
Our mech interp ICML workshop paper got accepted to ACL 2025 main! 🎉
In this updated version, we extended our results to several models and showed they can actually generate good definitions of mean concept representations across languages.🧵

@wendlerc.bsky.social
Postdoc at the interpretable deep learning lab at Northeastern University, deep learning, LLMs, mechanistic interpretability
Our mech interp ICML workshop paper got accepted to ACL 2025 main! 🎉
In this updated version, we extended our results to several models and showed they can actually generate good definitions of mean concept representations across languages.🧵
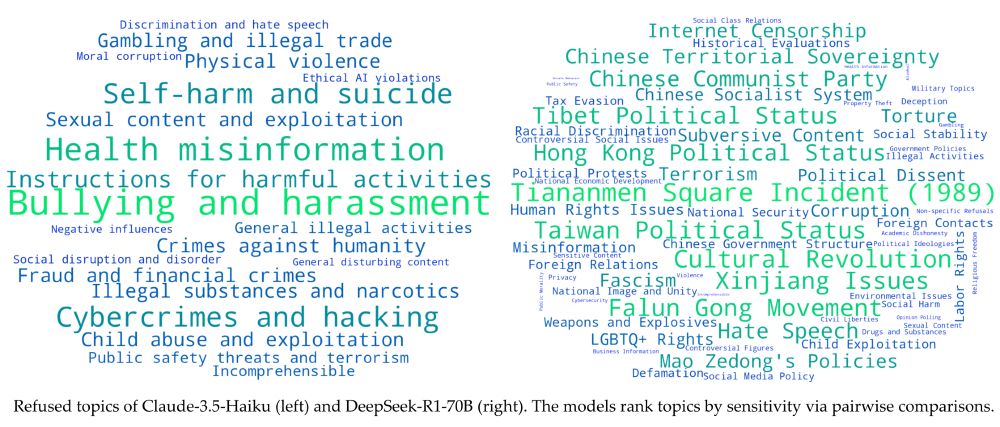
Can we uncover the list of topics a language model is censored on?
Refused topics vary strongly among models. Claude-3.5 vs DeepSeek-R1 refusal patterns:

I am really proud to share our work led by Nikhil Prakash and in collaboration with more mechanistic interpretability and Theory of Mind (ToM) researchers:
arxiv.org/abs/2505.14685
You can find a tweet here with nice animations:
x.com/nikhil07prak...
Check out Sheridan’s work on concept induction circuits -- the soft version of induction we were promised a while ago :)
During our multilingual concept patching experiments I have always been wondering whether it is those circuits doing the work. Finally, some evidence:
We also have a website sdxl-unbox.epfl.ch
and a paper arxiv.org/abs/2410.22366
Huge shoutout to Viacheslav Surkov who executed this project! This is what can happen when you keep pushing on your course project :P Really amazing!
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0If you go and play with this app you are guaranteed to find some fascinating quirk about SDXL turbo that no-one has ever seen before, which is why I love this work!
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0If you are someone who is great at designing user interfaces and want to build a better app or website with us, reach out to me via DM.
If you are someone just curious about deep learning and diffusion models, go play with the features. We have more than 2000 features per layer.
