Fabian Falck, Teodora Pandeva, Kiarash Zahirnia, Rachel Lawrence, Richard Turner, Edward Meeds, Javier Zazo, Sushrut Karmalkar
A Fourier Space Perspective on Diffusion Models
https://arxiv.org/abs/2505.11278
19.05.2025 05:03 — 👍 1 🔁 1 💬 0 📌 0
We now have a whole YouTube video explaining our MINDcraft paper, check it out!
youtu.be/MeEcxh9St24
10.05.2025 20:08 — 👍 9 🔁 3 💬 1 📌 0
We define a new cryptographic system to allow user to show that he has a valid certificate from a public set of authorities, while hiding all the message, signature and identity of the authority
30.04.2025 01:06 — 👍 0 🔁 0 💬 0 📌 0
When using digital certificate, one usually gets signature from some authority, then show the message and signature for verification.
30.04.2025 01:06 — 👍 0 🔁 0 💬 1 📌 0

A visualization of compressed column evaluation in sparse autodiff. Here, columns 1, 2 and 5 of the matrix (in yellow) have no overlap in their sparsity patterns. Thus, they can be evaluated together by multiplication with a sum of basis vectors (in purple).
Wanna learn about autodiff and sparsity? Check out our #ICLR2025 blog post with @adrhill.bsky.social and Alexis Montoison. It has everything you need: matrices with lots of zeros, weird compiler tricks, graph coloring techniques, and a bunch of pretty pics!
iclr-blogposts.github.io/2025/blog/sp...
28.04.2025 17:07 — 👍 50 🔁 12 💬 1 📌 0

The DeepSeek Series: A Technical Overview
An overview of the papers describing the evolution of DeepSeek
Recently, my colleague Shayan Mohanty published a technical overview of the papers describing deepseek. He's now revised that article, adding more explanations to make it more digestible for those of us without a background in this field.
martinfowler.com/articles/dee...
21.04.2025 13:20 — 👍 62 🔁 14 💬 2 📌 1
Huawei's Dream 7B (Diffusion reasoning model), the most powerful open diffusion large language model to date.
Blog: hkunlp.github.io/blog/2025/dr...
02.04.2025 14:50 — 👍 24 🔁 4 💬 1 📌 2

A screenshot of the course description
I taught a grad course on AI Agents at UCSD CSE this past quarter. All lecture slides, homeworks & course projects are now open sourced!
I provide a grounding going from Classical Planning & Simulations -> RL Control -> LLMs and how to put it all together
pearls-lab.github.io/ai-agents-co...
04.03.2025 16:37 — 👍 38 🔁 9 💬 3 📌 1
David Picard
I updated my ML lecture material: davidpicard.github.io/teaching/
I show many (boomer) ML algorithms with working implementation to prevent the black box effect.
Everything is done in notebooks so that students can play with the algorithms.
Book-ish pdf export: davidpicard.github.io/pdf/poly.pdf
27.02.2025 19:09 — 👍 37 🔁 6 💬 0 📌 0

Our beginner's oriented accessible introduction to modern deep RL is now published in Foundations and Trends in Optimization. It is a great entry to the field if you want to jumpstart into RL!
@bernhard-jaeger.bsky.social
www.nowpublishers.com/article/Deta...
arxiv.org/abs/2312.08365
22.02.2025 19:32 — 👍 62 🔁 14 💬 2 📌 0
KS studies the Matrix Multiplication Verification Problem (MMV), in which you get three n x n matrices A, B, C (say, with poly(n)-bounded integer entries) and want to decide whether AB = C. This is trivial to solve in MM time O(n^omega) deterministically: compute AB and compare it with C. 2/
21.02.2025 04:50 — 👍 1 🔁 1 💬 1 📌 0

