
UT Austin campus
Extremely excited to announce that I will be joining
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉

@archiki.bsky.social
Ph.D. Student at UNC NLP | Apple Scholar in AI/ML Ph.D. Fellowship | Prev: FAIR at Meta, AI2, Adobe (Intern) | Interests: #NLP, #ML | https://archiki.github.io/
UT Austin campus
Extremely excited to announce that I will be joining
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉
🌵 I'm going to be presenting PBT at #NAACL2025 today at 2PM! Come by poster session 2 if you want to hear about:
-- balancing positive and negative persuasion
-- improving LLM teamwork/debate
-- training models on simulated dialogues
With @mohitbansal.bsky.social and @peterbhase.bsky.social
✈️ Heading to #NAACL2025 to present 3 main conf. papers, covering training LLMs to balance accepting and rejecting persuasion, multi-agent refinement for more faithful generation, and adaptively addressing varying knowledge conflict.
Reach out if you want to chat!
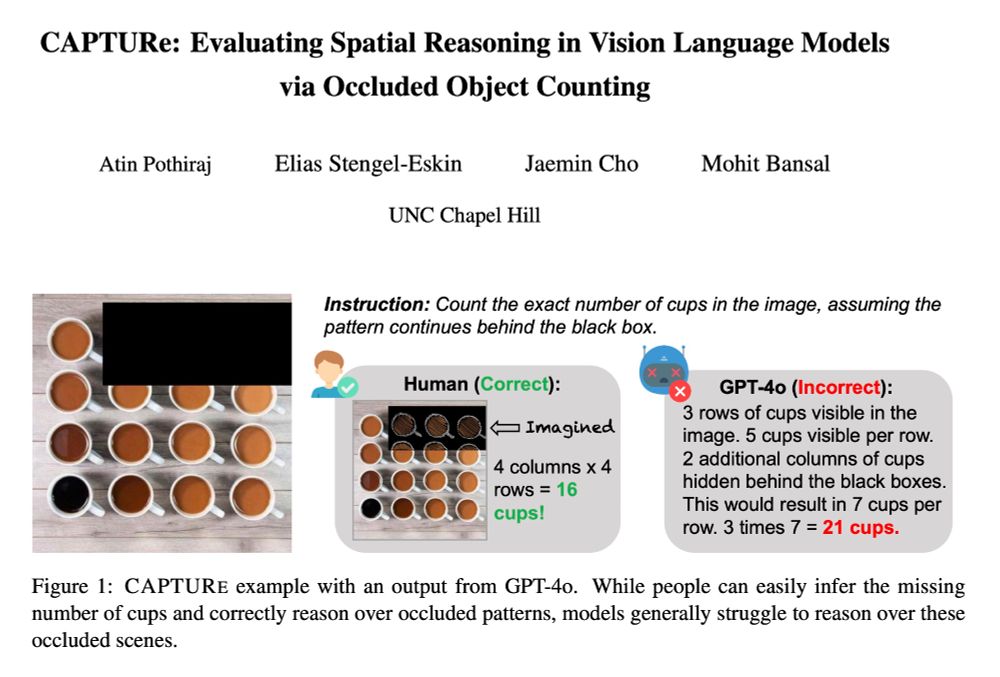
Check out 🚨CAPTURe🚨 -- a new benchmark testing spatial reasoning by making VLMs count objects under occlusion.
SOTA VLMs (GPT-4o, Qwen2-VL, Intern-VL2) have high error rates on CAPTURe (but humans have low error ✅) and models struggle to reason about occluded objects.
arxiv.org/abs/2504.15485
🧵👇

In Singapore for #ICLR2025 this week to present papers + keynotes 👇, and looking forward to seeing everyone -- happy to chat about research, or faculty+postdoc+phd positions, or simply hanging out (feel free to ping)! 🙂
Also meet our awesome students/postdocs/collaborators presenting their work.

Thanks to my coauthors: @hwang98.bsky.social @esteng.bsky.social @mohitbansal.bsky.social
for the fun collaboration!
@unccs.bsky.social
Paper: arxiv.org/abs/2504.13079
Data and Code: github.com/HanNight/RAM...

Can RAG systems handle imbalanced evidence or increasing misinformation?
➡️ As document support becomes imbalanced, baselines ignore under-supported correct answers but MADAM-RAG maintains stable performance
➡️ As misinformation 📈, baselines degrade sharply (−46%) but MADAM-RAG remains more robust

How important are multi-round debate and aggregation in MADAM-RAG?
Increasing debate rounds in MADAM-RAG improves performance by allowing agents to refine answers via debate.
Aggregator provides even greater gains, especially in early rounds, aligning conflicting views & suppressing misinfo.