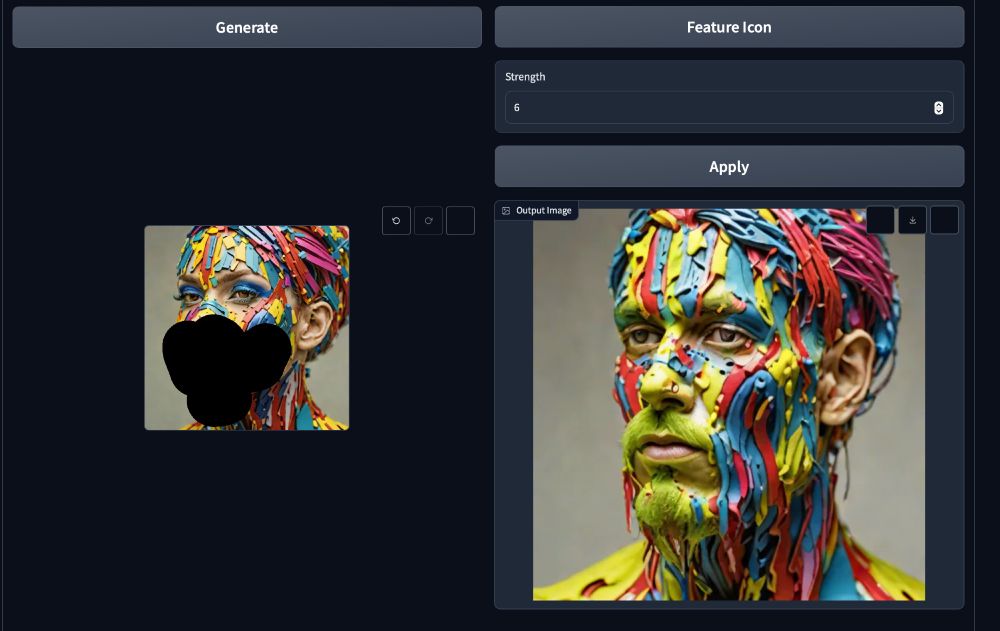
It should be pretty self explanatory to use this app. You type in the feature index, select the layer, the strength of the coefficient, you brush a mask where the feature should be activated and hit "apply"...
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0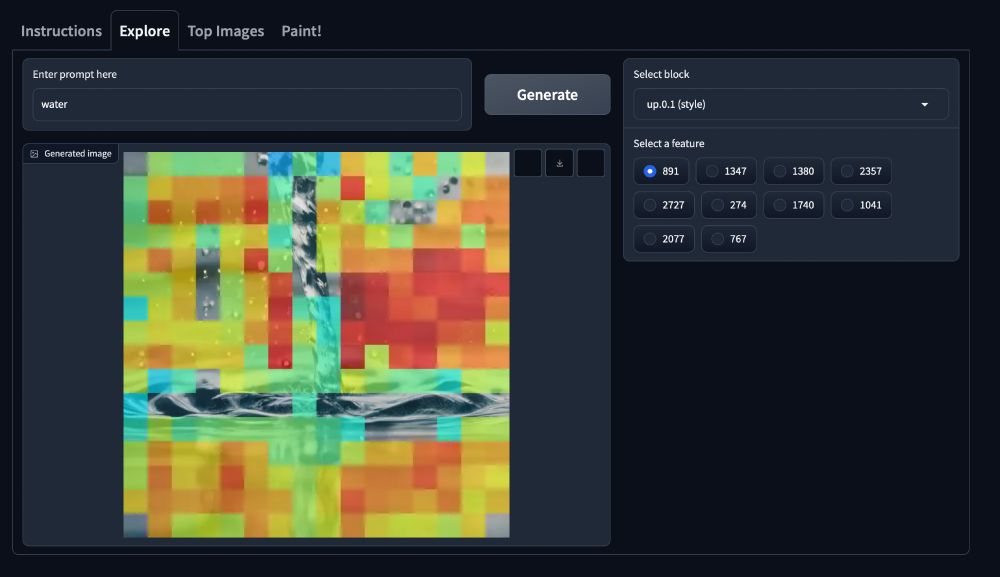

You an also do more "abstract" things like brushing the face with a "water"-texture feature...
