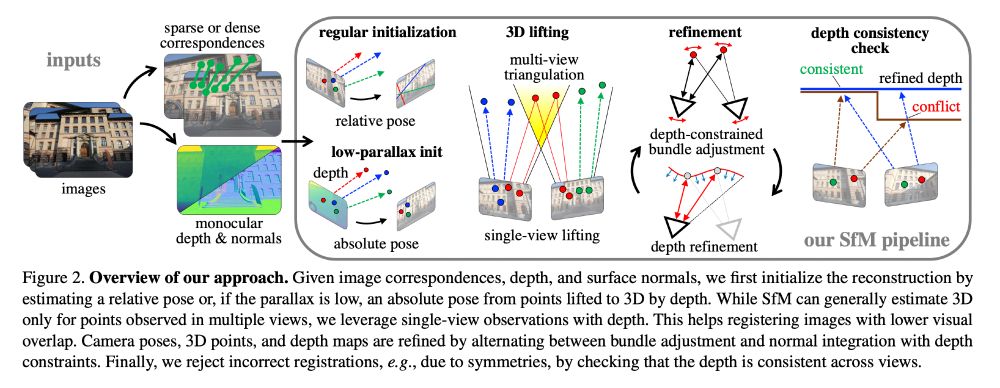
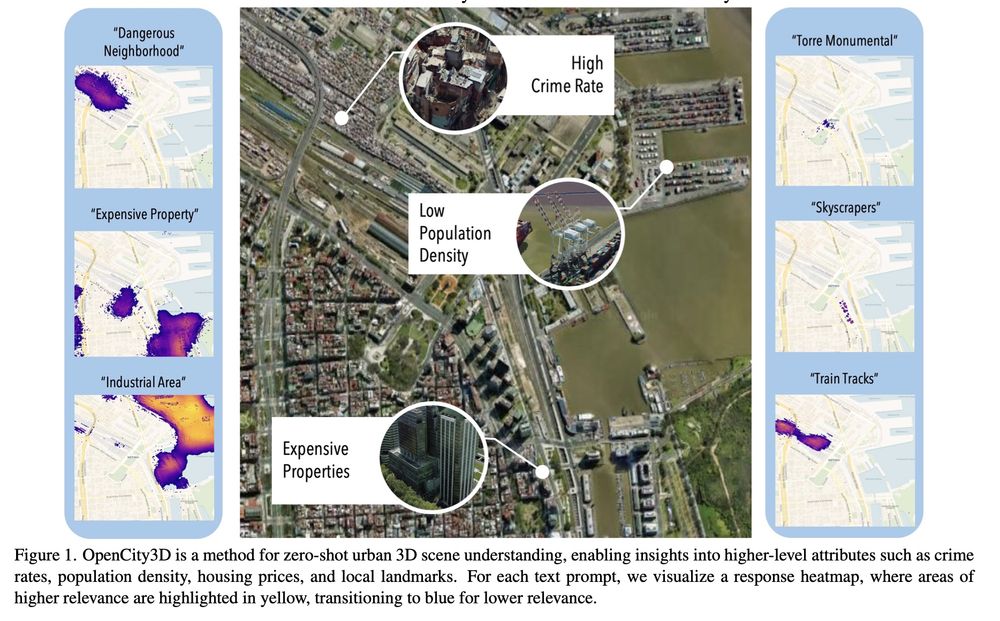
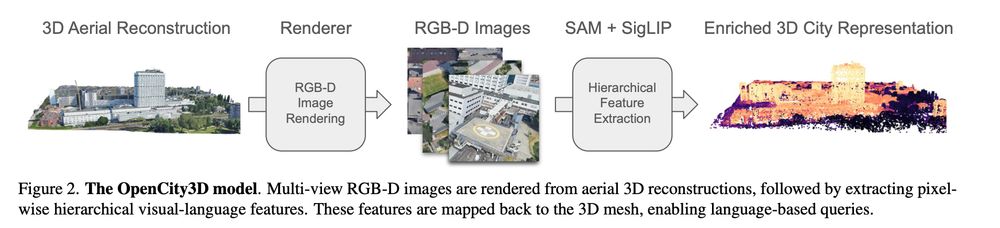
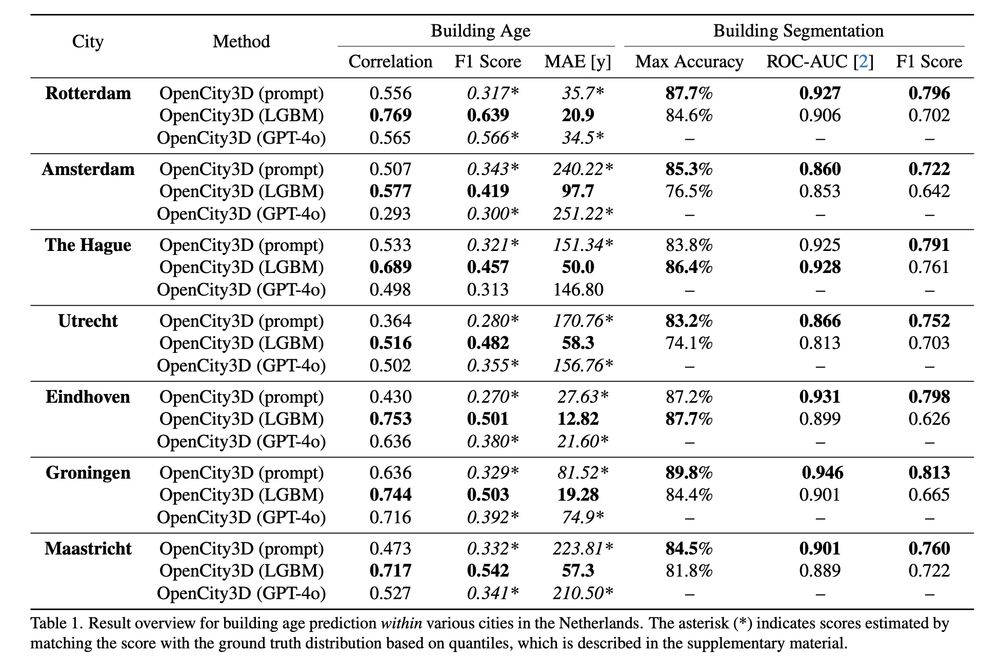
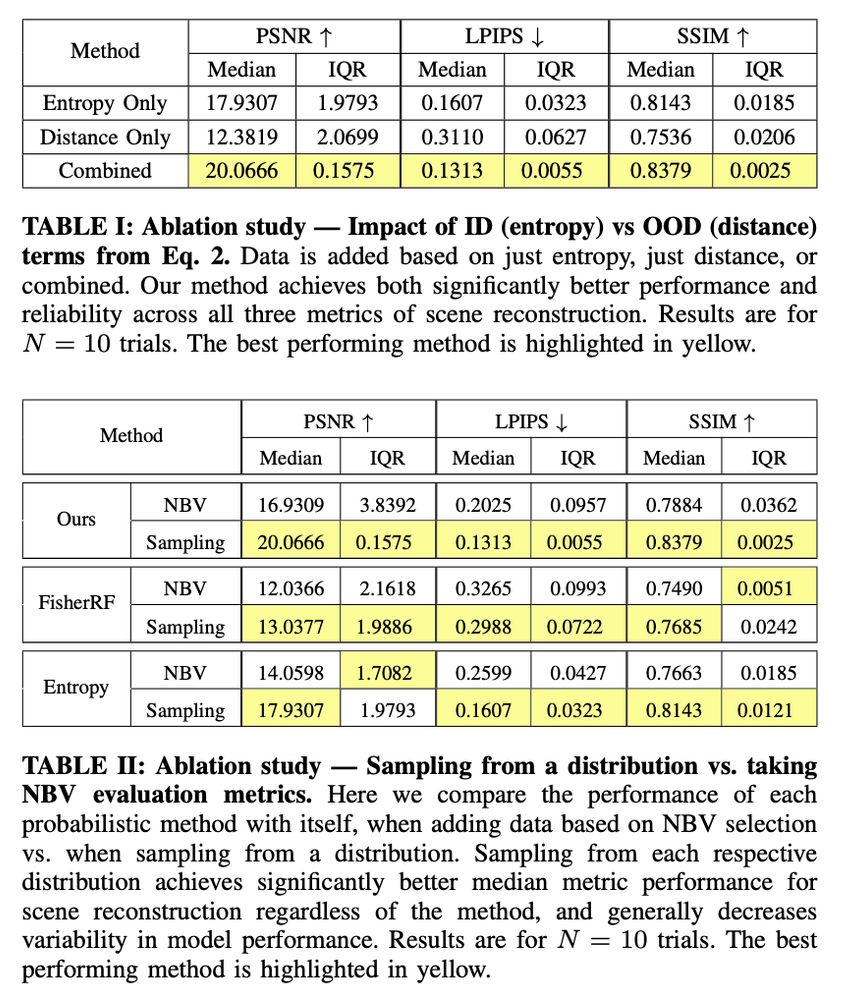
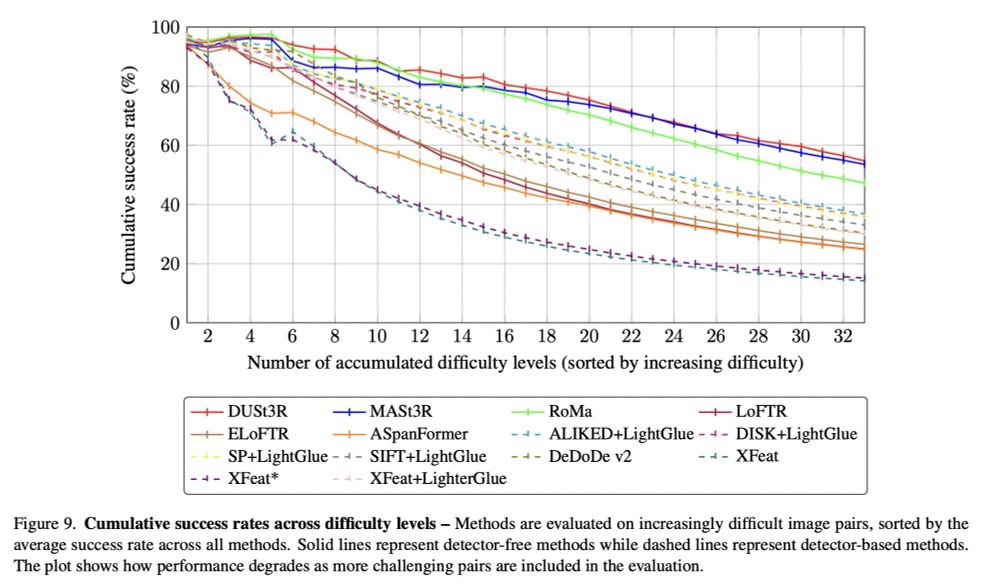
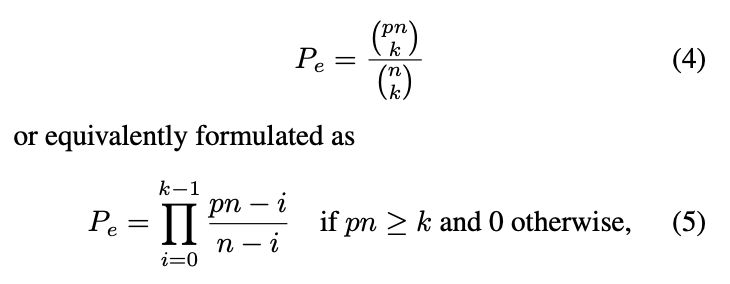Loft🆙 Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models. We achieve SotA upsampling results for DINOv2. Paper and code:
andrehuang.github.io/loftup-site/
26.04.2025 14:47 — 👍 28 🔁 3 💬 2 📌 0

