
we've used Atari games as an RL benchmark for so long, but for a little while it's bugged me that it's a discrete action problem, since the original joysticks were analog...
@jessefarebro.bsky.social & i fix this by introducing the Continuous ALE (CALE)!
read thread for details!
1/9
05.12.2024 23:23 — 👍 30 🔁 7 💬 1 📌 3
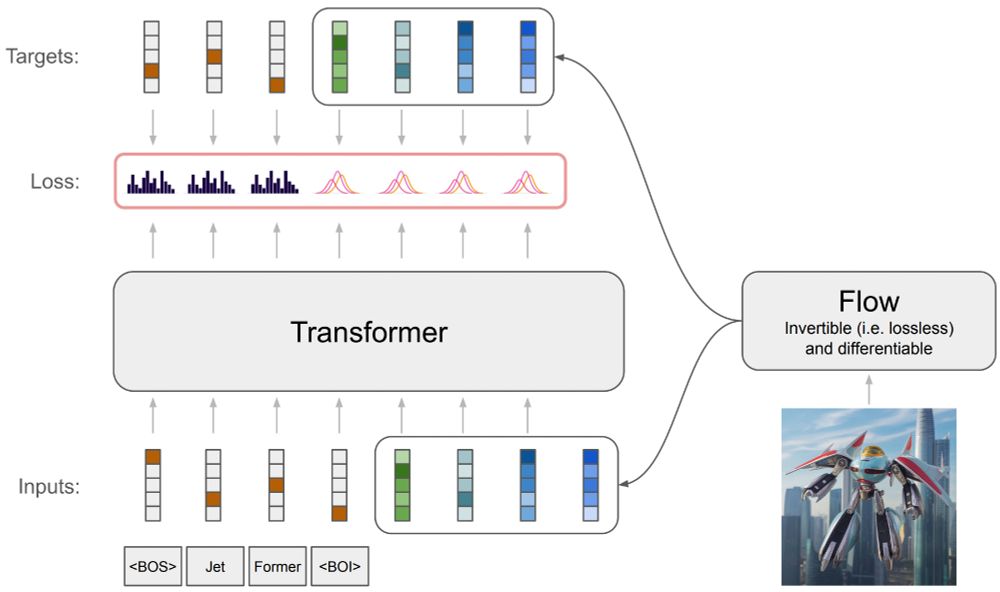
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
02.12.2024 16:41 — 👍 155 🔁 36 💬 4 📌 7
Oh don't get me wrong blocking individuals on sight whenever they get aggressive and toxic is healthy imo.
I was talking about some lists I saw like "hey guys I made a list of all HF employees, block them all". They don't live in the real world
28.11.2024 18:00 — 👍 2 🔁 0 💬 0 📌 0
Block lists = echo chamber speed run any%
28.11.2024 14:32 — 👍 1 🔁 0 💬 1 📌 0
Excellent blog post, summarizes quite well different recent findings in deep RL and where we are now
+ I fully agree with the conclusion: RL needs to become an *empirical science* and not a benchmark maximizing rat race where methods gets exponentially complex to squeeze out more reward points
28.11.2024 02:14 — 👍 7 🔁 1 💬 0 📌 0
HF being portrayed as evil/bad was definitely not on my radar, what a shitshow
27.11.2024 22:15 — 👍 8 🔁 1 💬 1 📌 0
Oh I def agree with you that more data is necessary but not sufficient, sorry for any misunderstanding
27.11.2024 20:19 — 👍 1 🔁 0 💬 0 📌 0
Very neat result and method !
But I'd argue your pretraining dataset is *big* compared to the diversity of the simulation tasks (low). Real world robotics is so much more complex/continuous/large dim that I'm afraid we may need wayyyy to much tokens for now to be able to train something like this
27.11.2024 20:17 — 👍 3 🔁 0 💬 1 📌 0
emphasis on the "well tuned". It's more of a practical choice rather than a fact about strict superiority. The same thing in RL: if 2 methods are equivalent but you have to do a big HP search for the first one while the second works out of the box, you choose the latter any day (Octo is like this)
27.11.2024 19:52 — 👍 3 🔁 0 💬 0 📌 0
Tbh I think the biggest added values of Octo were:
- open source implementation already coupled to a cheap table-top arm that I could buy (ViperX), integration is so hard and it saved me a lot of time
- Proof of existence of a good robot policy with few parameters < 100M
- good init for finetuning
27.11.2024 19:14 — 👍 5 🔁 0 💬 1 📌 0
I'll die on this hill: decision-making cognitive processes--artificial or not--are and will always be messy, and any subjective impression of formal exactitude is an illusionary narrative built afterwards.