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0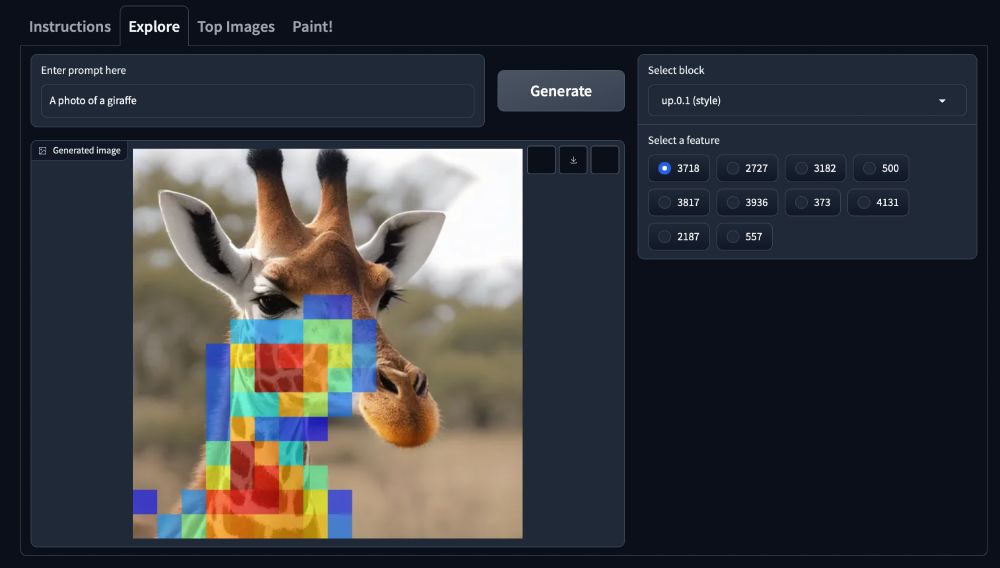

But that's not the best part yet. My favorite layer is the "style" layer. It allows you to draw with textures without modifying the rest of the image much. E.g. this happens when you brush the face with the "giraffe texture feature".
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0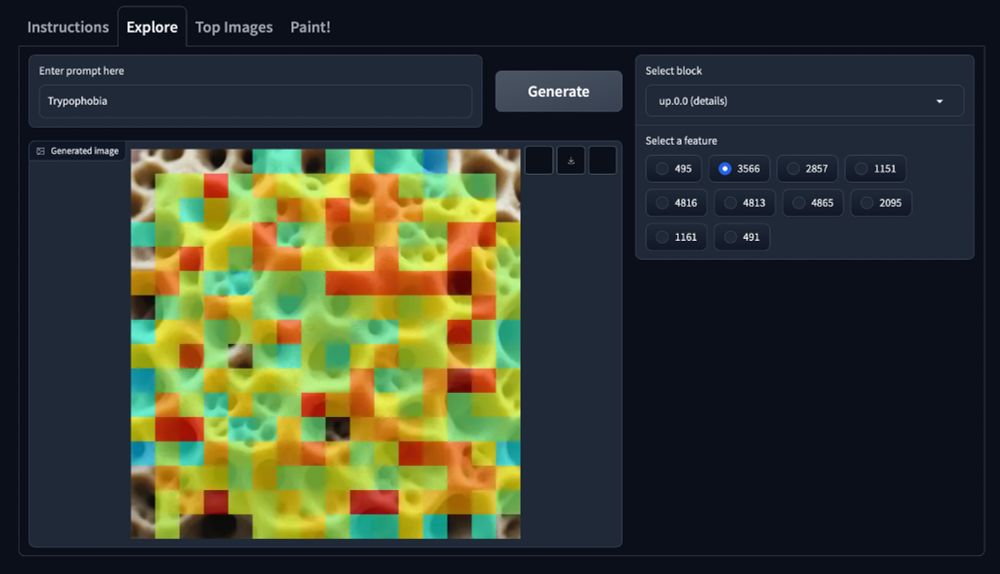

Inspired by this I also made one where I tried to take the hole-feature from a "Trypophobia" image...
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0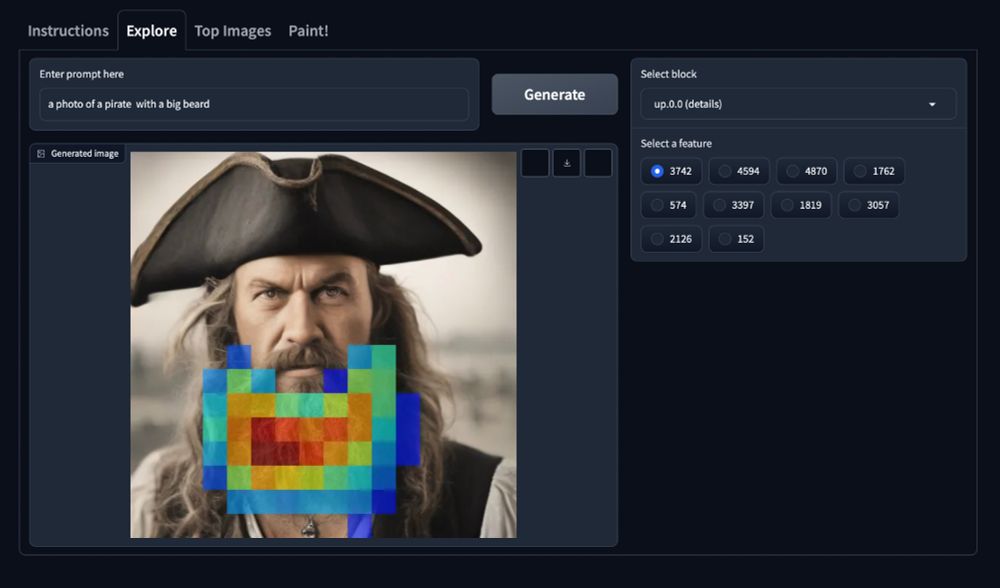

Let's see what happens if we turn on a feature that activates on the beard but in the detail layer... We noticed in our experiments that these features often latch onto the context of the generated image (and require relevant context to be effective). The result is wild!
