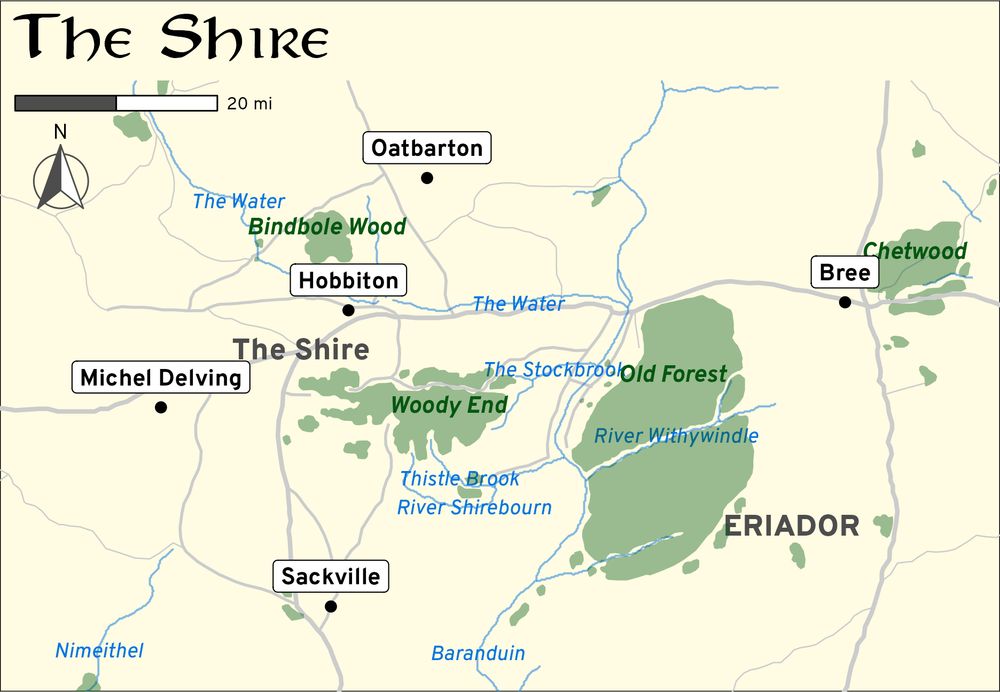
Map of the Shire with forests and rivers and village names
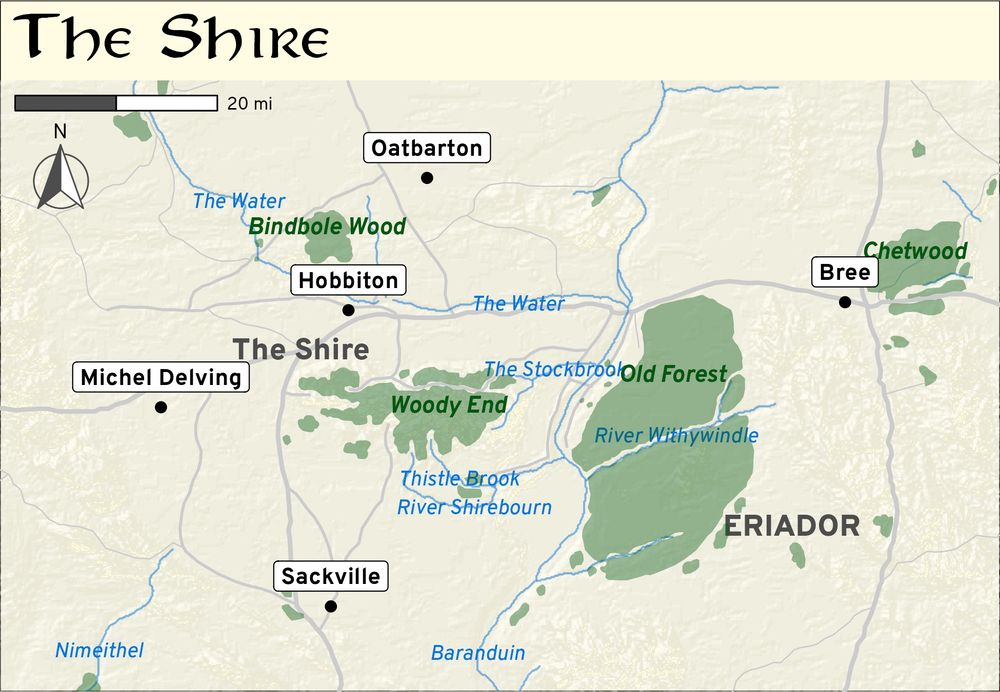
Map of the Shire with forests and rivers and village names, but now with rasterized elevation
These work way better in 2D! Here's a before and after
04.08.2025 05:06 — 👍 0 🔁 0 💬 0 📌 0
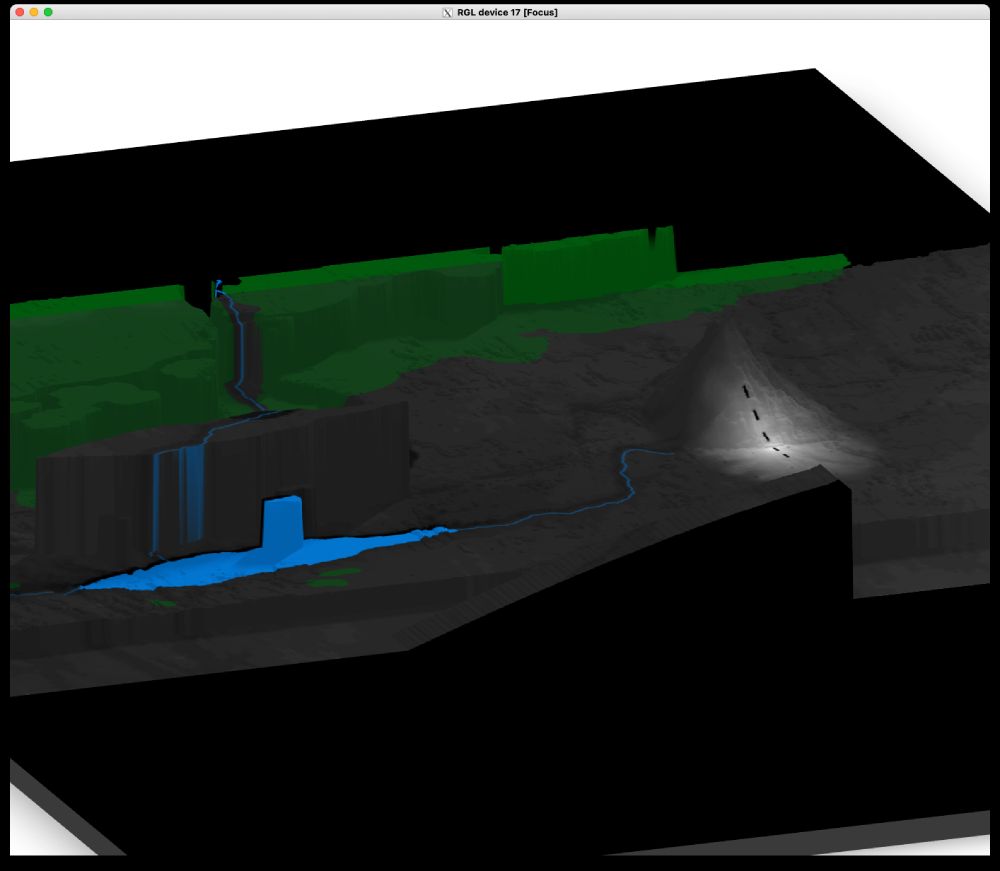
Mt Doom from The Hobbit
Another example of the jaggedness—Erebor looks fantastic on the right here, but Esgaroth/Lake Town looks like it's on a huge plateau on the shores of Long Lake (and same with Mirkwood in the back—weird huge cliffs)
04.08.2025 02:11 — 👍 0 🔁 0 💬 0 📌 0
