How can we better understand how models make predictions and which components of a training dataset are shaping their behaviors? In April we introduced OLMoTrace, a feature that lets you trace the outputs of language models back to their full training data in real time. 🧵
30.06.2025 17:37 — 👍 9 🔁 4 💬 1 📌 0

As we’ve been working towards training a new version of OLMo, we wanted to improve our methods for measuring the Critical Batch Size (CBS) of a training run, to unlock greater efficiency. but we found gaps between the methods in the literature and our practical needs for training OLMo. 🧵
03.06.2025 16:43 — 👍 16 🔁 3 💬 1 📌 1

I’m thrilled to share RewardBench 2 📊— We created a new multi-domain reward model evaluation that is substantially harder than RewardBench, we trained and released 70 reward models, and we gained insights about reward modeling benchmarks and downstream performance!
02.06.2025 23:41 — 👍 22 🔁 6 💬 2 📌 1

📢We’re taking your questions now on Reddit for tomorrow’s AMA!
Ask us anything about OLMo, our family of fully-open language models. Our researchers will be on hand to answer them Thursday, May 8 at 8am PST.
07.05.2025 16:46 — 👍 3 🔁 2 💬 1 📌 0
The story of OLMo, our Open Language Model, goes back to February 2023 when a group of researchers gathered at Ai2 and started planning. What if we made a language model with state-of-the-art performance, but we did it completely in the open? 🧵
06.05.2025 20:55 — 👍 16 🔁 3 💬 1 📌 0

A bar graph comparing average performance (10 Tasks) across OLMo 2 1B, SmolLM2 1.7B, Gemma 3 1B, Llama 3.2 1B, and Qwen 2.5 1.5B. The highest performance is 42.7, achieved by OLMo 2 1B.
We're excited to round out the OLMo 2 family with its smallest member, OLMo 2 1B, surpassing peer models like Gemma 3 1B or Llama 3.2 1B. The 1B model should enable rapid iteration for researchers, more local development, and a more complete picture of how our recipe scales.
01.05.2025 13:01 — 👍 43 🔁 10 💬 1 📌 4

Ask Us Anything about our Open Language Model, OLMo
Have questions? We’re an open book!
We’re excited to host an AMA to answer your Qs about OLMo, our family of open language models.
🗓️ When: May 8, 8-10 am PT
🌐 Where: r/huggingface
🧠 Why: Gain insights from our expert researchers
Chat soon!
01.05.2025 17:57 — 👍 13 🔁 4 💬 1 📌 3

"With OLMoTrace, we’re actually bringing accessibility to openness, enabling everybody to start looking into the inner workings of the relationships between the input and output of these models." - Ali Farhadi, Ai2 CEO
Last week we released OLMoTrace as part of #GoogleCloudNext
14.04.2025 19:30 — 👍 6 🔁 2 💬 1 📌 0
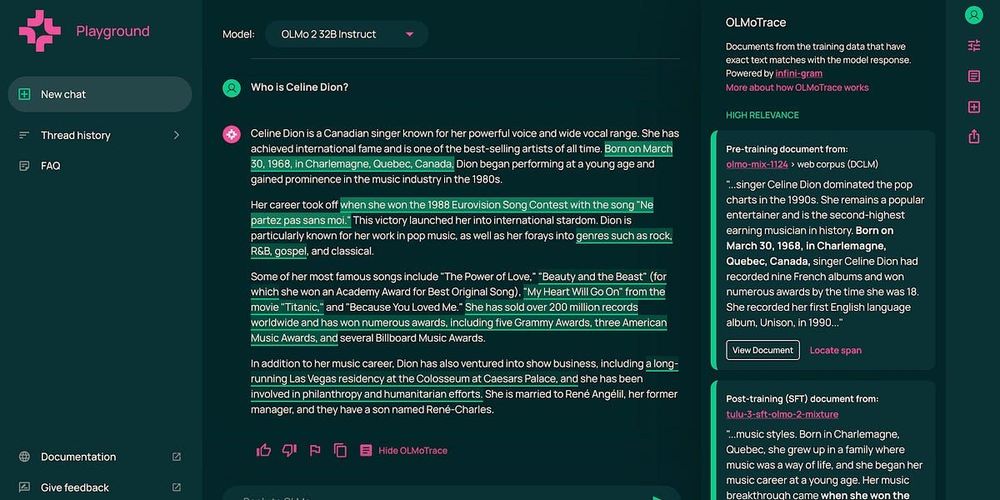
Looking at the training data
On building tools where truly open-source models can shrine (OLMo 2 32B Instruct, for today). OLMoTrace lets you poke around.
Ai2 launched a new tool where your responses from OLMo get mapped back to related training data. We're using this actively to improve our post-training data and hope many others will use it for understanding and transparency around leading language models!
Some musings:
09.04.2025 20:12 — 👍 48 🔁 4 💬 2 📌 5