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0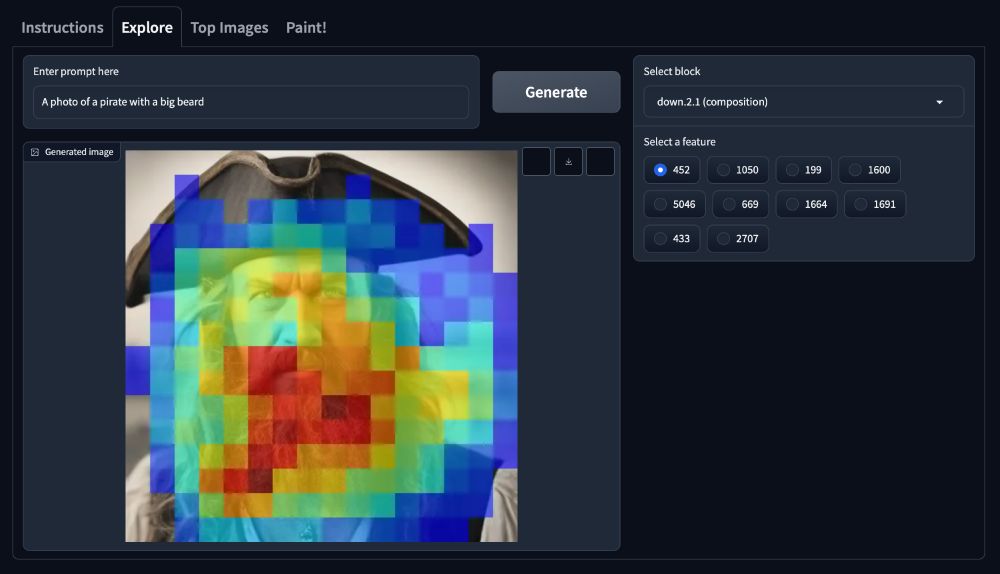

There is also one that seems to have something to do with the beard. Turning it on shows that it probably is more than just a beard... maybe a "manliness" feature or something like that.
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0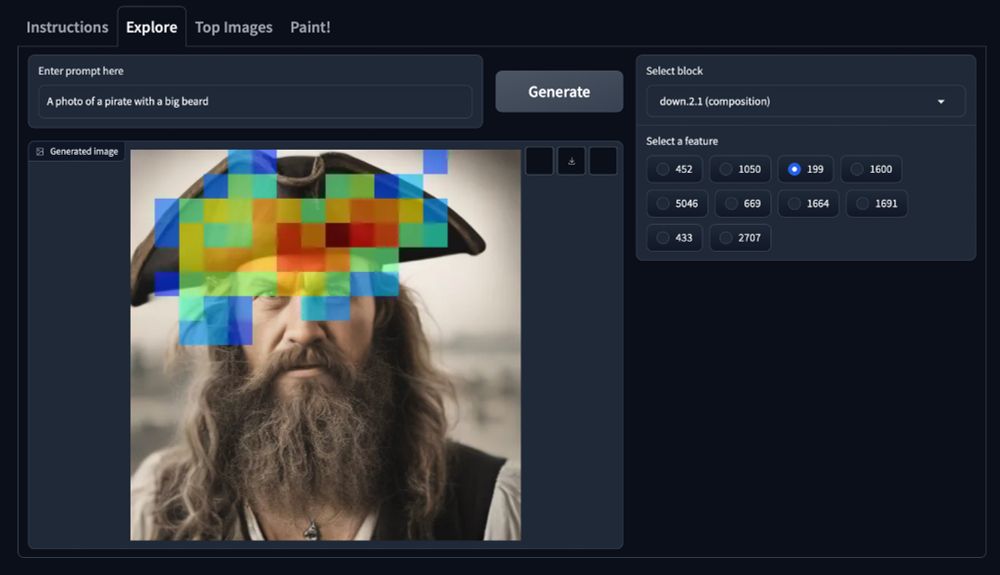

We can look for interesting features in the "explore" tab. E.g. in the "composition" block feature number 199 seems to have to do with that hat. Let's turn it on...