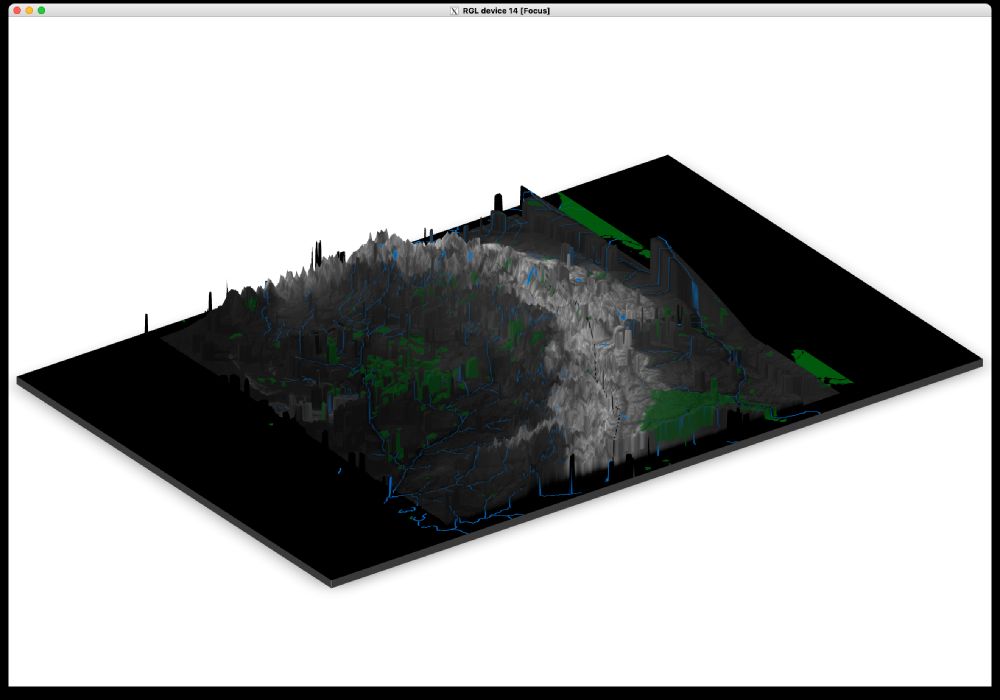
3D render of Rivendell
working on a blog post about it right now haha
here's a very rough Rivendell! The DEM data is really jagged, so I'm working on smoothing it out
04.08.2025 01:59 — 👍 1 🔁 0 💬 2 📌 0
YouTube video by Electric Cowboys
Normal Car Horn vs. Cybertruck Horn #cars #automobile #tesla
just heard a cybertruck honk its horn for the first time IRL, and holy crap it's a perfect auditory counterpart to the visual hideousness of that stupid car www.youtube.com/watch?v=BOKf...
03.08.2025 23:27 — 👍 11 🔁 0 💬 2 📌 0
did she clean tho?
03.08.2025 14:57 — 👍 5 🔁 0 💬 0 📌 0
