Excited to be presenting this paper at #ICLR2025 this week!
Come to the poster if you want to know more about how human brains and DNNs process video 🧠🤖
📆 Sat 26 Apr, 10:00-12:30 - Poster session 5 (#64)
📄 openreview.net/pdf?id=LM4PY...
🌐 sergeantchris.github.io/hundred_mode...
23.04.2025 10:57 — 👍 10 🔁 3 💬 0 📌 1

New preprint (#neuroscience #deeplearning doi.org/10.1101/2025...)! We trained 20 DCNNs on 941235 images with varying scene segmentation (original. object-only, silhouette, background-only). Despite object recognition varying (27-53%), all networks showed similar EEG prediction.
15.03.2025 13:55 — 👍 16 🔁 5 💬 1 📌 0
✨ The VIS Lab at the #University of #Amsterdam is proud and excited to announce it has #TWELVE papers 🚀 accepted for the leading #AI-#makers conference on representation learning ( #ICLR2025 ) in Singapore 🇸🇬. 1/n
👇👇👇 @ellisamsterdam.bsky.social
03.02.2025 07:44 — 👍 17 🔁 4 💬 1 📌 0
Excited to announce that this has been accepted in ICLR 25!
24.01.2025 20:20 — 👍 1 🔁 0 💬 0 📌 0
The Algonauts Project 2025
homepage
(1/4) The Algonauts Project 2025 challenge is now live!
Participate and build computational models that best predict how the human brain responds to multimodal movies!
Submission deadline: 13th of July.
#algonauts2025 #NeuroAI #CompNeuro #neuroscience #AI
algonautsproject.com
06.01.2025 10:08 — 👍 37 🔁 27 💬 2 📌 3
9/ This is our first research output in this interesting new direction and I’m actively working on this - so stay tuned for updates and follow-up works!
Feel free to discuss your ideas and opinions with me ⬇️
11.12.2024 16:13 — 👍 0 🔁 0 💬 0 📌 0
8/ 🎯 With this work we aim to forge a path that widens our understanding of temporal and semantic video representations in brains and machines, ideally leading towards more efficient video models and more mechanistic explanations of processing in the human brain.
11.12.2024 16:13 — 👍 2 🔁 0 💬 1 📌 0
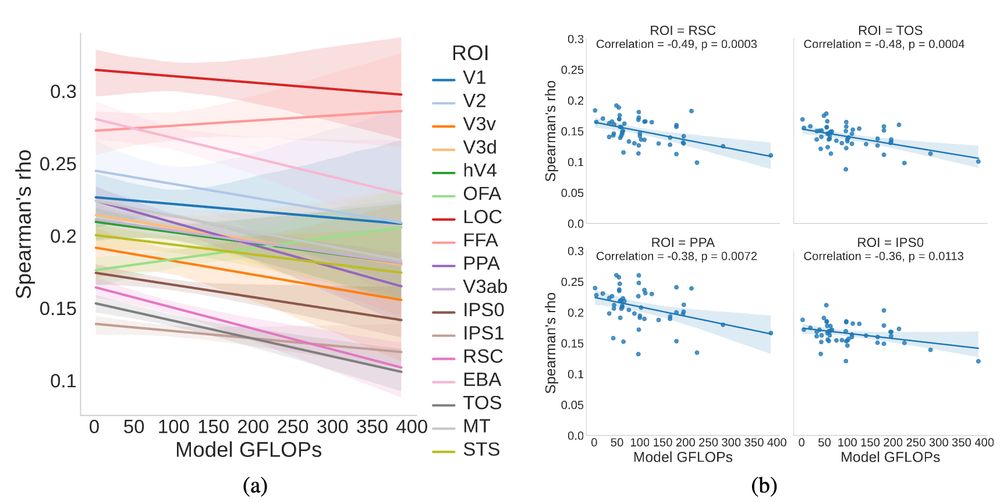
7/ We report a significant negative correlation of model FLOPs to alignment in several high-level brain areas, indicating that computationally efficient neural networks can potentially produce more human-like semantic representations.
