
Want all NeurIPS/ICML/ICLR papers in one single .bib file? Here you go!
🗞️ short blog post: fabian-sp.github.io/posts/2024/1...
📇 bib files: github.com/fabian-sp/ml-bib
Want all NeurIPS/ICML/ICLR papers in one single .bib file? Here you go!
🗞️ short blog post: fabian-sp.github.io/posts/2024/1...
📇 bib files: github.com/fabian-sp/ml-bib

Survey of different Large Language Model Architectures: Trends, Benchmarks, and Challenges
Presents a survey on LLM architectures that systematically categorizes auto-encoding, auto-regressive and encoder-decoder models.
📝 arxiv.org/abs/2412.03220

🚨 New preprint out!
We build **scalar** time series embeddings of temporal networks !
The key enabling insight : the relevant feature of each network snapshot... is just its distance to every other snapshot!
Work w/ FJ Marín, N. Masuda, L. Arola-Fernández
arxiv.org/abs/2412.02715

Proud to announce our NeurIPS spotlight, which was in the works for over a year now :) We dig into why decomposing aleatoric and epistemic uncertainty is hard, and what this means for the future of uncertainty quantification.
📖 arxiv.org/abs/2402.19460 🧵1/10
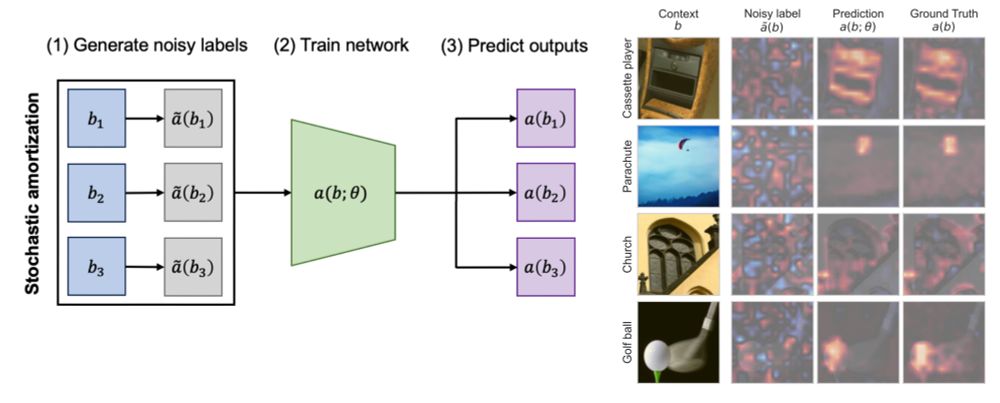
If you use SHAP, LIME or Data Shapley, you might be interested in our new #neurips2024 paper. We introduce stochastic amortization to speed up feature + data attribution by 10x-100x 🚀 #XML
Surprisingly we can "learn to attribute" cheaply from noisy explanations! arxiv.org/abs/2401.15866

Samples y | x from Treeffuser vs. true densities, for multiple values of x under three different scenarios. Treeffuser captures arbitrarily complex conditional distributions that vary with x.
I am very excited to share our new Neurips 2024 paper + package, Treeffuser! 🌳 We combine gradient-boosted trees with diffusion models for fast, flexible probabilistic predictions and well-calibrated uncertainty.
paper: arxiv.org/abs/2406.07658
repo: github.com/blei-lab/tre...
🧵(1/8)

TIL from the Hard Fork podcast that the transformer, the core of modern AI including LLMs, was inspired by the aliens in Arrival. That’s wild—and yet another reason to watch Arrival, easily one of the best films of the last decade. Great podcast, great movie!
01.12.2024 06:47 — 👍 31 🔁 3 💬 1 📌 2
Transcript of Hard Fork ep 111: Yeah. And I could talk for an hour about transformers and why they are so important. But I think it's important to say that they were inspired by the alien language in the film Arrival, which had just recently come out. And a group of researchers at Google, one researcher in particular, who was part of that original team, was inspired by watching Arrival and seeing that the aliens in the movie had this language which represented entire sentences with a single symbol. And they thought, hey, what if we did that inside of a neural network? So rather than processing all of the inputs that you would give to one of these systems one word at a time, you could have this thing called an attention mechanism, which paid attention to all of it simultaneously. That would allow you to process much more information much faster. And that insight sparked the creation of the transformer, which led to all the stuff we see in Al today.
Did you know that attention across the whole input span was inspired by the time-negating alien language in Arrival? Crazy anecdote from the latest Hard Fork podcast (by @kevinroose.com and @caseynewton.bsky.social). HT nwbrownboi on Threads for the lead.
01.12.2024 14:50 — 👍 247 🔁 53 💬 19 📌 17Did you do bagging in addition to TabM ie fit five of these?
27.11.2024 11:31 — 👍 0 🔁 0 💬 1 📌 0I did a small test with TabM-mini and 5-fold bagging, only default parameters with numerical embeddings. It seems that it's roughly comparable with RealMLP. But then maybe RealMLP can benefit more from additional ensembling or the two could be combined. A fair comparison with ensembling is hard.
26.11.2024 14:13 — 👍 2 🔁 1 💬 1 📌 0
PyTabKit 1.1 is out!
- Includes TabM and provides a scikit-learn interface
- some baseline NN parameter names are renamed (removed double-underscores)
- other small changes, see the readme.
github.com/dholzmueller...
Bluesky really is the new #rstats twitter because we have the first base R vs tidyverse flame war 🤣
14.11.2024 17:18 — 👍 577 🔁 68 💬 28 📌 12With a message like that I just activate
14.11.2024 09:54 — 👍 2 🔁 0 💬 1 📌 0Welcome!
07.08.2024 08:26 — 👍 0 🔁 0 💬 0 📌 0Going to try to start posting more on here given the increasingly suffocating toxicity of the other place 👋
07.08.2024 07:13 — 👍 1820 🔁 159 💬 111 📌 13
When home heating prices are lower, fewer people die each winter, particularly in high-poverty communities. That's the punchline of my paper with Janjala Chirakijja and Pinchuan Ong on heating prices and mortality in the US, just published in the Economic Journal. 📉📈 academic.oup.com/ej/advance-a...
07.12.2023 18:35 — 👍 194 🔁 84 💬 2 📌 7
“Computer Age Statistical Inference” by Efron and Hastie is great for learning the connections among all these (though not much on deep learning specifically). And it’s free! Can’t recommend this book highly enough:
hastie.su.domains/CASI_files/P...