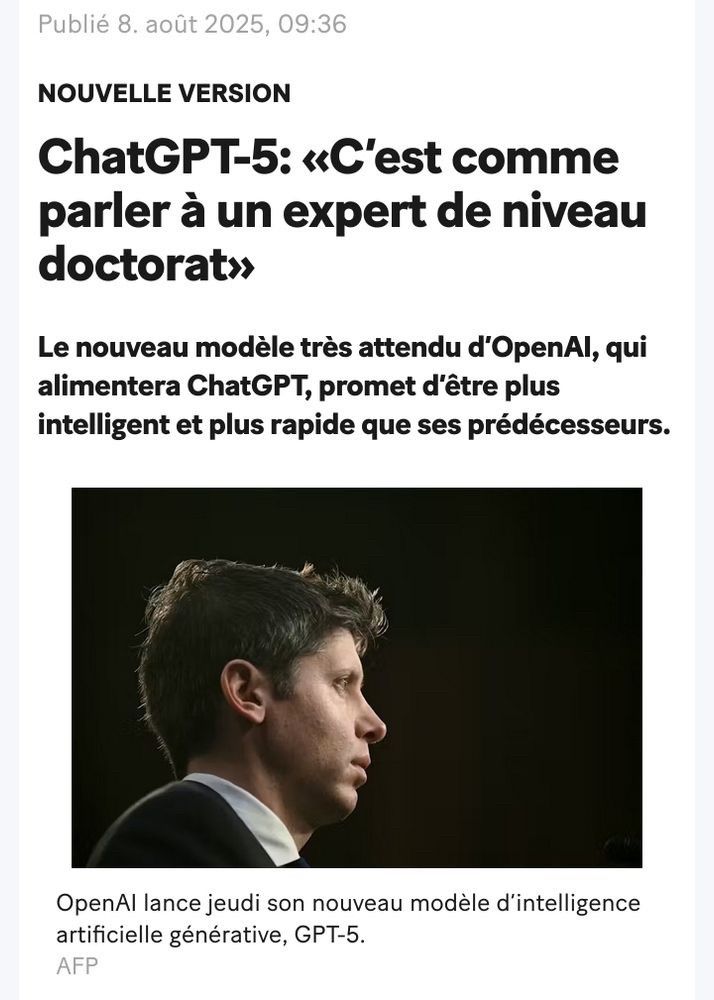
Titre d'un article : ChatGPT-5: «C'est comme parler à un expert de niveau
doctorat»
Un like = une phrase réaliste dite par CHAT GPT 5 s'il s'exprimait vraiment comme quelqu'un avec un doctorat.
09.08.2025 08:52 — 👍 502 🔁 131 💬 39 📌 0

ICML found hidden prompts in accepted papers. They have released a statement icml.cc/Conferences/...
Yes, it’s unacceptable. So is using an LLM to review a paper. Peer review is so broken.
24.07.2025 01:44 — 👍 99 🔁 33 💬 11 📌 10

ACL paper alert! What structure is lost when using linearizing interp methods like Shapley? We show the nonlinear interactions between features reflect structures described by the sciences of syntax, semantics, and phonology.
12.06.2025 18:56 — 👍 55 🔁 12 💬 3 📌 1
I think this will be my last time being an AC for an @aclmeeting.bsky.social / @emnlpmeeting.bsky.social related conference. Authors rebuttals are mostly very long LLM generated answers, and spending time reading them is not an interesting activity.
16.07.2025 12:49 — 👍 0 🔁 0 💬 0 📌 0
Rappelons à toutes fins utiles à l'ESR français (qui parfois utilise WeTransfer pour du professionnel) qu'il a filesender.renater.fr francetransfert.numerique.gouv.fr/upload et sans doute d'autres services dans les organismes.
15.07.2025 06:07 — 👍 116 🔁 83 💬 9 📌 3
PhD in sociology (CNRS, CSI), post-doc at LISIS (INRAE).
Science studies 🔬 Valorisation, innovation, industry
"Uncultured researcher in computer science, completely banal and mainstream."
affilié à France Points Fixes et à Theorems As A Service
he/him/whatever
https://social.sciences.re/@MonniauxD
https://cv.hal.science/david-monniaux
Language and keyboard stuff at Google + PhD student at Tokyo Institute of Technology.
I like computers and Korean and computers-and-Korean and high school CS education.
Georgia Tech → 연세대학교 → 東京工業大学.
https://theoreticallygoodwithcomputers.com/
Bot. I daily tweet progress towards machine learning and computer vision conference deadlines. Maintained by @chriswolfvision.bsky.social
Professor in Computer Science. Love and hate AI
Optimal Transport Affinicionado
Head of Obelix group
@Irisa
Réseau Stand For Science Paris et région parisienne.
Les sciences sont un bien commun !
#StandUpForScience
Site national : https://standupforscience.fr/
Full professor at University of A Coruña. Member of LyS group, CITIC. Researcher in natural language processing/computational linguistics. http://www.grupolys.org/~cgomezr
Veille et recherche sur les politiques publiques de l'éducation, de l'enseignement supérieur et de la recherche
#ESR #DataESR #VeilleESR
Maître de conférences à l'Université de Strasbourg, laboratoire SAGE.
Membre de la CPESR.
Institut du CNRS spécialisé en écologie et environnement.
Comprendre la biosphère pour agir.
#biodiversité 🦋🌺 #écosystème 🏞️ #préhistoire ⌛️ #océan 🌊
(jolly good) Fellow at the Kempner Institute @kempnerinstitute.bsky.social, incoming assistant professor at UBC Linguistics (and by courtesy CS, Sept 2025). PhD @stanfordnlp.bsky.social with the lovely @jurafsky.bsky.social
isabelpapad.com
Collectif engagé pour une université et une recherche libres, exigeantes, placées au service de l’intérêt général et de l’émancipation — https://rogueesr.fr
Postdoc in ML/NLP at the University of Edinburgh.
Interested in Bottlenecks in Neural Networks; Unargmaxable Outputs.
https://grv.unargmaxable.ai/
Directeur de Recherche en Écologie forestière.
Député NFP de #Marseille
Membre de la Gauche Ecosocialiste et de l’APRÈS.
Membre du groupe écologiste et sociale et de la Commission des affaires sociales
Auteur de "Le capital c'est nous"
Raison, politique et science
Fou d'images, de dessins, de littérature, d'humour et d'échanges dans le respect de tous.
🔴⚫ Maître de conférences en informatique #LicenceIV #openaccess #sécu #privacy #blockchains
Marseillo-Dionysien, patronus capybara, team🧄, óai e libertat
Site: pablo.rauzy.name 🏠
Blog: p4bl0.net 🏴☠️
Médiation: pablockchain.fr 🚫⛓️
Plus: pablo.plus ➕
Prof de SES dans l'Essonne et secrétaire générale du SNES-FSU.
#TeamBadminton quand les blessures (et l'actu Educ, surtout l'actu Educ) me laissent tranquille. Intermède vélo en attendant le retour de la raquette.
Monteuse vidéo, Argent Magique 💸✨, lives éco chez Stupid Economics et lives random sur ma chaîne perso
https://linktr.ee/quemarino