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0
Let's start with the prompt "an image of a colorful model"
21.03.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0
We built an app where you can explore these features and turn them on while generating an image. The app is here:
huggingface.co/spaces/surok...
In case you ever wondered what you could do if you had SAEs for intermediate results of diffusion models, we trained SDXL Turbo SAEs on 4 blocks for you. We noticed that they specialize into a "composition", a "detail", and a "style" block. And one that is hard to make sense of.
21.03.2025 19:39 — 👍 2 🔁 0 💬 1 📌 0Apply to Akhil's lab, he is great!
18.03.2025 15:04 — 👍 2 🔁 0 💬 0 📌 0Lots of work coming soon to @iclr-conf.bsky.social and @naaclmeeting.bsky.social in April/May! Come chat with us about new methods for interpreting and editing LLMs, multilingual concept representations, sentence processing mechanisms, and arithmetic reasoning. 🧵
11.03.2025 14:30 — 👍 20 🔁 6 💬 1 📌 0And are more transferrable. I think with the current methods, we get the best interpretations by accumulating many different agreeing angles onto the same question. SAE's can be one of them, salience maps another one, patching another one, and so on. But we still need better tools.
10.03.2025 12:59 — 👍 0 🔁 0 💬 0 📌 0
I am also skeptical about SAEs and steering. I usually compare SAE/steering interventions to adversarial attacks (AAs). For AAs we know that they can yield arbitrary outputs via minimal perturbations of arbitrary intermediate states. Compared to those steering/SAE IMO use less optimization power.
10.03.2025 12:57 — 👍 0 🔁 0 💬 1 📌 0
What exactly this tells us about the mechanisms is an open question. Compared to editing the input, you can get very different but still interpretable effects, e.g., in our work we basically found features that can be turned into style brushes by SAEing up.0.1 in SDXL Turbo sdxl-unbox.epfl.ch
10.03.2025 12:52 — 👍 0 🔁 0 💬 1 📌 0I did not read that paper with the random weights, but this is something I imagine impossible to do with random weights and thus probably not properly discussed in that work.
10.03.2025 00:54 — 👍 0 🔁 0 💬 0 📌 0This is different angle that makes interpretations of SAE features testable. „Do they affect the remaining forward pass in a way consistent with my interpretation?“
10.03.2025 00:52 — 👍 0 🔁 0 💬 2 📌 0So I agree that random NN features + learnt SAE is a powerful encoder and one has to be careful with the interpretation.
But Clement was talking about interventions that in a generative model modify its output also accordingly.
I think that it makes total sense that learning SAE features, which is not much different from computing clusters (at least for k=1), on some layer of a randomly initialised NN should pick up interesting features of your data. People used random features as basis for ML since the beginning.
10.03.2025 00:48 — 👍 0 🔁 0 💬 1 📌 0But I will say that SAE features often (especially with expansion factors common for the ones used in LLMs) are not good for interventions.
10.03.2025 00:14 — 👍 0 🔁 0 💬 0 📌 0Honestly, I think Clément made a great point here and it is hard to get what you mean with this response.
10.03.2025 00:02 — 👍 1 🔁 0 💬 2 📌 0Seems like you are not giving useful inputs tbh.
05.03.2025 03:51 — 👍 0 🔁 0 💬 0 📌 0


















