
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵

@akshitab.bsky.social
Research Engineer at Ai2 https://akshitab.github.io/
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵
Such an interesting paper!
31.10.2025 18:41 — 👍 2 🔁 0 💬 0 📌 0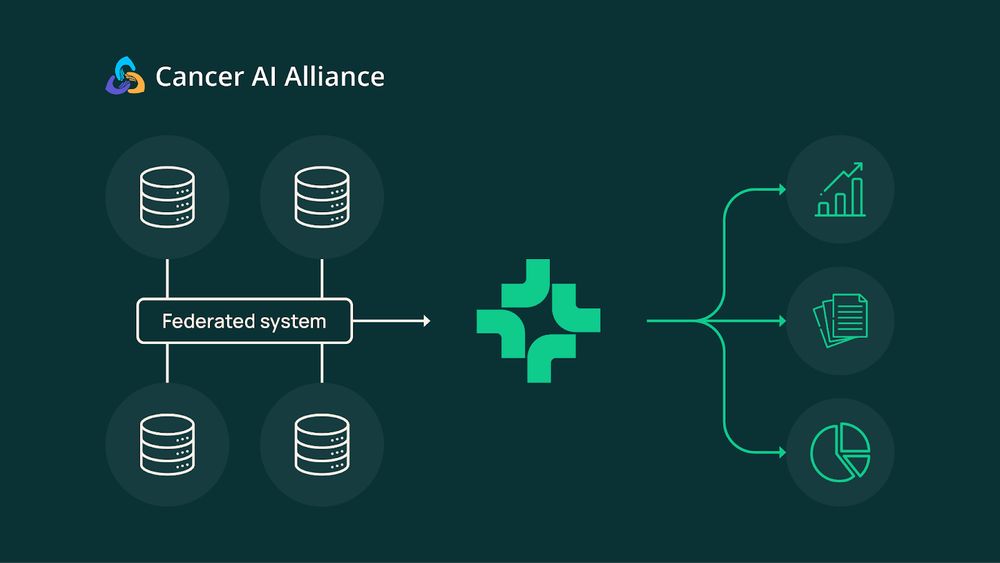
The Cancer AI Alliance (CAIA) is already prototyping Asta DataVoyager in a federated, multi-institution setup for cancer studies—keeping clinical data local and secure.
Read more about CAIA here: buff.ly/ACpxLNT
Introducing FlexOlmo, a new paradigm for language model training that enables the co-development of AI through data collaboration. 🧵
09.07.2025 16:02 — 👍 15 🔁 6 💬 1 📌 2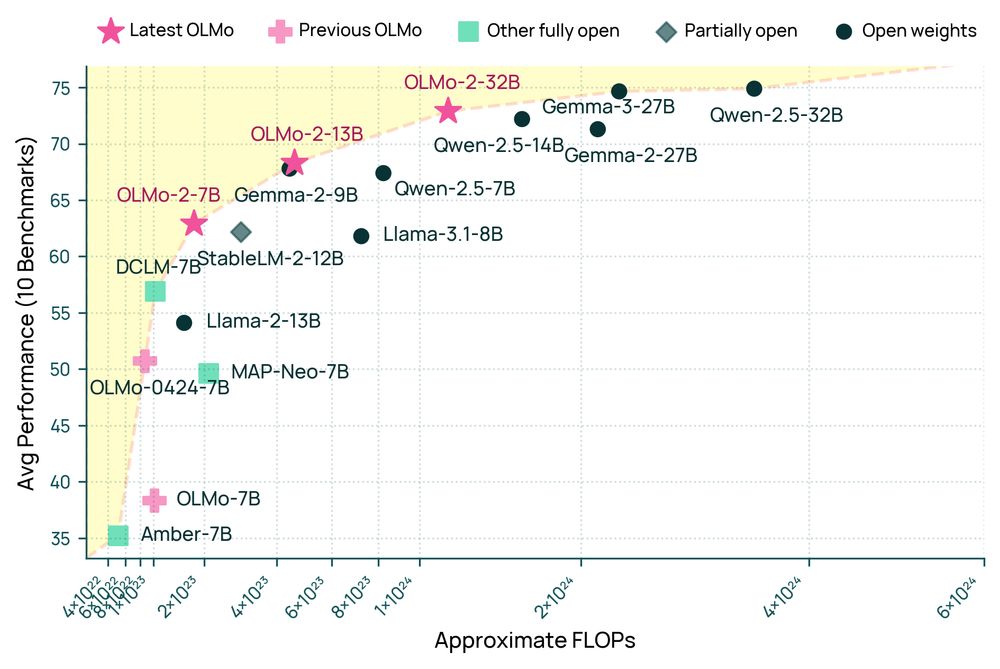
Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks.
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
I caught myself wanting to respond similarly to Claude and then told myself that it will be wasteful inference. But now I also mentally thank it each time because what if I lose that instinct with humans.. I'm already impatient with smart speakers.
12.02.2025 20:00 — 👍 3 🔁 0 💬 0 📌 0They made me do video 😬 but for a good reason!
We are launching an iOS app–it runs OLMoE locally 📱 We're gonna see more on-device AI in 2025, and wanted to offer a simple way to prototype with it
App: apps.apple.com/us/app/ai2-o...
Code: github.com/allenai/OLMo...
