
Excited to share PoET-2, our next breakthrough in protein language modeling. It represents a fundamental shift in how AI learns from evolutionary sequences. 🧵 1/13
11.02.2025 14:30 — 👍 31 🔁 15 💬 1 📌 0Excited to share PoET-2, our next breakthrough in protein language modeling. It represents a fundamental shift in how AI learns from evolutionary sequences. 🧵 1/13
11.02.2025 14:30 — 👍 31 🔁 15 💬 1 📌 0It's long seemed that molecular biology is a natural home for ML interpretability research, given the maturity of human-constructed models of biological mechanisms—permitting direct comparison with their ML-derived counterparts—unlike vision and NLP. Our first foray below👇.
10.02.2025 16:15 — 👍 38 🔁 15 💬 0 📌 0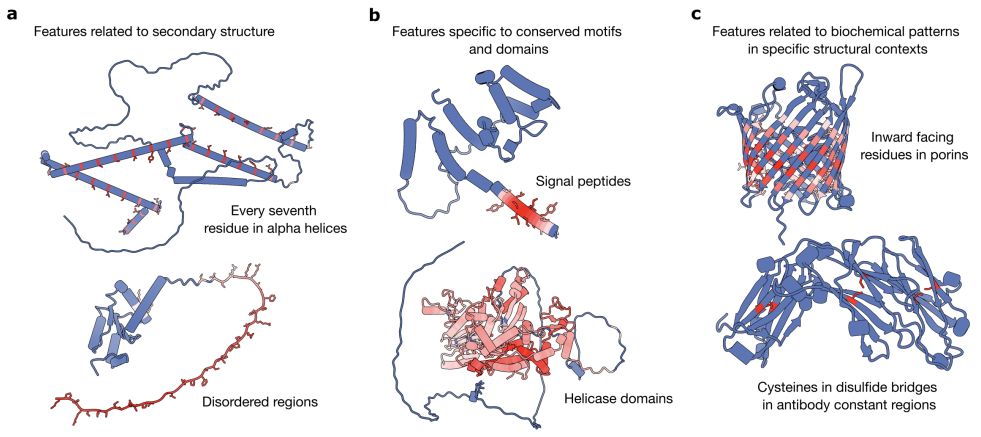
A range of features identified from sparse autoencoders trained on different layers on ESM2-650M
This might be the best paper on applying sparse autoencoders to protein language models. The authors identify how neural networks trained on amino acid sequences "discover" different features, some specific to individual protein families, other for substructures
www.biorxiv.org/content/10.1...
Thank you for your help interpreting features :) It was really special having the community squint at these features with us. Lots of weird features means that everyone sees different/new things!
10.02.2025 16:13 — 👍 2 🔁 0 💬 0 📌 0
Thanks to our coauthors Minji Lee, Steven Yu, and @moalquraishi.bsky.social!
Check work from Elana Pearl on using SAEs on pLMs too!
x.com/ElanaPearl/s...

We’re excited about the potential of SAEs in biology and would love to hear your ideas.
Our preprint: www.biorxiv.org/content/10.1...
Visualizer: interprot.com
Github: github.com/etowahadams/...
HuggingFace: huggingface.co/liambai/Inte...
Such hard-to-interpret but predictive features could result from biases and limitations in our datasets and models. However, there is another intriguing possibility: these features may correspond to biological mechanisms that have yet to be discovered.
10.02.2025 16:12 — 👍 0 🔁 0 💬 1 📌 0
Not all predictive features are easily interpretable. For instance, a predictor for membrane localization, latent L28/3154, predominantly activates on poly-alanine sequences, whose functional relevance remains unclear.
10.02.2025 16:12 — 👍 0 🔁 0 💬 1 📌 0
When trained to predict thermostability, the linear models assign their most positive weights to features that correlate with hydrophobic amino acids and their most negative weights to a feature activating on glutamate, an amino acid linked to instability.
10.02.2025 16:12 — 👍 0 🔁 0 💬 1 📌 0
For the extracellular class, we uncover features that activate on signal peptides, which trigger the cellular mechanisms that transport proteins outside the cell.