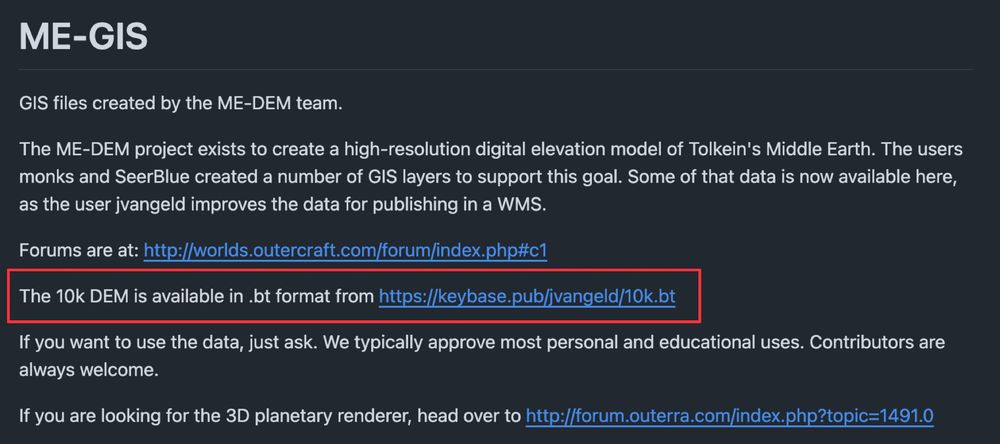
ME-GIS
GIS files created by the ME-DEM team.
The ME-DEM project exists to create a high-resolution digital elevation model of Tolkein's Middle Earth. The users monks and SeerBlue created a number of GIS layers to support this goal. Some of that data is now available here, as the user jvangeld improves the data for publishing in a WMS.
Forums are at: http://worlds.outercraft.com/forum/index.php#c1
The 10k DEM is available in .bt format from https://keybase.pub/jvangeld/10k.bt
If you want to use the data, just ask. We typically approve most personal and educational uses. Contributors are always welcome.
