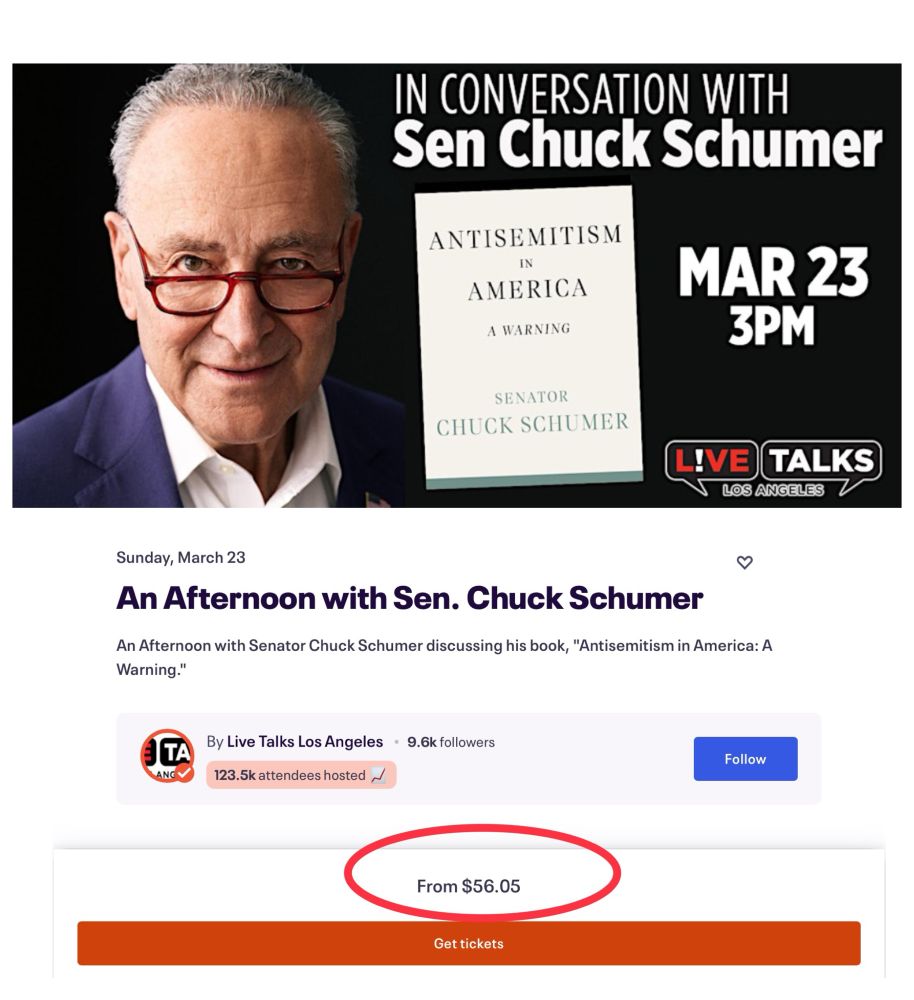
It gets worse. Schumer isn’t just going on a book tour—he’s charging for tickets.
Absolute insanity. While Americans are scared and in crisis mode, he’s basically saying, let them eat cake.
@schumer.senate.gov Step Down.

@jamesneno.bsky.social
The horror
It gets worse. Schumer isn’t just going on a book tour—he’s charging for tickets.
Absolute insanity. While Americans are scared and in crisis mode, he’s basically saying, let them eat cake.
@schumer.senate.gov Step Down.