10.02.2025 16:12 — 👍 0 🔁 0 💬 1 📌 0These sequence motifs consist of K/R rich regions and act like a “passport” for proteins to enter the nucleus. As many NLS variants still remain unknown, our SAE-based approach has potential to become a novel method to aid their discovery and characterization.
10.02.2025 16:12 — 👍 0 🔁 0 💬 1 📌 0
For example, we trained a linear classifier on subcellular localization labels (nucleus, cytoplasm, mitochondrion…). Excitingly, the most highly weighted features for the nucleus class recognize nuclear localization signals (NLS)
10.02.2025 16:12 — 👍 2 🔁 0 💬 1 📌 0Having established methods to interpret features, we sought to associate features with functional properties and more generally understand pLM performance on downstream tasks. We train linear models on SAE features and analyze features that contribute the most to task performance.
10.02.2025 16:12 — 👍 0 🔁 0 💬 1 📌 0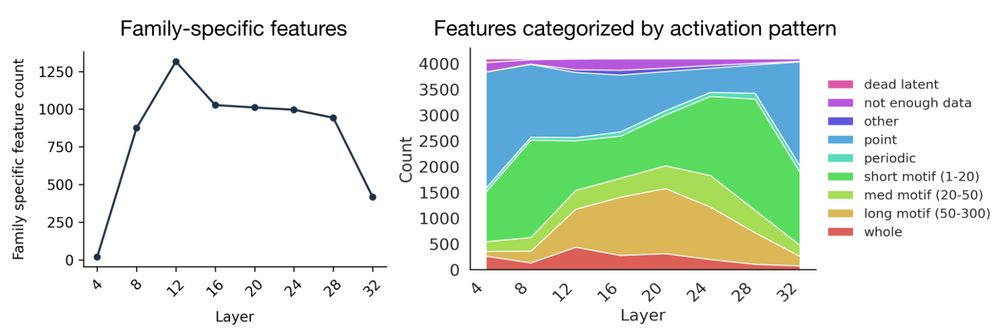
We categorize SAE latents by family specificity and activation pattern by layer. We find more family specific features in middle layers, and more single token activating (point) features in layer layers. We also study how SAE hyperparameters change what features are uncovered.
10.02.2025 16:12 — 👍 0 🔁 0 💬 1 📌 0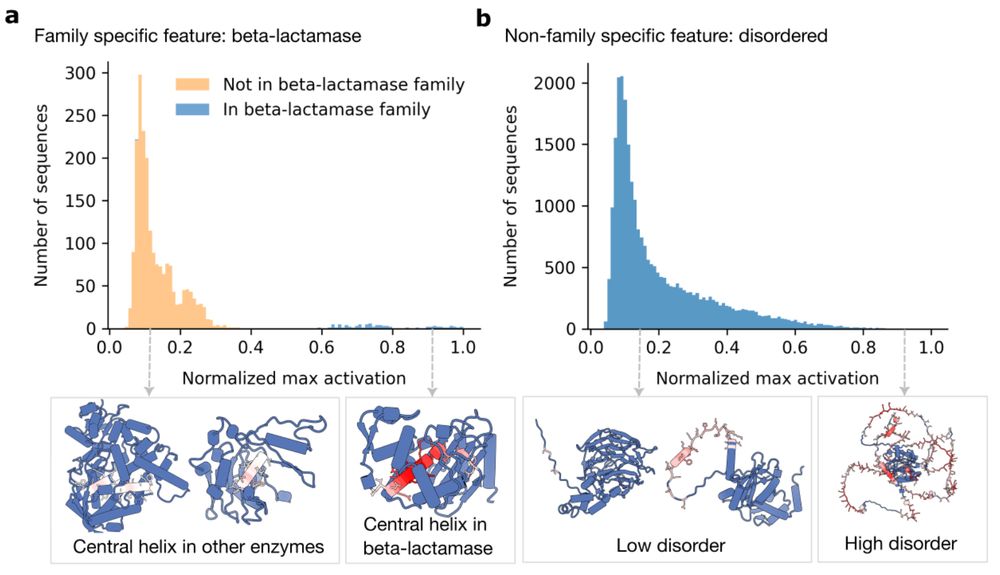
We find many features appear highly specific to certain protein families, suggesting pLMs contain an internal notion of protein families which mirrors known homology-based families. Other features correspond to broader, family-independent coevolutionary signals.