Roboverse: unified simulation + dataset + benchmarking that supports many different robotics simulators including nvidia omniverse. One step closer to robotics getting its mmlu, maybe.
08.04.2025 02:05 — 👍 24 🔁 5 💬 0 📌 0
We have made some post-conference improvements of our CVPR'25 paper on end-to-end trained navigation. The agent has similar success rate but is more efficient, faster, less hesitant. Will be presented at CVPR in June.
arxiv.org/abs/2503.08306
Work by @steevenj7.bsky.social et al.
05.04.2025 14:38 — 👍 27 🔁 3 💬 2 📌 1
🔍Looking for a multi-view depth method that just works?
We're excited to share MVSAnywhere, which we will present at #CVPR2025. MVSAnywhere produces sharp depths, generalizes and is robust to all kind of scenes, and it's scale agnostic.
More info:
nianticlabs.github.io/mvsanywhere/
31.03.2025 12:52 — 👍 40 🔁 10 💬 2 📌 4

'We Are Eating the Earth' author Michael Grunwald, explores an important question, "How should writers like me approach four years of drill-baby-drill hostility to climate progress, and how should readers like you think about it?" @mikegrunwald.bsky.social
www.canarymedia.com/articles/foo...
20.03.2025 19:26 — 👍 6 🔁 2 💬 0 📌 0