A set of three scatter plots showing the relationship between **average thinking time (tokens)** on the x-axis and **accuracy (%)** on the y-axis for three different reasoning-intensive tasks: **Mathematical Problem Solving (MATH500), Competition Math (AIME24), and PhD-Level Science Questions (GPQA Diamond).** Each scatter plot contains blue data points indicating the performance of the **s1-32B** model under different test-time compute conditions. - **First plot (Mathematical Problem Solving - MATH500):** - The accuracy starts around **65%** and increases as thinking time increases from **512 tokens to 2048 tokens.** - The final accuracy approaches **95%.** - **Second plot (Competition Math - AIME24):** - The accuracy starts at nearly **0%** for the lowest thinking time **(512 tokens)** and gradually improves as thinking time increases. - At **8192 tokens**, accuracy reaches approximately **40%.** - **Third plot (PhD-Level Science Questions - GPQA Diamond):** - The accuracy starts around **40%** for **512 tokens** and increases steadily. - At **4096 tokens**, accuracy exceeds **60%.** Below the figure, a caption reads: **"Figure 1. Test-time scaling with s1-32B. We benchmark s1-32B on reasoning-intensive tasks and vary test-time compute."**
s1: Simple inference-time scaling
This is a simple small-scale replication of inference-time scaling
It was cheap: 16xH100 for 26 minutes (so what, ~$6?)
It replicates inference-time scaling using SFT only (no RL)
Extremely data frugal: 1000 samples
arxiv.org/abs/2501.19393
Two things David Lynch has given us, and continues to give us, after his passing:
1. The realization that meditation can be a path to peace, happiness, and creativity.
2. An artistic representation of the surreal and violent undercurrents of modern American life.
-quoting Threads' michael.tucker_
i’ve said this a few times — i think US export controls on China **CAUSED** Chinese labs to catch up in AI
recent Chinese innovations were:
1. unique in that they avoided cost
2. the right way
US academic dialog was dominated by more expensive and complex methods that wouldn’t have worked
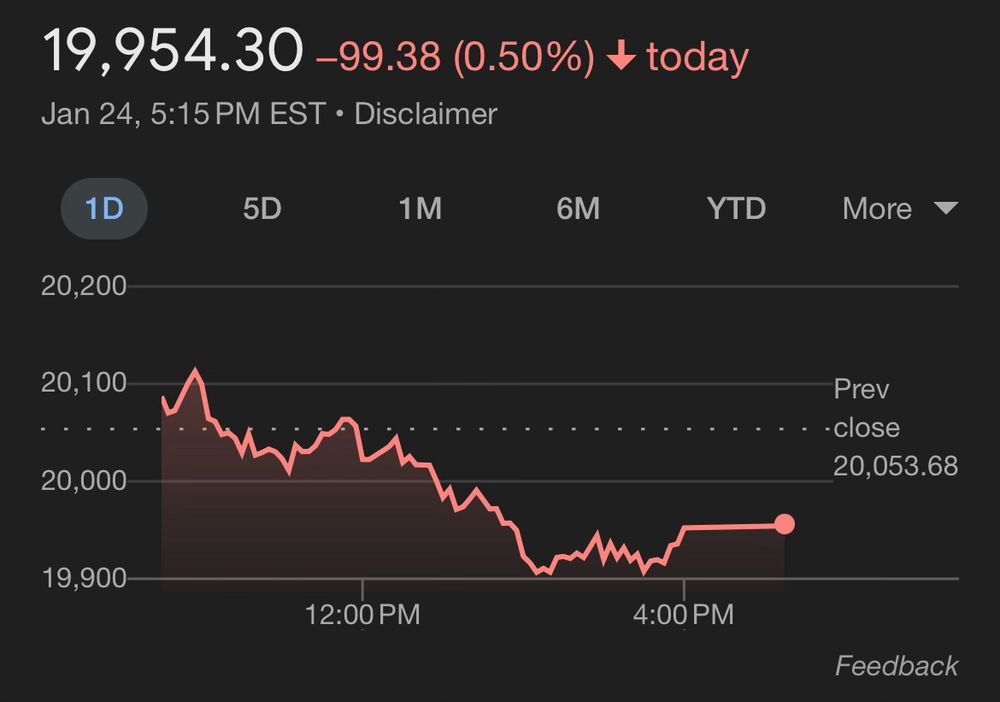
The chart displays the performance of a financial index or stock on January 24. Here’s a summary: • Closing Value: 19,954.30 • Change: -99.38 points (-0.50%) compared to the previous close of 20,053.68. • Time: Data captured at 5:15 PM EST. Daily Performance: • The index opened above 20,000 and experienced fluctuations throughout the day. • A decline was observed, reaching below 19,900 before stabilizing slightly above 19,950 by the close. The red downward arrow and negative percentage indicate a bearish trend for the day.
NASDAQ took a hit today, on fears that DeepSeek’s R1 represents flailing US tech industry
27.01.2025 12:59 — 👍 9 🔁 1 💬 4 📌 1
Stephen Uzzell: Franceska Mann, the Polish ballerina, who, while being led to the gas chamber, stole a Nazi guard’s gun, shot him dead, and started a female-led riot that gave hope to all of the prisoners of Auschwitz in the face of certain death. @lacentrist.bsky.social
26.01.2025 19:38 — 👍 10 🔁 3 💬 1 📌 0despite the seductiveness of the "distealing" story, we're very quickly building evidence that, no, deepseek did not distill from openai models
even today, mere *days* after the R1 release, there's already reproductions. combined with the incoming huggingface repro, it seems like R1 is legit