11.12.2024 16:13 — 👍 0 🔁 0 💬 1 📌 0
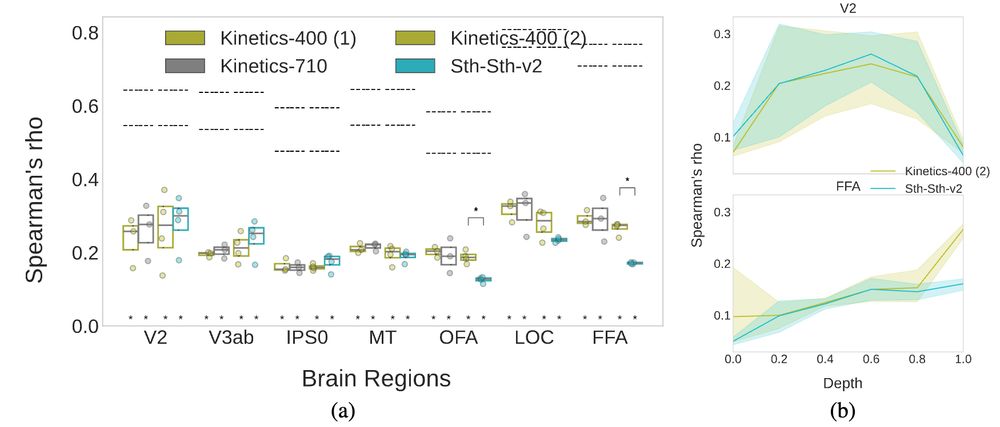
6/ Training dataset biases related to a certain functional selectivity (e.g. face features) can be transferred in brain alignment with the respective functionally selective brain area (e.g. face region FFA).
11.12.2024 16:13 — 👍 0 🔁 0 💬 1 📌 0
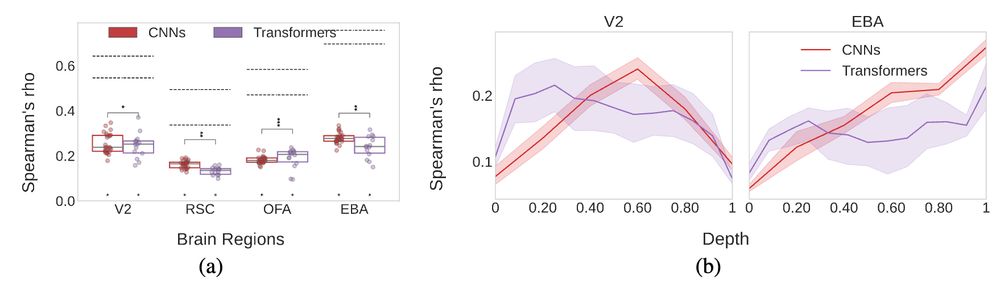
5/ Comparing model architectures, CNNs exhibit a better hierarchy overall (with a clear mid-depth peak for early regions and gradual improvement as depth increases for late regions). Transformers however, achieve an impressive correlation to early regions even from one tenth of layer depth.
11.12.2024 16:13 — 👍 0 🔁 0 💬 1 📌 0
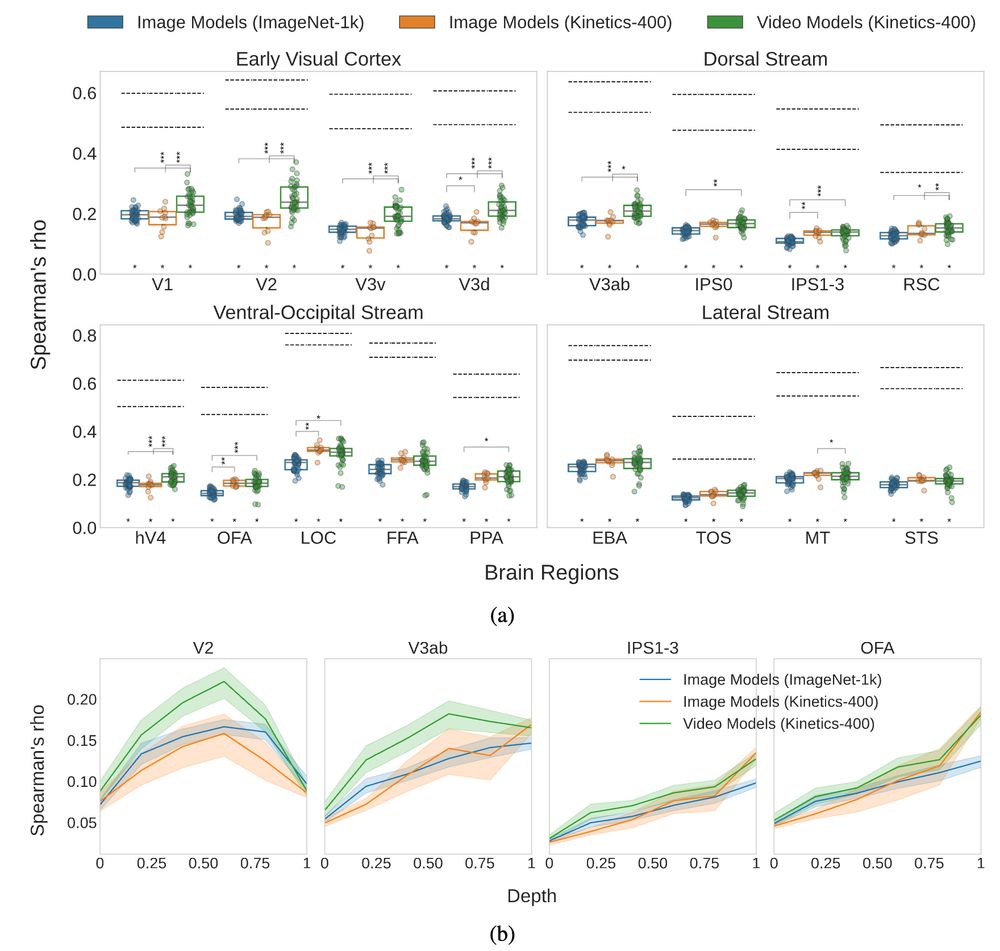
4/ We decouple temporal modeling from action space optimization by adding image action recognition models as control. Our results show that temporal modeling is key for alignment to early visual brain regions, while a relevant classification task is key for alignment to higher-level regions.