Transformers, but without normalization layers
A simple alternative to normalization layers: the scaled tanh function, which they call Dynamic Tanh, or DyT.
14.03.2025 05:41 — 👍 15 🔁 2 💬 1 📌 0

Interviewing Eugene Vinitsky on self-play for self-driving and what else people do with RL
#13. Reinforcement learning fundamentals and scaling.
Another grad school RL friend on the pod! Lot's of non-reasoning RL talk here!
Interviewing Eugene Vinitsky (@eugenevinitsky.bsky.social) on self-play for self-driving and what else people do with RL
#13. Reinforcement learning fundamentals and scaling.
Post: buff.ly/8fLBJA6
YouTube: buff.ly/eJ6heSI
12.03.2025 14:09 — 👍 24 🔁 3 💬 0 📌 1
Amazing threads!
I wish to read more papers like this! Envying the reviewers
11.03.2025 06:39 — 👍 15 🔁 1 💬 1 📌 0
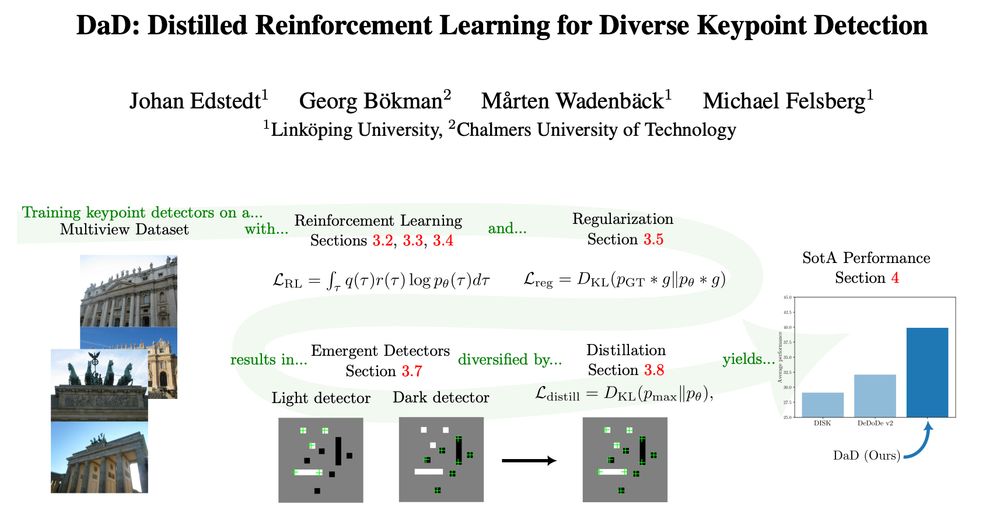
Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
11.03.2025 03:04 — 👍 62 🔁 11 💬 4 📌 3

We made a new keypoint detector named DaD, paper isn't up yet, but code and weights are:
github.com/Parskatt/dad
10.03.2025 07:53 — 👍 44 🔁 8 💬 7 📌 0
This is fantastic. My human sensorimotor skills barely let me do something like that.
10.03.2025 16:38 — 👍 1 🔁 0 💬 0 📌 0

Dataset Distillation (2018/2020)
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.
05.03.2025 00:23 — 👍 26 🔁 5 💬 2 📌 1