Introducing The AI CUDA Engineer: An agentic AI system that automates the production of highly optimized CUDA kernels.
sakana.ai/ai-cuda-engi...
The AI CUDA Engineer can produce highly optimized CUDA kernels, reaching 10-100x speedup over common machine learning operations in PyTorch.
Examples:
20.02.2025 01:50 — 👍 89 🔁 17 💬 3 📌 4
why on earth that somebody thought of doing this in the first place
17.02.2025 11:56 — 👍 0 🔁 0 💬 0 📌 0
Lorenzo Pastori, Arthur Grundner, Veronika Eyring, Mierk Schwabe
Quantum Neural Networks for Cloud Cover Parameterizations in Climate Models
https://arxiv.org/abs/2502.10131
17.02.2025 05:35 — 👍 1 🔁 1 💬 0 📌 0
Przemys{\l}aw Pawlitko, Natalia Mo\'cko, Marcin Niemiec, Piotr Cho{\l}da
Implementation and Analysis of Regev's Quantum Factorization Algorithm
https://arxiv.org/abs/2502.09772
17.02.2025 07:19 — 👍 1 🔁 1 💬 0 📌 0
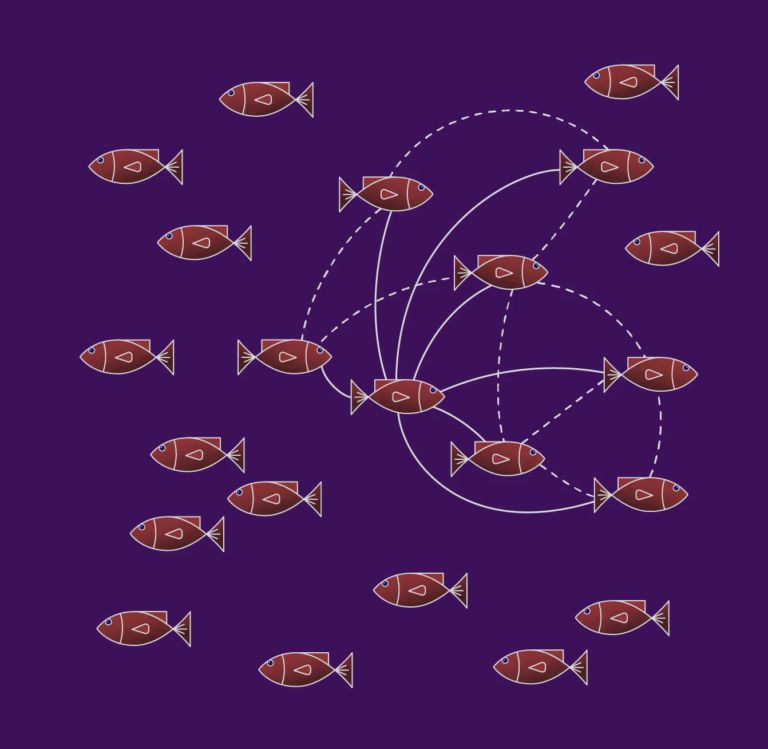
Digital illustration of a school of red fish with simple geometric features on a purple background. Some fish are connected by curved dashed and solid lines, suggesting interactions or relationships between them.
Enjoyed sharing our work on electric fish with @dryohanjohn.bsky.social⚡🐟 Their electric "conversations" help us build models to discover neural mechanisms of social cognition. Work led by Sonja Johnson-Yu & @satpreetsingh.bsky.social with Nate Sawtell
kempnerinstitute.harvard.edu/news/what-el...
14.02.2025 21:16 — 👍 43 🔁 9 💬 1 📌 1

🔥 Want to train large neural networks WITHOUT Adam while using less memory and getting better results? ⚡
Check out SCION: a new optimizer that adapts to the geometry of your problem using norm-constrained linear minimization oracles (LMOs): 🧵👇
13.02.2025 16:51 — 👍 17 🔁 6 💬 3 📌 1
Our new paper with @chrismlangdon is just out in @natureneuro.bsky.social! We show that high-dimensional RNNs use low-dimensional circuit mechanisms for cognitive tasks and identify a latent inhibitory mechanism for context-dependent decisions in PFC data.
www.nature.com/articles/s41...
12.02.2025 18:19 — 👍 71 🔁 24 💬 0 📌 1
I just checked the data of accepted papers at ICLR '25. The authors with most submission had 21 accepted out of 42 submitted. Oh well!
10.02.2025 20:50 — 👍 0 🔁 0 💬 0 📌 0