Which doesn't mean the said narrative is not tremendously important.
27.11.2024 04:48 — 👍 48 🔁 2 💬 3 📌 0
I'm disheartened by how toxic and violent some responses were here.
There was a mistake, a quick follow up to mitigate and an apology. I worked with Daniel for years and is one of the persons most preoccupied with ethical implications of AI. Some replies are Reddit-toxic level. We need empathy.
27.11.2024 11:09 — 👍 334 🔁 37 💬 29 📌 9
*taps the sign*
works for general robot policies too
27.11.2024 14:51 — 👍 4 🔁 0 💬 0 📌 0
Maybe overselling is a strong word, but a lot of paper sell on generalization instead of stability/training difficulty, when most methods actually have the same common generalization issues.
I do agree that Diffusion Policy, Octo and such made it 100x easier to have something
27.11.2024 14:42 — 👍 1 🔁 0 💬 0 📌 0
This is a shame because I genuinely believe the Octo-type architecture is the way to go (basically a low-level visuo-motor controller with early fusion of sensors), but real generalization capabilities will only appear with multiple OOM more data
27.11.2024 14:38 — 👍 1 🔁 0 💬 1 📌 0
Agree 100% with you on this. You either have bottlenecked perf with frozen backbone, or no generalization, no other choice (except maybe adapters, but that's a patch)
I'd guess we need to work on continual pretraining / neuron-level finetuning. Maybe need to go beyond SGD on dense layers...
27.11.2024 14:32 — 👍 1 🔁 0 💬 0 📌 0
This is a striking example of the consequence of overselling in robot learning currently. Too many flashy results on internal demos, but since reproducible real benchmarking in robotics is close to impossible, most papers actually overfit to their setup (hardware + task), still in 2024
27.11.2024 14:20 — 👍 15 🔁 1 💬 2 📌 0
For OOD generalization, most of the degradation comes from lack of VISUAL generalization, which is entirely to be expected currently... We need better vision backbones, and such don't exist yet (closest I can think of is prismatic models= SigLip + DinoV2 for both semantics and geometric info)
27.11.2024 14:17 — 👍 1 🔁 0 💬 2 📌 0
1. Sure but that's true for any robotics model honestly... Too much moving parts
2. Define too much. In my experience with a few 100s demo (takes a day) you can solve some nice non-trivial tasks
But we are using a secret sauce for finetuning I can't spill yet
3. Depends on the generalization type
27.11.2024 14:15 — 👍 1 🔁 0 💬 1 📌 0
What do you mean by that?
If you try zero-shot on new objects, sure I'm not surprised, the generalization capabilities are oversold, but it's not hard to figure out why: domain gap.
But with proper fine-tuning Octo small is very good on any tasks we tried and Octo base even better.
27.11.2024 14:03 — 👍 1 🔁 0 💬 1 📌 0

Bought the M4 Mini for personal projects a few weeks ago on a small budget.
I'm still in shock of the performance/price ratio. It stays cool and dead silent as well. ARM arch ftw
Also is anyone using MLX a lot? Curious about its current state
26.11.2024 13:44 — 👍 2 🔁 0 💬 0 📌 0
Domain adaptation? Otherwise pre-finetuning comes to mind
26.11.2024 01:16 — 👍 1 🔁 0 💬 0 📌 0
Ok I get it now. But that's a different problem def from the paper, where streaming RL = online RL inf horizon + 1 policy update per env step. I think that's reasonable to call that "streaming", because it's more specific than online RL inf horizon, and emphasizes the instant update/no-memory.
25.11.2024 18:57 — 👍 1 🔁 0 💬 1 📌 0
I agree that being clear is important. What is the canonical setting called? Online RL means everything interacting with an environment for deepRLers... so that's not very specific. And I don't see the connection with infinite horizon at all here, it seems that's unrelated but I may be wrong
25.11.2024 18:22 — 👍 1 🔁 0 💬 1 📌 0
Bear with me: a prediction market on scientific research, by academics, for academics. Add credibility/confidence axis so that non-experts can still give opinions. Add discussion threads below the poll/voting metrics.