If you are looking for the 3D planetary renderer, head over to http://forum.outerra.com/index.php?topic=1491.0
They used to exist! But that link is dead now :(
03.08.2025 03:42 — 👍 2 🔁 0 💬 1 📌 0
5 of 5 stars to Eleanor Roosevelt, Vol 1: 1884-1933 by Blanche Wiesen Cook www.goodreads.com/book/show/88...
02.08.2025 18:12 — 👍 6 🔁 2 💬 0 📌 0
Firing the BLS Commissioner — the wonk in charge of the statisticians who track economic reality — is an authoritarian four alarm fire.
It will also backfire: You can't bend economic reality, but you can break the trust of markets. And biased data yields worse policy.
01.08.2025 20:54 — 👍 10260 🔁 3293 💬 300 📌 159

Orlando Bloom Spotted At Dinner With Angela Merkel
Orlando Bloom Spotted At Dinner With Angela Merkel theonion.com/orlando...
01.08.2025 15:00 — 👍 3103 🔁 276 💬 67 📌 45
And she’s gone!
01.08.2025 00:04 — 👍 48 🔁 0 💬 1 📌 0
Yep! My wife and I both went there—I did undergrad and an MPA there. My mother-in-law is library faculty there, and I did a two-year visiting gig there before coming to GSU. We have deep BYU roots :)
31.07.2025 14:34 — 👍 5 🔁 0 💬 1 📌 0
It'll be weird going down to n-1 kids at home, a number we haven't been at since 2021. The other kids have been like vultures claiming stuff and space 😂
31.07.2025 14:33 — 👍 9 🔁 0 💬 0 📌 0
without doing the math to figure out that *we are that niche*. That episode has actually been helpful for the 3-yo processing the change, so thanks PBS
31.07.2025 14:28 — 👍 17 🔁 0 💬 1 📌 0

Prince Wednesday, Prince Tuesday, and Daniel Tiger
Also, IT'S SO WEIRD to be at a stage of life where kids are moving away, but also while we still have a 3-year-old. There's a Daniel Tiger episode where Prince Tuesday moves to college and the little kids are sad and I've always thought "wow, that's a wildly niche situation for their audience"
31.07.2025 14:28 — 👍 14 🔁 0 💬 1 📌 0
ahhhhhhh our oldest is moving out today—she's off to BYU!
31.07.2025 14:28 — 👍 55 🔁 1 💬 9 📌 1
BarriePalmerSpirling_TrustMeBro.pdf
A+ preprint PDF name too arthurspirling.org/documents/Ba...
31.07.2025 01:04 — 👍 11 🔁 3 💬 0 📌 0
Basically they do a ton of coding tasks with humans and different LLMs over time to show that LLM-based coding has all the worst characteristics of human-based approaches (i.e. exact replication impossible + high fragility) & have advice for attempting replicability with LLMs
31.07.2025 01:02 — 👍 13 🔁 3 💬 1 📌 0

These jobs range from coding the ideology of manifestos to identifying types of protest events to detecting certain political valences in speeches. The idea is to precisely calibrate exactly
how replicable one can expect machines to be in practice, and where (what types of tasks) we can expect better (lower variance, more replication) or worse performance. The human
workers provide a baseline comparison in terms of replicability. At a high level, the news is bad: while it is true that LMs can be (very) accurate relative to a gold standard, they also show considerable variance over time. And this is to say nothing of cases where they simply will not run at all, and thus fail the most basic requirement (see, e.g., Benureau and Rougier, 2018) of computational replication. Contrary to popular belief, the problems do not go away even if one sets "temperatures" (or equivalent tunings) to zero; indeed, this induces new but unpredictable problems with replication. Unsurprisingly, this variance affects the substantive answers we get downstream-that is, in subsequent analysis in which the labels