Also note that, instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss, avoiding complicating the calculation of the advantage.
@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
10.02.2025 04:32 — 👍 50 🔁 10 💬 3 📌 0
Restarting an old routine "Daily Dose of Good Papers" together w @vaibhavadlakha.bsky.social
Sharing my notes and thoughts here 🧵
23.11.2024 00:04 — 👍 61 🔁 8 💬 5 📌 3
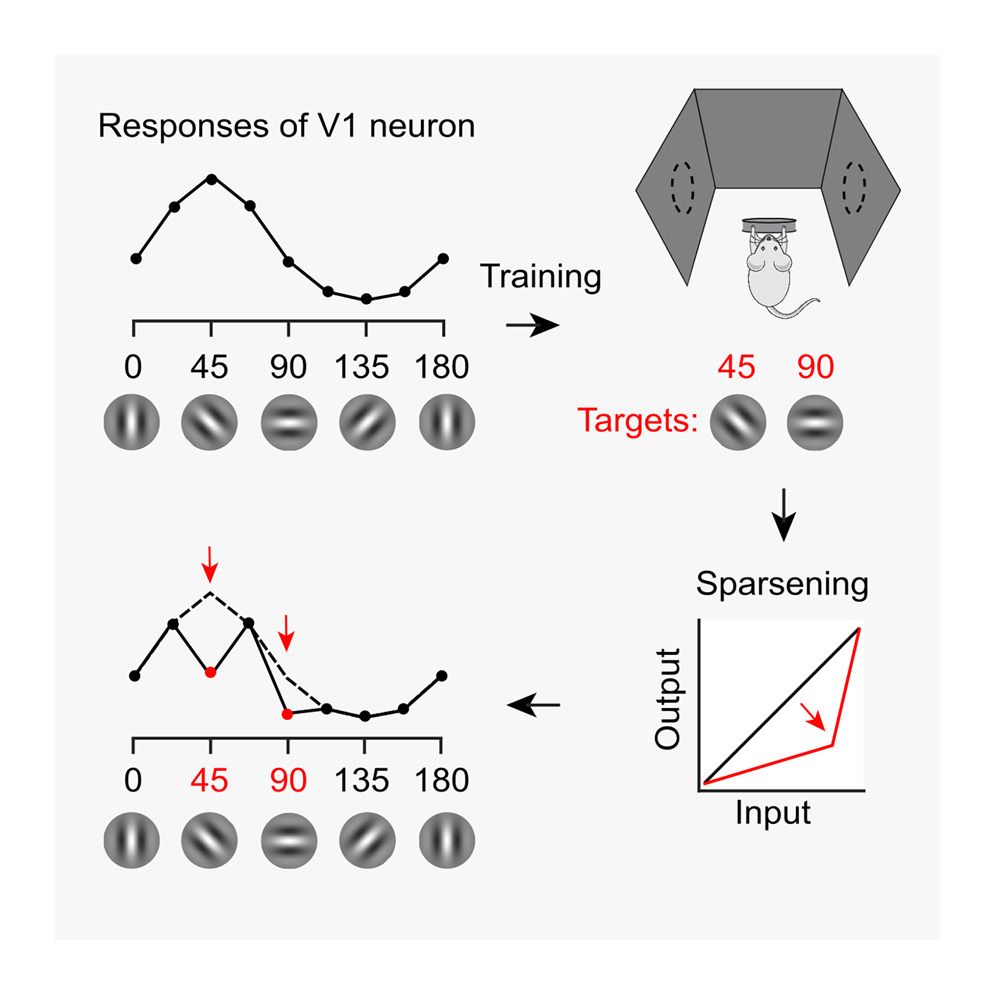
It's finally out!
Visual experience orthogonalizes visual cortical responses
Training in a visual task changes V1 tuning curves in odd ways. This effect is explained by a simple convex transformation. It orthogonalizes the population, making it easier to decode.
10.1016/j.celrep.2025.115235
02.02.2025 09:59 — 👍 153 🔁 44 💬 5 📌 2

