How potentially practical is the theoretical performance?
27.06.2025 16:23 — 👍 0 🔁 0 💬 0 📌 0
YouTube video by Liquiform
Jorja Smith - Blue Lights (Macca & Loz Contreras Bootleg)
Run when you hear the sirens coming ...
www.youtube.com/watch?v=sanH...
12.06.2025 23:18 — 👍 0 🔁 0 💬 0 📌 0
Why is it not negative? Do they think trump will come to his senses and change his policy to prevent a recession?
29.04.2025 13:45 — 👍 2 🔁 0 💬 3 📌 0

Shared Content
A Plea for Ideological Laziness in an Age of Crisis
chatgpt.com/s/dr_680cd86...
26.04.2025 13:27 — 👍 1 🔁 0 💬 0 📌 0
I agree it's a hard problem and you need smarter people in power to tackle it.
05.04.2025 16:43 — 👍 0 🔁 0 💬 0 📌 0
How to finance the increased costs of manufacturing in the US? Where is the labour coming from, if you still have high employment? What about supply chains in a trade war with reciprocal tariffs?
05.04.2025 15:45 — 👍 0 🔁 0 💬 1 📌 0

Google Gemini 2.5 is the first public AI model to definitively beat the performance of human PhDs with access to Google on hard multiple choice problems inside their field of expertise (around 81%).
All AI tests are flawed, but GPQA Diamond has been a pretty good one.
& conducted independently.
03.04.2025 10:46 — 👍 72 🔁 13 💬 4 📌 2
Anyone else experiencing a sort of cognitive-emotional lag when working with AI? Like your emotional system isn't adapted to the productivity and switching so fast between such complex tasks? Leaving you with a feeling of being overwhelmed even though the tasks only take a few minutes?
03.04.2025 13:00 — 👍 1 🔁 0 💬 0 📌 0
What do companies get out of this process? I believe there are only 2 things you have to check:
1. Is the chemistry right with the team?
2. Is the person competent enough to solve a task and communicate the solution to you.
You don't need geniuses to work a corporate job.
31.03.2025 11:01 — 👍 0 🔁 0 💬 0 📌 0
And their beating OpenAI in price and features.
26.03.2025 15:14 — 👍 1 🔁 0 💬 0 📌 0
DeepSeek documented the changes to some extent.
Source: api-docs.deepseek.com/updates
25.03.2025 03:04 — 👍 10 🔁 2 💬 0 📌 0
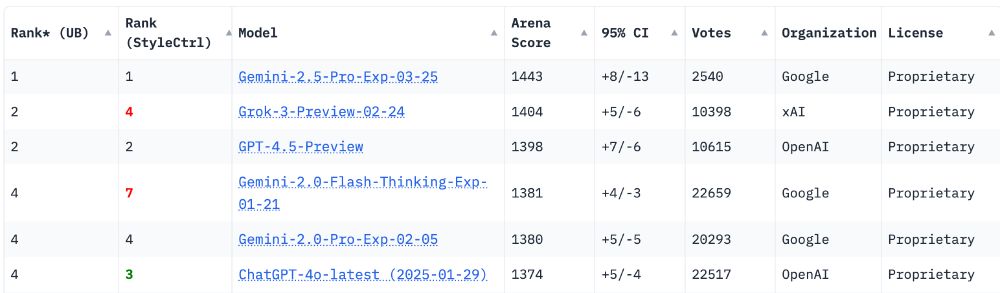

🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
25.03.2025 17:25 — 👍 215 🔁 65 💬 34 📌 11

DeepSeek's new V3 model (0324) is a major update in performance and license. MIT license will make it hugely impactful for research and open building. Though, many are ending up confused about if it is a "reasoning" model. The model is contrasted to their R1 model which is an only-reasoning model
25.03.2025 15:15 — 👍 19 🔁 2 💬 2 📌 0