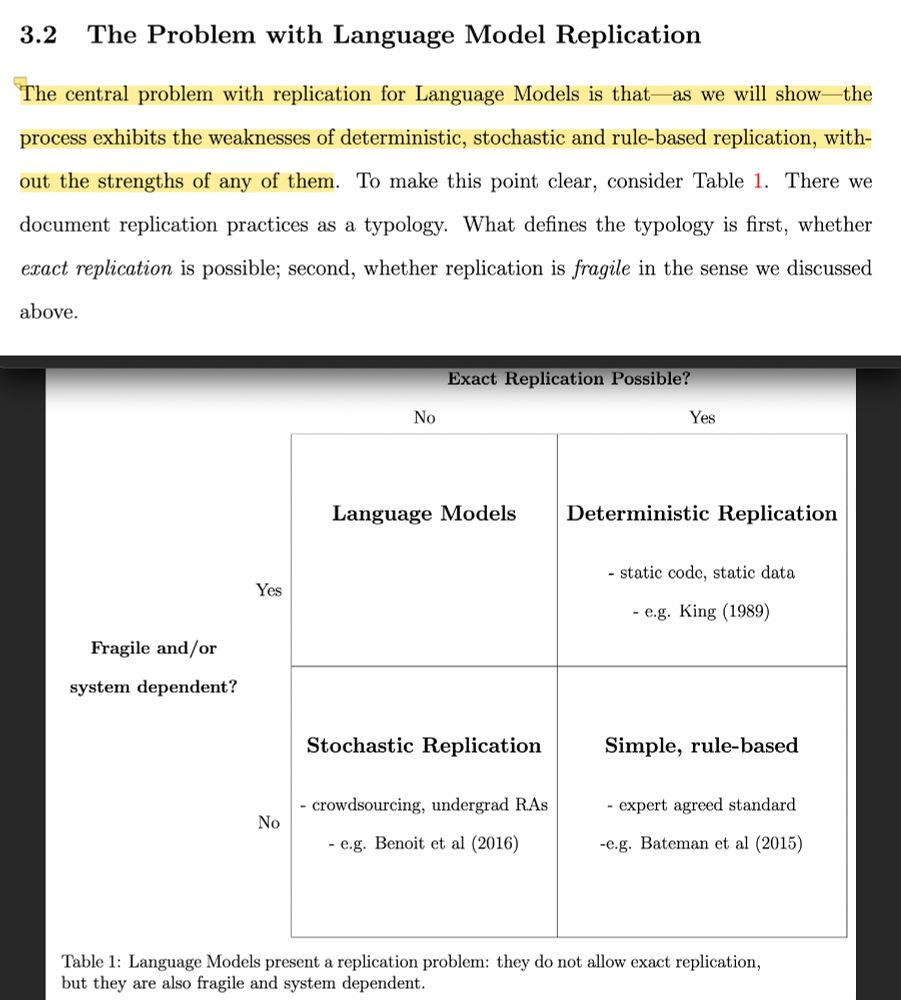
3.2 The Problem with Language Model Replication
The central problem with replication for Language Models is that as we will show-the process exhibits the weaknesses of deterministic, stochastic and rule-based replication, without the strengths of any of them. To make this point clear, consider Table 1. There we document replication practices as a typology. What defines the typology is first, whether exact replication is possible; second, whether replication is fragile in the sense we discussed above.
With a 2x2 table showing that LLms are not exactly replicable and are fragile

Full results for each outcome and run are displayed in Figures 8 to 10 in SI C. We also give descriptions of what we found. For now, we summarize our main observations:
1. For the manifestos, the crowdworkers perform very well (by LM standards) and their variance is generally lower than the LMs.
2. For the protests crowdworkers are less accurate than the LMs, but very consistent in their performance.
3. Crowdworkers struggle in predictable ways: for example, they are least accurate when manifestos should have 'extreme' codings (far left /far right).
4. LMs struggle in unpredictable ways: for example, GPT made errors on more moderate (liberal manifestos, but it is hard to know why.
5. Comparing across LMs, errors and performances appears to be idiosyncratic: for example, Llama has recall on some tasks on a par with GPT but generally much lower
variance.
6. Open LMs have the best replication performance, at least in terms of low variance.
For instance, on the static tasks, Llama has practically zero variance in its coding performance.

3. Consider open models that allow offline versioning. We found that, uniquely, our open-weights implementations were replicable to a high standard if that standard is low variance. That is, if the goal is something approaching the Deterministic 'code and data' replication vision above, then local, versioned models are the way to go. These may not deliver top of the line performance (e.g. accuracy) but should be checked as a first resort. We acknowledge that an open LM may not be "transparent" in the sense that it is "easy" to understand how it produces predictions even if one has the weights. But it is obviously a boon to replication insofar as being able to verify that
the original researcher did indeed see the results they reported. What is more, recent research into LM interpretability points the way toward more model understanding and control but only if weights are accessible (Cunningham et al., 2023).
Finally got to read this new paper by @cbarrie.bsky.social & @lexipalmer.bsky.social & Arthur Spirling on the lack of replicability in LLM-based research and polisci and it's so good and concise and well-reasoned! arthurspirling.org/documents/Ba...