huggingface is doing a fully open source replication of R1 github.com/huggingface/...
25.01.2025 14:31 — 👍 123 🔁 28 💬 3 📌 4Yeah and he’s right.
24.01.2025 23:54 — 👍 0 🔁 0 💬 0 📌 0

Happy MLK Day.
20.01.2025 21:09 — 👍 59218 🔁 8650 💬 417 📌 206learning = extrapolating answers from data
emergence = extrapolating questions from the data
emergence is basically “higher order learning”. i like to argue that LLMs aren’t machine learning because they go this extra step

January 2025 as a meme
17.01.2025 12:56 — 👍 15072 🔁 2111 💬 167 📌 77If you’re planning on watching any Lynch, my advice is: don’t watch any analysis videos, don’t think about what stuff is “supposed” to mean, just get your own unique experience from it!!
I think people have become far too concerned with the “correct” interpretations of media. Just experience it!!!
Sorry to hear about David Lynch. I worked beside him (same studio) while he was making BLUE VELVET. He answered my questions about his work with grace and honesty. I especially enjoyed his deeply existential comic strip, The Angriest Dog in the World.”
16.01.2025 23:02 — 👍 42570 🔁 2461 💬 383 📌 71
If DeepSeek could, they’d happily train on more GPUs concurrently. Training one model for multiple months is extremely risky in allocating an organization’s most valuable assets — the GPUs. According to SemiAnalysis ($), one of the “failures” of OpenAI’s Orion was that it needed so much compute that it took over 3 months to train. This is a situation OpenAI explicitly wants to avoid — it’s better for them to iterate quickly on new models like o3.
fascinating insight from @natolambert.bsky.social
the raw duration of training, regardless of parallelization, is a huge risk, bc the cluster is saturated doing only one thing
so while you *could* build bigger models by training longer, that’s not feasible in practice due to risk
WSJ confirms that the LA fires are now the costliest in U.S. history, with economic damages currently estimated to be at least $50 billion.
09.01.2025 17:09 — 👍 262 🔁 61 💬 13 📌 11Power shell syntax is too wordy.
05.01.2025 22:43 — 👍 0 🔁 0 💬 1 📌 0I think you are on to something here.
It aligns with how I’ve gotten the most value out of LLMs.
i have a blog post almost ready to go that has a different take — if the nature of software changes such that you only have small short-lived projects with small scale, then there’s little to no need for software engineers and yes it can be mostly automated
30.12.2024 17:25 — 👍 4 🔁 1 💬 2 📌 0There is no good music streaming platform but spotify is absolutely the most evil one and also has the distinction of sounding the shittiest
21.12.2024 06:44 — 👍 1304 🔁 207 💬 49 📌 9Everything is so incestuous in this space. Companies ‘stealing’ each others top talent, models being trained on other companies models, data being used from everywhere, and the investment you mentioned above.
This has to mean something in the bigger picture.
This is a terrific idea.
18.12.2024 02:45 — 👍 0 🔁 0 💬 0 📌 0we should have a tool like NotebookLM that writes a blog post for an academic paper. Yes, every paper should have a blog post, and if it doesn’t, i’ll just generate it
17.12.2024 13:34 — 👍 9 🔁 2 💬 2 📌 0I like your music. Welcome!
15.12.2024 23:07 — 👍 0 🔁 0 💬 0 📌 0Lies!
12.12.2024 23:32 — 👍 1 🔁 0 💬 0 📌 0Apocalypse Now
Marlin Brando.
Attention is all you need from 2017.
08.12.2024 20:12 — 👍 0 🔁 0 💬 0 📌 0
