Don't get high on your own supply, Tay Musk
23.03.2025 09:20 — 👍 0 🔁 0 💬 0 📌 0

Tencent Hunyuan-T1, their AI reasoning model. Powered by Hunyuan TurboS, it's built for speed, accuracy, and efficiency.
✅ Hybrid-Mamba-Transformer MoE Architecture – The first of its kind for ultra-large-scale reasoning
✅ Strong Logic & Concise Writing – Precise following of complex instructions
21.03.2025 16:35 — 👍 10 🔁 3 💬 1 📌 1
I think people have to discern between the unbased promises of super human AGI and the actual usability revolution that is happening through LLMs. Now everyone can access complex computing through natural language, we haven't adjusted to this paradigm change yet.
21.03.2025 07:22 — 👍 3 🔁 0 💬 0 📌 0
It is! After testing the current 2.0 gemini models on my RAG tasks and also the current top, pro or preview models from several vendors, i'm not sure how they will compete with Google in the long run given these prices.
21.03.2025 02:24 — 👍 0 🔁 0 💬 0 📌 0
Google's gemini 2.0 models are underrated for RAG applications, first benchmarks look really promising.
20.03.2025 15:23 — 👍 0 🔁 0 💬 0 📌 0
This feels a bit like the 2008 financial crisis stock market, but instead of waiting for political signals on which bank is being saved, you wait for the orange man to wake up at 15:30 cet and spew his crazy declarations on his "social" media platform.
18.03.2025 10:01 — 👍 1 🔁 0 💬 0 📌 0
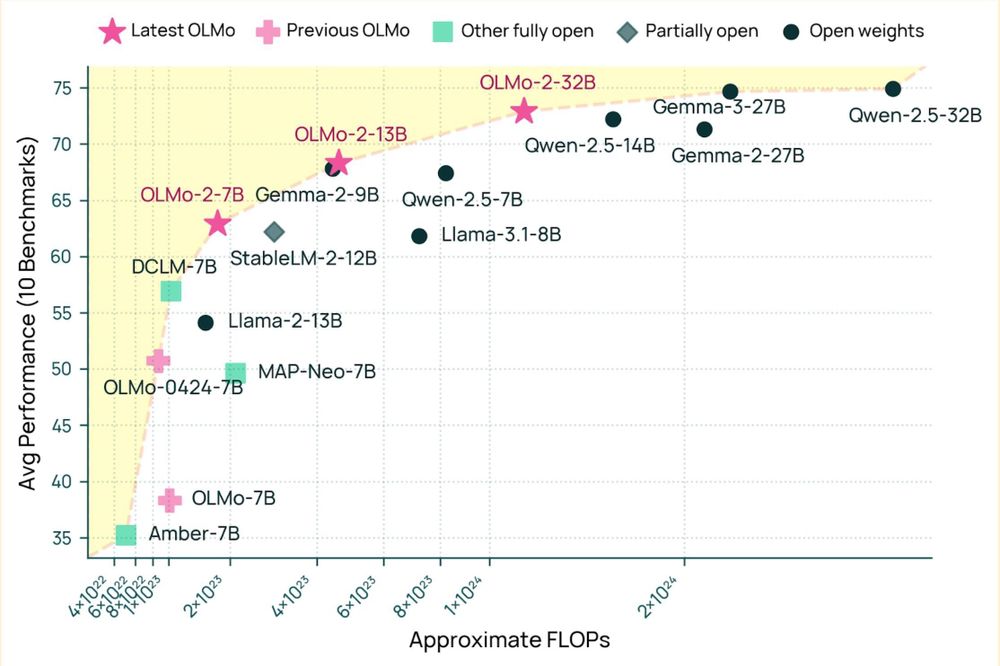
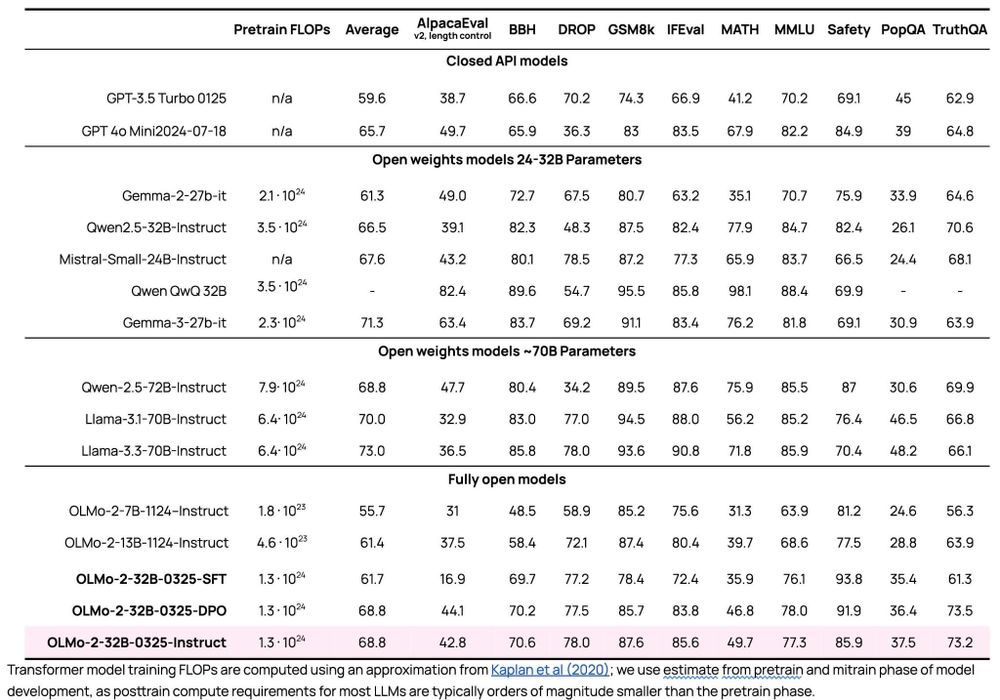
A very exciting day for open-source AI! We're releasing our biggest open source model yet -- OLMo 2 32B -- and it beats the latest GPT 3.5, GPT 4o mini, and leading open weight models like Qwen and Mistral. As usual, all data, weights, code, etc. are available.
13.03.2025 18:16 — 👍 141 🔁 37 💬 5 📌 3
"too incompetent to realize that they’re incompetent"
11.03.2025 13:20 — 👍 0 🔁 0 💬 0 📌 0
Total shitshow of incompetence.
you all know immediately who i mean.
10.03.2025 07:08 — 👍 0 🔁 0 💬 0 📌 0
In a shocking turn of events, many of the people who said they wanted "free speech" actually just wanted to be the ones in charge of which speech is free.
10.03.2025 02:44 — 👍 13030 🔁 2345 💬 244 📌 64
Makes intuitive sense how would the model know which tokens to pay attention to while embedding the needle in advance. "Noise" is therefore equally important during indexing. 4k tokens embeddings would only make sense if the needle is so complex it takes up 4k tokens.
08.03.2025 08:23 — 👍 1 🔁 0 💬 0 📌 0
YouTube video by RudimentalVEVO
Rudimental, Skepsis - Vex (Official Audio) ft. MIST, Popcaan
vibe www.youtube.com/watch?v=x8Va...
06.03.2025 09:22 — 👍 0 🔁 0 💬 0 📌 0