31.07.2025 01:02 — 👍 38 🔁 10 💬 2 📌 2
BarriePalmerSpirling_TrustMeBro.pdf
A+ preprint PDF name too arthurspirling.org/documents/Ba...
31.07.2025 01:04 — 👍 11 🔁 3 💬 0 📌 0
Basically they do a ton of coding tasks with humans and different LLMs over time to show that LLM-based coding has all the worst characteristics of human-based approaches (i.e. exact replication impossible + high fragility) & have advice for attempting replicability with LLMs
31.07.2025 01:02 — 👍 13 🔁 3 💬 1 📌 0
These jobs range from coding the ideology of manifestos to identifying types of protest events to detecting certain political valences in speeches. The idea is to precisely calibrate exactly
how replicable one can expect machines to be in practice, and where (what types of tasks) we can expect better (lower variance, more replication) or worse performance. The human
workers provide a baseline comparison in terms of replicability. At a high level, the news is bad: while it is true that LMs can be (very) accurate relative to a gold standard, they also show considerable variance over time. And this is to say nothing of cases where they simply will not run at all, and thus fail the most basic requirement (see, e.g., Benureau and Rougier, 2018) of computational replication. Contrary to popular belief, the problems do not go away even if one sets "temperatures" (or equivalent tunings) to zero; indeed, this induces new but unpredictable problems with replication. Unsurprisingly, this variance affects the substantive answers we get downstream-that is, in subsequent analysis in which the labels
3.2 The Problem with Language Model Replication
The central problem with replication for Language Models is that as we will show-the process exhibits the weaknesses of deterministic, stochastic and rule-based replication, without the strengths of any of them. To make this point clear, consider Table 1. There we document replication practices as a typology. What defines the typology is first, whether exact replication is possible; second, whether replication is fragile in the sense we discussed above.
With a 2x2 table showing that LLms are not exactly replicable and are fragile
Full results for each outcome and run are displayed in Figures 8 to 10 in SI C. We also give descriptions of what we found. For now, we summarize our main observations:
1. For the manifestos, the crowdworkers perform very well (by LM standards) and their variance is generally lower than the LMs.
2. For the protests crowdworkers are less accurate than the LMs, but very consistent in their performance.
3. Crowdworkers struggle in predictable ways: for example, they are least accurate when manifestos should have 'extreme' codings (far left /far right).
4. LMs struggle in unpredictable ways: for example, GPT made errors on more moderate (liberal manifestos, but it is hard to know why.
5. Comparing across LMs, errors and performances appears to be idiosyncratic: for example, Llama has recall on some tasks on a par with GPT but generally much lower
variance.
6. Open LMs have the best replication performance, at least in terms of low variance.
For instance, on the static tasks, Llama has practically zero variance in its coding performance.
3. Consider open models that allow offline versioning. We found that, uniquely, our open-weights implementations were replicable to a high standard if that standard is low variance. That is, if the goal is something approaching the Deterministic 'code and data' replication vision above, then local, versioned models are the way to go. These may not deliver top of the line performance (e.g. accuracy) but should be checked as a first resort. We acknowledge that an open LM may not be "transparent" in the sense that it is "easy" to understand how it produces predictions even if one has the weights. But it is obviously a boon to replication insofar as being able to verify that
the original researcher did indeed see the results they reported. What is more, recent research into LM interpretability points the way toward more model understanding and control but only if weights are accessible (Cunningham et al., 2023).
Finally got to read this new paper by @cbarrie.bsky.social & @lexipalmer.bsky.social & Arthur Spirling on the lack of replicability in LLM-based research and polisci and it's so good and concise and well-reasoned! arthurspirling.org/documents/Ba...