GitHub - yuanchenyang/smalldiffusion: Simple and readable code for training and sampling from diffusion models
Simple and readable code for training and sampling from diffusion models - yuanchenyang/smalldiffusion
smalldiffusion
A lightweight diffusion library for training and sampling from diffusion models. The core of this library for diffusion training and sampling is implemented in less than 100 lines of very readable pytorch code.
github.com/yuanchenyang...
05.03.2025 05:34 — 👍 20 🔁 4 💬 3 📌 0

Agentic Retrieval-Augmented Generation : A Survey On Agentic RAG
This repository complements the survey paper "Agentic Retrieval-Augmented Generation (Agentic RAG): A Survey On Agentic RAG".
github.com/asinghcsu/Ag...
03.03.2025 03:26 — 👍 13 🔁 1 💬 0 📌 0

The Blue Report
The top links on Bluesky, updated hourly
The Blue Report is amazing. The most clicked on articles are right here
theblue.report
01.03.2025 21:21 — 👍 20000 🔁 4657 💬 583 📌 265
A programming language empowering everyone to build reliable and efficient software.
Website: https://rust-lang.org/
Blog: https://blog.rust-lang.org/
Mastodon: https://social.rust-lang.org/@rust
Fostering a vibrant, inclusive, and global community dedicated to science and society. Join us: http://go.aps.org/2NWWEeY
Computer Vision research group @ox.ac.uk
Prime Minister of Canada and Leader of the Liberal Party | Premier ministre du Canada et chef du Parti libéral
markcarney.ca
☀️ Assistant Professor of Computer Science at CU Boulder 👩💻 NLP, cultural analytics, narratives, online communities 🌐 https://maria-antoniak.github.io 💬 books, bikes, games, art
Mathematician at UCLA. My primary social media account is https://mathstodon.xyz/@tao . I also have a blog at https://terrytao.wordpress.com/ and a home page at https://www.math.ucla.edu/~tao/
PhD candidate at UCSD. Prev: NVIDIA, Meta AI, UC Berkeley, DTU. I like robots 🤖, plants 🪴, and they/them pronouns 🏳️🌈
https://www.nicklashansen.com
Making robots part of our everyday lives. #AI research for #robotics. #computervision #machinelearning #deeplearning #NLProc #HRI Based in Grenoble, France. NAVER LABS R&D
europe.naverlabs.com
Professor, University of Tübingen @unituebingen.bsky.social.
Head of Department of Computer Science 🎓.
Faculty, Tübingen AI Center 🇩🇪 @tuebingen-ai.bsky.social.
ELLIS Fellow, Founding Board Member 🇪🇺 @ellis.eu.
CV 📷, ML 🧠, Self-Driving 🚗, NLP 🖺
Trending papers in Vision and Graphics on www.scholar-inbox.com.
Scholar Inbox is a personal paper recommender which keeps you up-to-date with the most relevant progress in your field. Follow us and never miss a beat again!
Founder @ Figure ($750M Backed), Cover (Weapon Detection), Archer Aviation (NYSE: ACHR), Vettery ($100M Exit)
Writing a data-driven newsletter about economics @ apricitas.io
Nuance? In this Economy
Full Employment Stan, Brazilian Coffee Tariff Victim |
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
I want to help build a world where we can all do our work, share our stories, and live our lives free from hate, harassment, and harm.
Newsletter: https://www.altrightdelete.news/
Work with me: hello@inviolable.ai
I am a marine conservation biologist studying sharks and a science writer. Posts are about science and the environment, science communication, and more! He/him
Hey, I'm a climate and energy writer / data analyst who focuses on corporate + govt accountability
Creator + curator of the Greensky feed: https://ketanjoshi.co/greensky/
Based in Oslo but write about US, Europe, Aus too - ketan.joshi85@gmail.com
Climate journalist based in NYC. Only speaking for myself. If the NYT has no haters I'm dead.
Tips? Reach me on Signal kendrawrites.04
Lapsed geologist, Chief Scientist at @oceana.bsky.social, dog mom. DC born and raised. Philly is my 2nd home.🖖
Skeets my own, *not* my employer’s. Mostly oceans + science + climate + policy. A little politics (sorry) and Phillies (not sorry).
Deputy Editor, Our World in Data
Senior Researcher, University of Oxford
Climate, energy, environment, all things data.