11.12.2024 16:13 — 👍 0 🔁 0 💬 1 📌 0
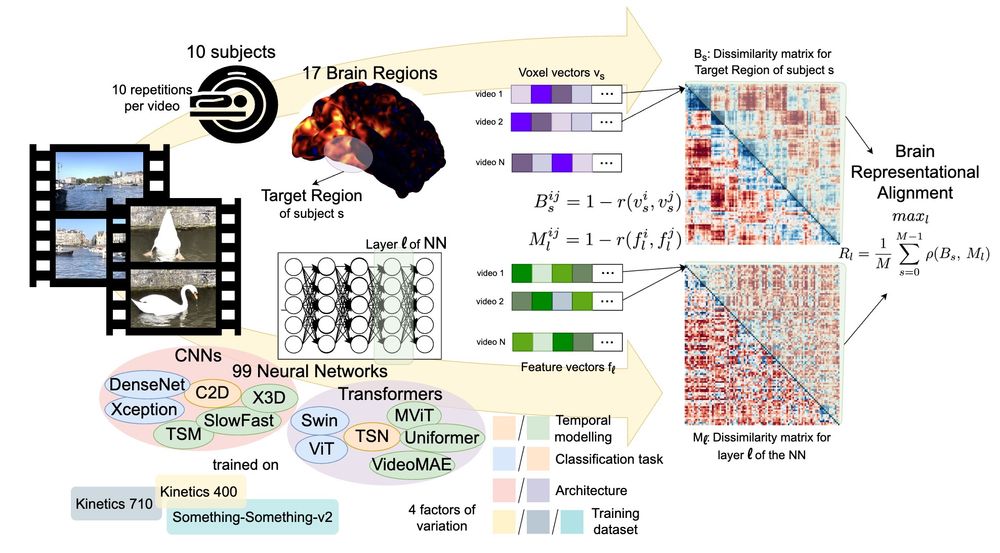
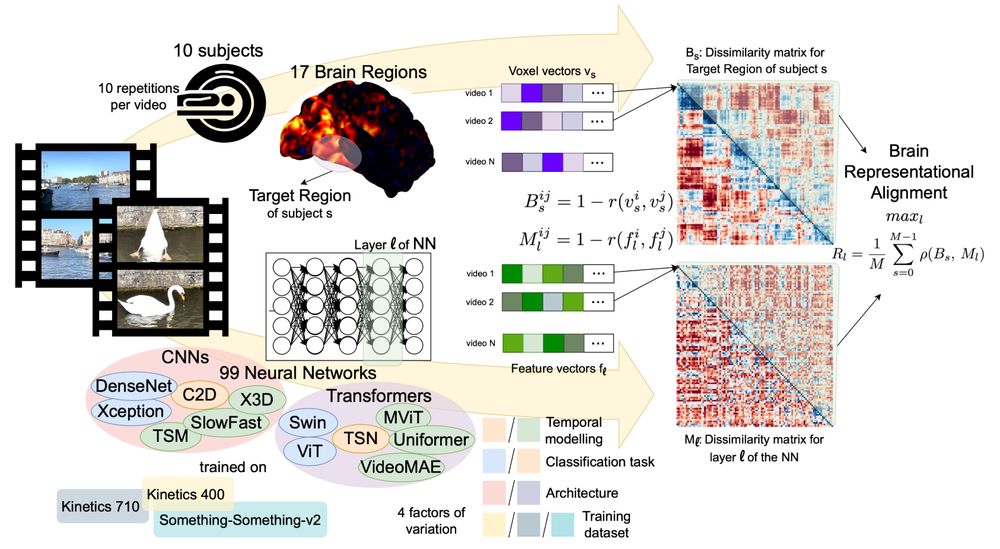
3/ We disentangle 4 factors of variation (temporal modeling, classification task, architecture, and training dataset) that affect model-brain alignment, which we measure by conducting Representational Similarity Analysis (RSA) across multiple brain regions and model layers.