We evaluate on 3 datasets: FaithEval (suppression of misinformation), AmbigDocs (disambiguation across sources), RAMDocs (our dataset w/ different types of conflict).
MADAM-RAG consistently outperforms concatenated-prompt and Astute RAG baselines across all three datasets and model backbones.

We propose MADAM-RAG, a structured, multi-agent framework designed to handle inter-doc conflicts, misinformation, & noise in retrieved content, comprising:
1️⃣ Independent LLM agents - generate intermediate response conditioned on a single doc
2️⃣ Centralized aggregator
3️⃣ Iterative multi-round debate

📂RAMDocs is designed to reflect the complexities of real-world retrieval. It includes:
➡️ Ambiguous queries w/ multiple valid ans.
➡️ Imbalanced document support (some answers backed by many sources, others by fewer)
➡️ Docs w/ misinformation (plausible but wrong claims) or noisy/irrelevant content
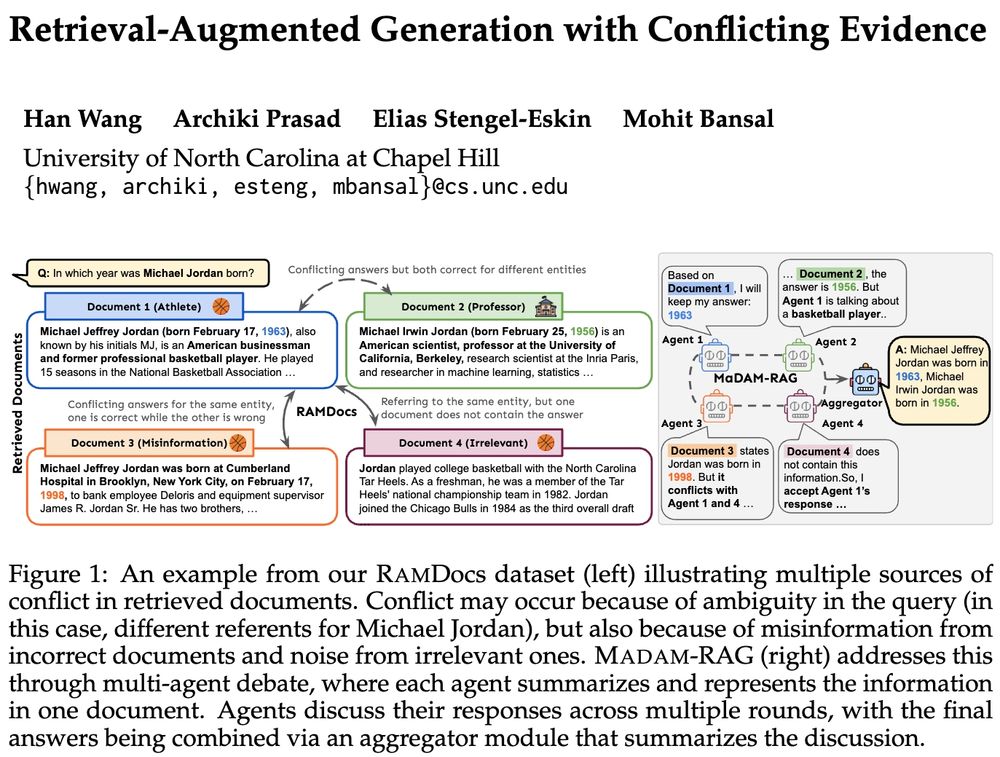
🚨Real-world retrieval is messy: queries are ambiguous or docs conflict & have incorrect/irrelevant info. How can we jointly address these problems?
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
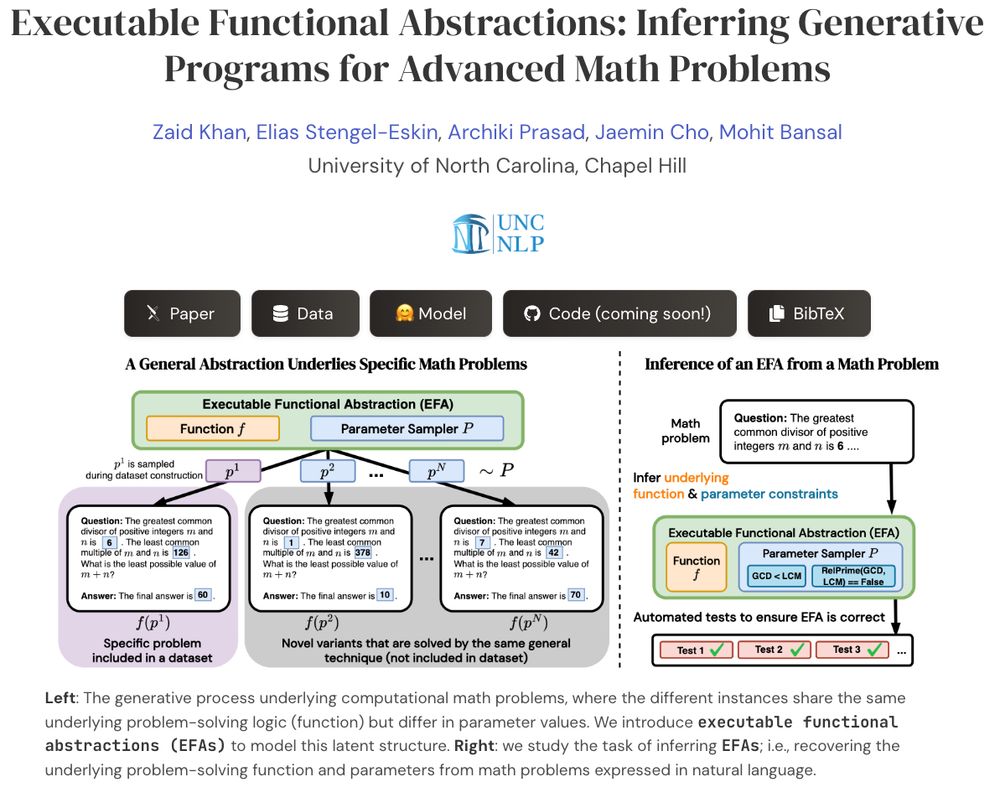
What if we could transform advanced math problems into abstract programs that can generate endless, verifiable problem variants?
Presenting EFAGen, which automatically transforms static advanced math problems into their corresponding executable functional abstractions (EFAs).