31.07.2025 01:02 — 👍 38 🔁 10 💬 2 📌 2
yes (<ducks from cringe police>)
31.07.2025 00:10 — 👍 1 🔁 0 💬 1 📌 0
If Gandalf didn’t want Frodo to put on the ring he shouldn’t have called it “quite cool” when he gave it to him
31.07.2023 14:30 — 👍 1102 🔁 241 💬 13 📌 7
wooof no 🤮
30.07.2025 17:03 — 👍 9 🔁 0 💬 0 📌 0
HWÆT! Hæle min sun
30.07.2025 15:46 — 👍 3 🔁 0 💬 0 📌 0
List of languages like
Dzongkha
Eastern frisian
Efik
Egyptian (ancient)
Ekajuk
Elamite
English
English, middle (1100-1500)
English, old (ca.450-1100)
Erzya
Esperanto
Estonian
Ewe
Ewondo
Checking in a kid at urgent care and have to choose a primary language and I’m amazed at the list they’re using. Almost chose English, old or Egyptian (ancient)
30.07.2025 15:18 — 👍 53 🔁 4 💬 12 📌 2
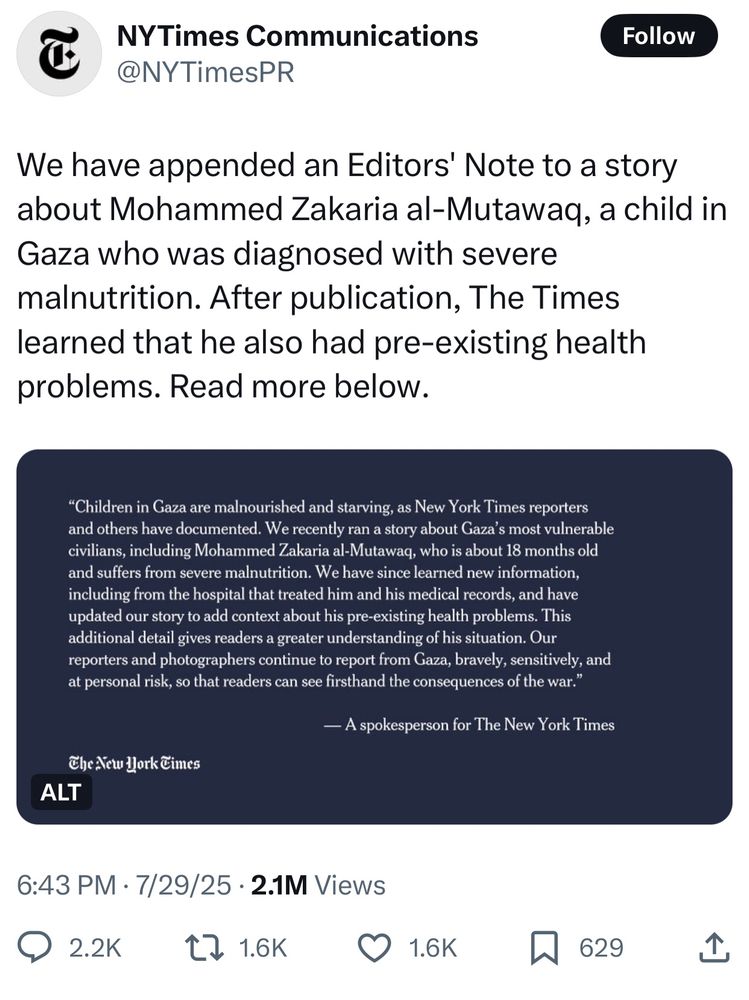
We have appended an Editors' Note to a story about Mohammed Zakaria al-Mutawaq, a child in Gaza who was diagnosed with severe malnutrition. After publication, The Times learned that he also had pre-existing health problems. Read more below.
Children in Gaza are malnourished and starving, as New York Times reporters and others have documented. We recently ran a story about Gaza’s most vulnerable civilians, including Mohammed Zakaria al-Mutawaq, who is about 18 months old and suffers from severe malnutrition. We have since learned new information, including from the hospital that treated him and his medical records, and have updated our story to add context about his pre-existing health problems. This additional detail gives readers a greater understanding of his situation. Our reporters and photographers continue to report from Gaza, bravely, sensitively, and at personal risk, so that readers can see firsthand the consequences of the war.