group relative policy optimization (GRPO)
A friendly intro to GRPO. The algorithm is quite simple and elegant when you compare it to PPO, TRPO etc - and it's remarkable how well that worked out for deepseek R1.
superb-makemake-3a4.notion.site/group-relati...
01.02.2025 07:54 — 👍 33 🔁 4 💬 0 📌 1
Eugen Coroi, Changhun Oh
Exponential advantage in continuous-variable quantum state learning
https://arxiv.org/abs/2501.17633
30.01.2025 06:51 — 👍 1 🔁 1 💬 0 📌 0

Can Transformers Do Enumerative Geometry?
How can Transformers model and learn enumerative geometry? What is a robust procedure for using Transformers in abductive knowledge discovery within a mathematician-machine collaboration? In this work...
I am extremely happy to announce that our paper
Can Transformers Do Enumerative Geometry? (arxiv.org/abs/2408.14915) has been accepted to the
@iclr-conf.bsky.social!!
Congrats to my collaborators Alessandro Giacchetto at ETH Züruch and Roderic G. Corominas at Harvard.
#ICLR2025 #AI4Math #ORIGINS
23.01.2025 10:17 — 👍 12 🔁 3 💬 1 📌 2
PhD candidate studying quantum nanophotonics at UC Davis. Previously: PsiQuantum, Amazon CQC
phd student @ caltech | interested in quantum info, math education, watercolors, marine bio
https://reionize.github.io
PhD student @ Eisert Group, FU Berlin. Quantum Information Theory
MIT Physics PhD in Quantum Computing
IBM Quantum Research Intern
Previously Foxconn Research and Cambridge Maths
https://sites.google.com/view/adamwillsquantum/
Quantum Computing. PhD student at UTS.
PhD student @ USTC. I expect to graduate at the end of 2026 and am looking for a postdoc or research position on fault-tolerant quantum computation.
PhD Student in quantum foundations and quantum information
PhD Student @ University of Manchester, quantum info, stochastic processes, tensor networks and ε-machines
PhD student at Queen’s University Belfast
Quantum communication and correlations
(he/him)
Spends time thinking about quantum computing and molecules. PhD-candidate. Also interested in fields of practical relevance, like climate science.
Working on quantum error correction. Interested in maths, coding and spaced repetition. PhD student at Freie Universität Berlin.
PhD student working in quantum error-correction at IQC & Perimeter Institute, Waterloo.
Quantum memories PhD student @ Univeristy of Bristol, ADHD, Welsh, Bi 🏴 🏳️🌈
I simulate memories 'cuz mine doesn't work 🧠
PhD student @EPFL, previously @ETH
Interested in cryptography at large, post quantum and interactive proofs in particular.
Interista alla Prisco.
PhD in Computational Physics.
Interests are:
1. Nature and the state of mind.
2. Superconductivity.
3. BdG formulism.
4. Majorana modes and topological quantum computing.
Quantum Computing + Optimization + AI.
Postdoc@Pitt, PhD@Lehigh.
Physics PhD Candidate at UNSW. Interests are photon upconversion, perovskites and excitons
Theoretical physicist. Currently a PhD candidate at King's College London. Same handle on 🐦 and 🐘.
Personal website: https://sunwoo-kim.github.io
Foundational questions: Raclette or Fondue? 🧀🇨🇭 What is time without entropy? 🕒 || PhD student at quitphysics.info when not stuck hiking in nordic wilderness