🧵👇
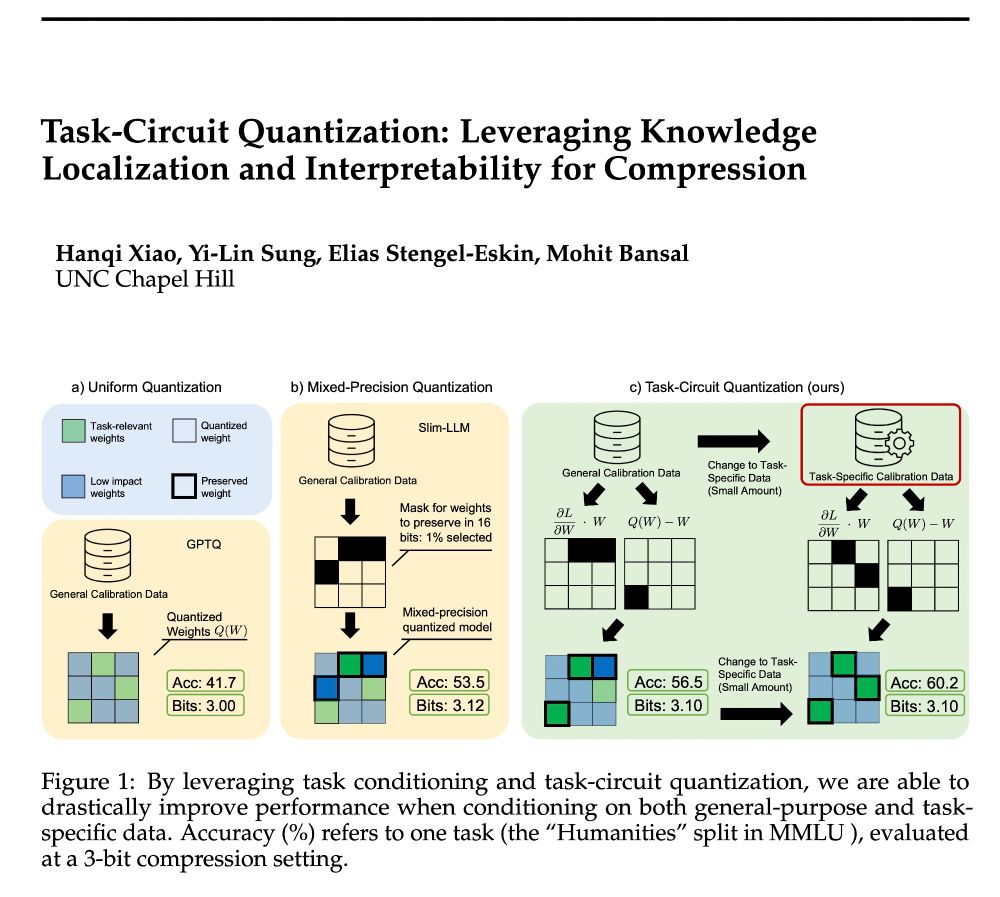
🚨Announcing TaCQ 🚨 a new mixed-precision quantization method that identifies critical weights to preserve. We integrate key ideas from circuit discovery, model editing, and input attribution to improve low-bit quant., w/ 96% 16-bit acc. at 3.1 avg bits (~6x compression)
📃 arxiv.org/abs/2504.07389
🎉 A big congratulations to @archiki.bsky.social (advised by Prof. @mohitbansal.bsky.social) for the being awarded the 2025 Apple Scholars in AI/ML PhD Fellowship!", we are proud of you! 👏
27.03.2025 19:36 — 👍 2 🔁 1 💬 0 📌 0Thanks Elias!!
27.03.2025 20:24 — 👍 1 🔁 0 💬 0 📌 0Thanks Jaemin, learned so much from you as well!
27.03.2025 20:24 — 👍 0 🔁 0 💬 0 📌 0🎉🎉 Big congrats to @archiki.bsky.social on being awarded the @Apple AI/ML PhD Fellowship, for her extensive contributions in evaluating+improving reasoning in language/reward models and their applications to new domains (ReCEval, RepARe, System-1.x, ADaPT, ReGAL, ScPO, UTGen, GrIPS)! #ProudAdvisor
27.03.2025 19:41 — 👍 3 🔁 1 💬 1 📌 0
🥳🥳 Honored and grateful to be awarded the 2025 Apple Scholars in AI/ML PhD Fellowship! ✨
Huge shoutout to my advisor @mohitbansal.bsky.social, & many thanks to my lab mates @unccs.bsky.social , past collaborators + internship advisors for their support ☺️🙏
machinelearning.apple.com/updates/appl...