Ultra high quality vibe/consensus check on many science fields, centralized.
25.11.2024 17:13 — 👍 2 🔁 0 💬 0 📌 0
I think when it comes to the field of Deep Learning/AI the bigger problem is the immense number of papers that don't replicate [1], don't transfer [2], are badly specified [3], or have other methodolical problems [4, 5, 6]
24.11.2024 21:13 — 👍 30 🔁 3 💬 1 📌 0
So I don't think we should just say "Yeah that's just online RL". Using streaming RL in the name emphasizes the departure from a batched data practice which is widely used currently, which is the whole point of the paper
25.11.2024 15:56 — 👍 1 🔁 0 💬 1 📌 0
I agree from the POV of theory that it's just a practical choice, but practical choices do matter much more than theory let believe... Actually most profound advances in practical results in deep RL come from understanding what practical details are important for SGD to start working properly in RL
25.11.2024 15:54 — 👍 1 🔁 0 💬 1 📌 0
It's "true" online RL, ie batch size 1
25.11.2024 14:46 — 👍 1 🔁 0 💬 1 📌 0

Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
Value functions are a central component of deep reinforcement learning (RL). These functions, parameterized by neural networks, are trained using a mean squared error regression objective to match boo...
This sounds like exactly the same issue in RL where gradient scale is proportional to the reward, thus needing reward engineering for good convergence. They also found that turning the regression into classification basically solves it:
arxiv.org/abs/2403.03950
by @pcastr.bsky.social among others
25.11.2024 14:41 — 👍 4 🔁 0 💬 0 📌 0
#Anonymous: Actions Not Nouns. All that exists is interaction. #BindingChaos #3E https://spookyconnections.com/
PhD candidate at UCSD. Prev: NVIDIA, Meta AI, UC Berkeley, DTU. I like robots 🤖, plants 🪴, and they/them pronouns 🏳️🌈
https://www.nicklashansen.com
Building the future of mobile manipulation
I work at Sakana AI 🐟🐠🐡 → @sakanaai.bsky.social
https://sakana.ai/careers
Mathematician at UCLA. My primary social media account is https://mathstodon.xyz/@tao . I also have a blog at https://terrytao.wordpress.com/ and a home page at https://www.math.ucla.edu/~tao/
Research lab at Princeton University led by @adjiboussodieng.bsky.social. We work at the intersection of artificial intelligence (AI) and the natural sciences. Visit https://vertaix.princeton.edu to learn more. #AI4Science
Gradient surfer at UCL. FR, EN, also trying ES. 🇹🇼🇨🇦🇬🇳🇺🇸🇩🇴🇫🇷🇪🇸🇬🇧🇿🇦. Also on Twitter.
We are a research team on artificial intelligence for automotive applications working toward assisted and autonomous driving.
--> https://valeoai.github.io/ <--
Building generalist agents. Final-year PhD student @UPenn, Prev: @Amazon @IITBombay
http://kaustubhsridhar.github.io/
Assistant Professor of CS @nyuniversity.
I like robots!
Machine learning
Google DeepMind
Paris
Member of technical staff @periodiclabs
Open-source/open science advocate
Maintainer of torchrl / tensordict / leanrl
Former MD - Neuroscience PhD
https://github.com/vmoens
Prof (CS @Stanford), Co-Director @StanfordHAI, Cofounder/CEO @theworldlabs, CoFounder @ai4allorg #AI #computervision #robotics #AI-healthcare
ML & CV for robot perception
assistant professor @ Uni Bonn & Lamarr Institute
interested in self-learning & autonomous robots, likes all the messy hardware problems of real-world experiments
https://rpl.uni-bonn.de/
https://hermannblum.net/
Building generally intelligent robots that *just work* everywhere, out of the box, at Berkeley AI Research (BAIR) and Meta FAIR.
Previously at NYU Courant, MIT and visiting researcher at Meta AI.
https://mahis.life/
Assistant Professor at the University of Alberta. Amii Fellow, Canada CIFAR AI chair. Machine learning researcher. All things reinforcement learning.
📍 Edmonton, Canada 🇨🇦
🔗 https://webdocs.cs.ualberta.ca/~machado/
🗓️ Joined November, 2024



