Newsletter: Microsoft pulled back on over a gigawatt of planned data center capacity, suggesting that they do not think there is a growth future in generative AI. Meanwhile, SoftBank, the only company that can afford to fund OpenAI, has to take out loans to do so.
www.wheresyoured.at/power-cut/
03.03.2025 17:17 — 👍 2611 🔁 585 💬 50 📌 91
Hi, I'm Hendry
bi-spectral
whimsical nerdcore
https://www.youtube.com/@HGModernism
Professor a NYU; Chief AI Scientist at Meta.
Researcher in AI, Machine Learning, Robotics, etc.
ACM Turing Award Laureate.
http://yann.lecun.com
CS PhD Student @University of Washington, CSxPhilosophy @Dartmouth College
Interested in MARL, Social Reasoning, and Collective Decision making in people, machines, and other organisms
kjha02.github.io
News and analysis with a global perspective. We’re here to help you understand the world around you. Subscribe here: https://econ.st/4fAeu4q
Doting grandmother, among other things.
PhD student @LUH-AI
Researching the utilization of LLMs for AutoML.
He/him and they/them are both fine.
Opinions are my own :)
Retired software engineer. AI enthusiast. Deadhead. I implemented Bash's regex operator (=~). My Signal user ID is franl.99.
Hugo Award-winning author, narrator, and professional puppeteer. Also has a talking cat. My latest title, Apprehension, is available wherever books are sold.
The real jbouie. Columnist for the New York Times Opinion section. Co-host of the Unclear and Present Danger podcast. b-boy-bouiebaisse on TikTok. jbouienyt on Twitch. National program director of the CHUM Group.
Send me your mutual aid requests.
A LLN - large language Nathan - (RL, RLHF, society, robotics), athlete, yogi, chef
Writes http://interconnects.ai
At Ai2 via HuggingFace, Berkeley, and normal places
Cohost of The Odd Lots Podcast
Singer and guitarist in Light Sweet Crude
@nytimes correspondent writing about the Federal Reserve and the US economy. Previously @FT, @TheEconomist, @BloombergTV. colby.smith@nytimes.com
Fed and economy reporter with @reuters.com, ex-Wall Street Journal. Failed musician, guitar holdout, I really like pedals.
Independent and non-doctrinal international economics think-tank with a mission to improve economic policy.
www.bruegel.org
Director, @stanforddel.bsky.social
Professor Stanford Institute for Human-centered AI, SIEPR, Stanford department of Economics and GSB
Author https://amazon.com/Second-Machine-Age-Prosperity-Technologies/dp/0393350649
Ex NY Times, now author of Substack Paul Krugman. Nobel laureate and, according to Donald Trump, "Deranged BUM"
cybersecurity weather man. scanning the horizons for cloudy cyber. Expert at nothing except computer rubbish. Anti-ransomware since 2015.
Computational Linguists—Natural Language—Machine Learning

