OMG
30.07.2025 01:43 — 👍 1384 🔁 220 💬 186 📌 458
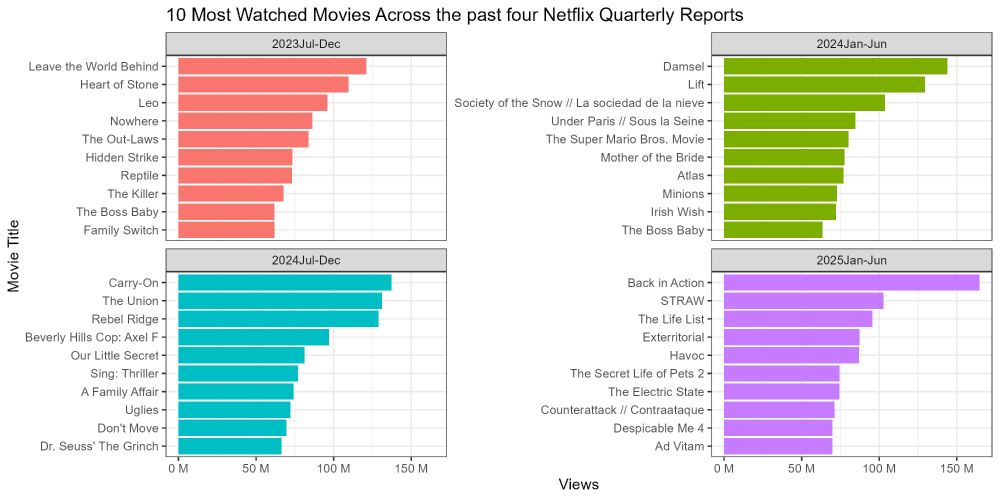
Here is #TidyTuesday Number Two for my Data Visualization Class!
29.07.2025 02:06 — 👍 6 🔁 2 💬 2 📌 0
THE SINGULARITY, streaming now.
Composer - The Lord of the Rings: The Rings of Power, Outlander, God of War, Walking Dead, Godzilla: KOTM, Battlestar Galactica
Just to let you know, there are many, many recipes waiting for you on www.nigella.com
tag or dm for submissions
support: https://www.patreon.com/TheLouvreofBluesky
do not fight in my replies
journalist / co-founder @404media.co
signal (for sensitive comms ONLY thanks): sam.404
ex-academic, co-founder RLadiesSydney, developer #RYouWithMe, sharer of #rstats learning https://jenrichmond.github.io/
Developer Relations @posit.co
Professor and Chair of WashU Chemistry. I’m a researcher, but I’m a #MentorFirst. Author of Labwork to Leadership.
Professor at the University of Virginia School of Law; Vice President of the Cyber Civil Rights Initiative; #MacFellow; Author of The Fight for Privacy: Protecting Dignity, Identity, and Love in the Digital Age (2022) and Hate Crimes in Cyberspace (2014) 🍋
NYC mom with opinions: UN peacebuilding, parenthood, sportsball, politics, educational equity, feminism. Probably thinking about S̶w̶e̶e̶n̶e̶y̶ ̶T̶o̶d̶d̶ Sunset Blvd (jk it’s always Sweeney Todd). Personal views. She/her.
The Reveal podcast is produced by the nation's first investigative journalism nonprofit, the Center for Investigative Reporting, and PRX.
🎧 http://revealnews.org
📧 http://revealnews.org/newsletter
💲 http://bit.ly/reveal-join
Trinity College Dublin’s Artificial Intelligence Accountability Lab (https://aial.ie/) is founded & led by Dr Abeba Birhane. The lab studies AI technologies & their downstream societal impact with the aim of fostering a greater ecology of AI accountability
We're increasing the cost of lies that undermine democracy ☀️
Read our analysis: https://americansunlight.substack.com/
Join our Patreon: https://www.patreon.com/americansunlightproject
Support our work: https://www.americansunlight.org/donate
☀️ CEO, @americansunlight.org
🙅🏻♀️ Author, disinformation expert, advocate for targets of online abuse.
😆 Tucker Carlson once called me a “highly self confident young woman” and meant it as an insult
Politics @ TPM // Previously @ Teen Vogue
📊✨️ Data Visualization | #rstats | #Episky
LinkedIn: linkedin.com/in/darakhshan-nehal-b38747154/
GitHub: github.com/darakhshannehal
📊 data science educator @ UCSB | 💜 R-Ladies Santa Barbara co-organizer | 🥾 lover of a good sunrise hike
https://samanthacsik.github.io/
The Knight First Amendment Institute at Columbia University defends the freedoms of speech & the press in the digital age through strategic litigation, research, policy advocacy, and public education.
https://knightcolumbia.org/
Researcher, Data Scientist, R-Ladies Buenos Aires Organizer 💜.
Mother of cats 🐈🐲 She|her 🌈
#rstats #rladies
Assistant professor @unileiden.bsky.social | Interest representation | Public policy | Political behaviour | Comparative politics and EU | Methods | Mom of 2
We come from the future. By @gizmodo.com. Sign up for our newsletter if you prefer http://gizmodo.com/newsletter