10.02.2025 16:12 — 👍 2 🔁 0 💬 1 📌 0
(Regarding the recent discourse surrounding SAEs, we refer to this thread from @banburismus_)
x.com/banburismus_...
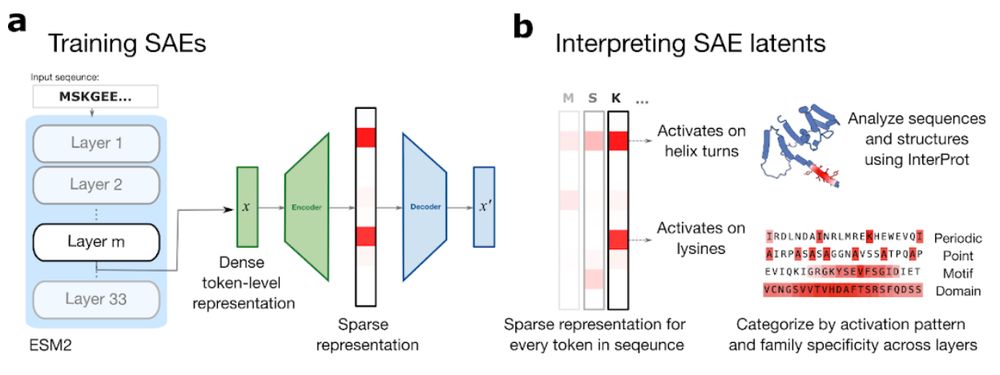
Using sparse autoencoders (SAEs), we find many interpretable features in a protein language model (pLM), ESM-2, ranging from secondary structure, to conserved domains, to context specific properties. Explore them at interprot.com!
10.02.2025 16:12 — 👍 2 🔁 1 💬 1 📌 0For more background on mechanistic interpretability and protein language models, check out this previous thread on our work (X link, sorry) x.com/liambai21/st...
10.02.2025 16:12 — 👍 1 🔁 0 💬 1 📌 0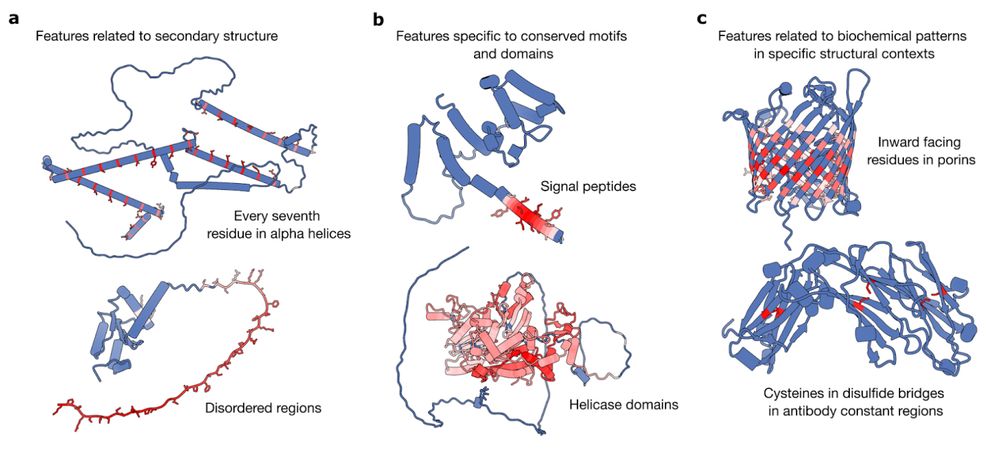
Can we learn protein biology from a language model?
In new work led by @liambai.bsky.social and me, we explore how sparse autoencoders can help us understand biology—going from mechanistic interpretability to mechanistic biology.