Introducing VEGGIE 🥦—a unified, end-to-end, and versatile instructional video generative model.
VEGGIE supports 8 skills, from object addition/removal/changing, and stylization to concept grounding/reasoning. It exceeds SoTA and shows 0-shot multimodal instructional & in-context video editing.
🚨 Check out "UTGen & UTDebug" for learning to automatically generate unit tests (i.e., discovering inputs which break your code) and then applying them to debug code with LLMs, with strong gains (>12% pass@1) across multiple models/datasets! (see details in 🧵👇)
1/4

Thanks to my amazing co-authors @esteng.bsky.social (co-lead), @cyjustinchen.bsky.social, @codezakh.bsky.social, @mohitbansal.bsky.social
@unccs.bsky.social
Paper: arxiv.org/abs/2502.01619
Code+Datasets: github.com/archiki/UTGe...


Lastly, we show that both test-time scaling and backtracking are crucial for UTDebug, and scaling the number of generated UTs also consistently improves code accuracy.
04.02.2025 19:09 — 👍 0 🔁 0 💬 1 📌 0
Combining UTGen with UTDebug 🤝 we consistently outperform no UT feedback, randomly sampling UTs, and prompting targeted UTs across 3 models & datasets.
For partially correct code with subtle errors (our MBPP+Fix hard split) debugging with UTGen improves over baselines by >12.35% on Qwen 2.5!

RQ3: We also propose ✨UTDebug ✨ with two key modifications:
1⃣Test-time scaling (self-consistency over multiple samples) for increasing output acc.
2⃣Validation & Backtracking: Generating multiple UTs to perform validation, accept edits only when the overall pass rate increases & backtrack otherwise
We verify the tradeoff for 0-shot LLMs: when using UTs generated w/o conditioning on the code, the outputs acc is high -- but these UTs are not effective at revealing errors (especially for MBPP+Fix Hard). When prompted to generate failing UTs, we get high attack rate but less accurate UT outputs.
04.02.2025 19:09 — 👍 0 🔁 0 💬 1 📌 0
On three metrics: attack rate, output acc, and acc + attack (measuring both) we benchmark several open-source 7-8B LLMs.
We find that UTGen models balance output acc and attack rate and result in 7.59% more failing/error-revealing unit tests with correct outputs on Qwen-2.5.

✨UTGen ✨ bootstraps training data from code generation datasets to train unit test generators.
Given coding problems and their solutions, we 1⃣ perturb the code to simulate errors, 2⃣ find challenging UT inputs, 3⃣ generate CoT rationales deducing the correct UT output for challenging UT inputs.
We find zero-shot LLMs exhibit a tradeoff between output accuracy and attack rate: UTs whose outputs can be predicted correctly are too easy (not failing) and it's hard to predict outputs of challenging inputs.
So how do we do both, i.e., have a high attack rate and output acc (RQ2)?
A: ✨UTGen ✨
RQ1: What are desirable properties of UT generators?
1⃣ The generator should correctly predict the output for a UT input to a task (output acc 📈)
2⃣ It should uncover errors by generating failing UT inputs, i.e., given incorrect code generate challenging inputs that raise errors (attack rate 📈)



