Blog: allenai.org/blog/olmoe-app

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
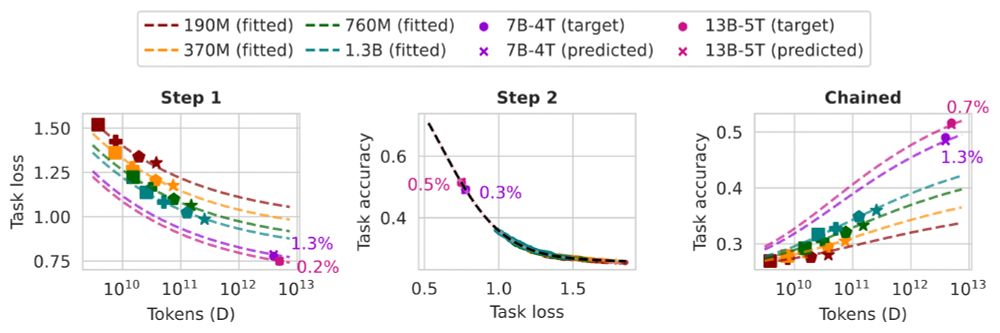
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
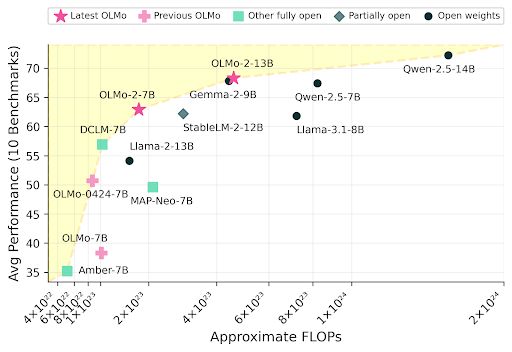
The OLMo 2 models sit at the Pareto frontier of training FLOPs vs model average performance.
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
26.11.2024 20:51 — 👍 151 🔁 36 💬 5 📌 12I use GoodNotes
26.11.2024 18:53 — 👍 4 🔁 0 💬 0 📌 0🙋♀️
22.11.2024 01:24 — 👍 1 🔁 0 💬 0 📌 0
release day release day 🥳 OLMo 1b +7b out today and 65b soon...
OLMo accelerates the study of LMs. We release *everything*, from toolkit for creating data (Dolma) to train/inf code
blog blog.allenai.org/olmo-open-la...
olmo paper allenai.org/olmo/olmo-pa...
dolma paper allenai.org/olmo/dolma-p...
👋
09.01.2024 03:42 — 👍 2 🔁 0 💬 0 📌 0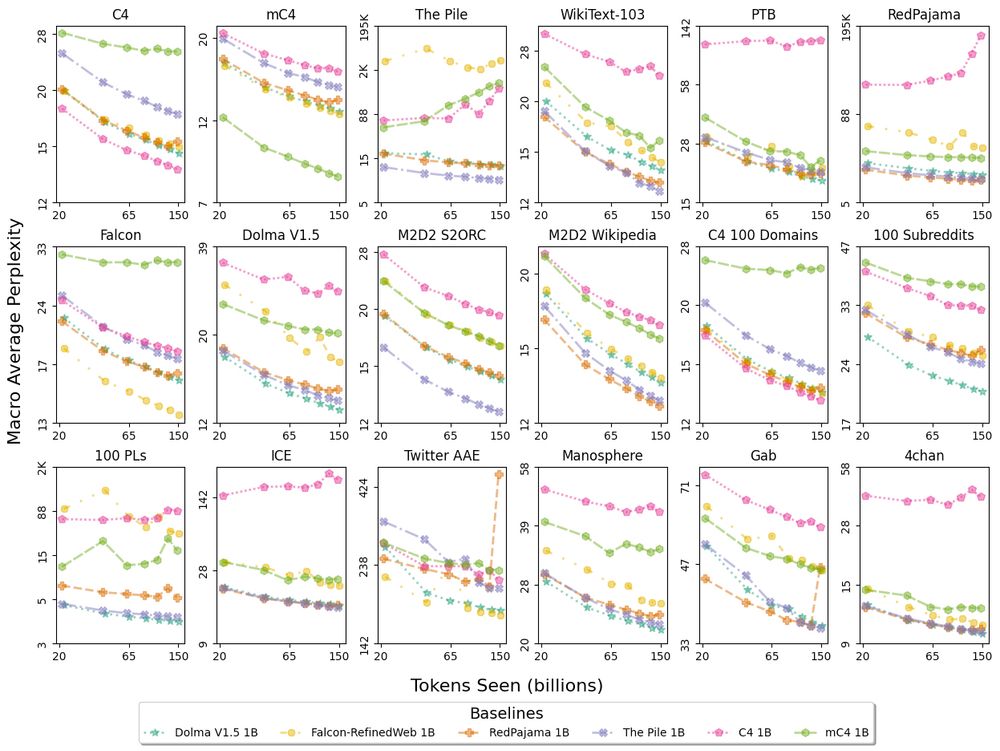
Perplexity macro averaged over any domains within each of the 18 top-level data sources in Paloma, using baselines with pretraining controls including decontamination. Evaluating on one monolithic corpus, such as C4, does not tell the complete story of model fit. Paloma lets us see when trends differ from one distribution of language to another. For instance, the 3 baselines trained on only Common Crawl data (C4, mC4-en, Falcon-RefinedWeb) exhibit high perplexity, sometimes with non-monotonic scaling over tokens seen, on specific evaluation sources such as The Pile, Dolma, and Dolma-100-Programming-Languages.
LMs are used to process text from many topics, styles, dialects, etc., but how well do they do?
📈 Evaluating perplexity on just one corpus like C4 doesn't tell the whole story 📉
✨📃✨
We introduce Paloma, a benchmark of 585 domains from NY Times to r/depression on Reddit.




