11.12.2024 16:13 — 👍 0 🔁 0 💬 1 📌 0
2/ We take a step in this direction by performing a large-scale benchmarking of models on their representational alignment to the recently released Bold Moments Dataset of fMRI recordings from humans watching videos.
11.12.2024 16:13 — 👍 0 🔁 0 💬 1 📌 0
1/ Humans are very efficient in processing continuous visual input, neural networks trained to process videos are still not up to that standard.
What can we learn from comparing the internal representations of the two systems (biological and artificial)?
11.12.2024 16:13 — 👍 0 🔁 0 💬 1 📌 0

After a great conference in Boston, CCN is going to take place in Amsterdam in 2025! To help the exchange of ideas between #neuroscience, cognitive science, and #AI, CCN will for the first time have full length paper submissions (alongside the established 2 pagers)! Info below👇
#NeuroAI #CompNeuro
12.11.2024 09:27 — 👍 165 🔁 83 💬 4 📌 13
Postdoctoral Researcher in the Cusack Lab at Trinity College Dublin
| Passionate about Neuroscience and AI, infant and machine learning 💡
NeuroAI, Deep Learning for neuroscience, visual system in mice and monkeys, computational lab based in Göttingen (Germany), https://sinzlab.org
Hi 👋 I'm a postdoc in the #Neuroimmunology and #Imaging group at the @dzne.science Bonn 🧪🔬 Passionate about #ComputationalNeuroscience 🧠💻 and #NeuralModeling 🧮
🌍 fabriziomusacchio.com
👨💻 github.com/FabrizioMusacchio
🐘 sigmoid.social/@pixeltracker
Assistant Professor at Ecole Polytechnique, IP_Paris// Before: Oxford_VGG, Inria Grenoble // multimodality, genAI enthusiast // happy mum+dog_mum // opinions: mine
he/him; Researcher at NAVER LABS Europe. Greek, resident a Barcelona. https://www.skamalas.com/
Stanford Professor | NeuroAI Scientist | Entrepreneur working at the intersection of neuroscience, AI, and neurotechnology to decode intelligence @ enigmaproject.ai
NeuroAI Prof @EPFL 🇨🇭. ML + Neuro 🤖🧠. Brain-Score, CORnet, Vision, Language. Previously: PhD @MIT, ML @Salesforce, Neuro @HarvardMed, & co-founder @Integreat. go.epfl.ch/NeuroAI
Cortical surface modelling and interpretable/explainable #AI, geometric deep learning #neuroscience. Open science: HCP, dhcp, UKBiobank
Postdoc researcher @.NeuroRestore | PhD in AI & Neuroimaging @KCL
Asst Prof at NYU + Flatiron Institute
Computational + Statistical Neuroscience
https://neurostatslab.org/
Research Scientist @META | Guest Researcher @FlatironCCN | Visiting Scholar @NYU | PhD @ZuckermanBrain @Columbia | Neuro & AI Enthusiast
|| assistant prof at University of Montreal || leading the systems neuroscience and AI lab (SNAIL: https://www.snailab.ca/) 🐌 || associate academic member of Mila (Quebec AI Institute) || #NeuroAI || vision and learning in brains and machines
Phd student at @MPI_NL@Donders, working on multimodal semantic representations in 🖥️ and 👶🧠 https://tianaidong.github.io/
5th year PhD student in Cognitive Science at Johns Hopkins, working with Leyla Isik
https://www.hannah-small.com/
Scientist 👩🔬 & EPFL Prof 🇨🇭 | DeepLabCut.org , 🦓 cebra.ai | neuroscience & ML 🧠 mackenziemathislab.org | ✨CSO at Kinematik.ai | occasionally 🐦⬛birds/🌱outdoors/🍣food/👠fashion
Research scientist at Google in Zurich
http://research.google/teams/connectomics
PhD from @mackelab.bsky.social
Computational Cognitive Science PhD at Johns Hopkins with Leyla Isik
| BS @Stanford|
| 🔗 https://garciakathy.github.io/ |
vision lab @ harvard
[i am] unbearably naive
ML Scientist @CuspAI | Innovating for a greener future 🌱
 11.06.2025 11:47 — 👍 2 🔁 0 💬 0 📌 0
11.06.2025 11:47 — 👍 2 🔁 0 💬 0 📌 0





