Lead OLMoTrace researcher Jiacheng Liu at Ai2's Google Cloud Next booth.

The entrance to the Vertex AI Model Garden at Google Cloud Next.

A QR code leading to the story of Google Cloud and Ai2's partnership sitting near a faux fire pit.

Ai2 COO Sophie Lebrecht talks to visitors at Ai2's booth at Google Cloud Next.
Coming to you live from #GoogleCloudNext Day 2!
📍 Find us at the Vertex AI Model Garden inside the Google Cloud Showcase - try out OLMoTrace, and take a step inside our fully open AI ecosystem.
10.04.2025 16:24 — 👍 3 🔁 1 💬 1 📌 0

Ali Farhadi speaking on stage at a fireside chat
"OLMoTrace is a breakthrough in AI development, setting a new standard for transparency and trust. We hope it will empower researchers, developers, and users to build with confidence—on models they can understand and trust." - CEO Ali Farhadi at tonight's chat with Karen Dahut #GoogleCloudNext
10.04.2025 01:23 — 👍 9 🔁 2 💬 0 📌 0
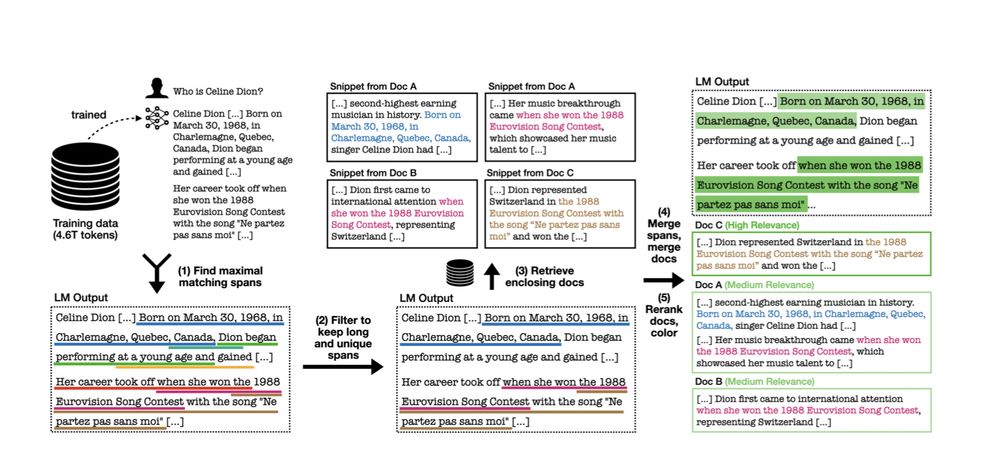
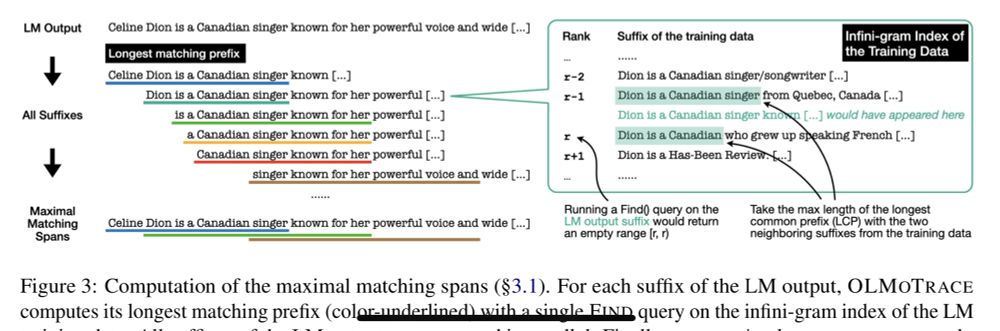
OLMoTrace is powered by my previous work infini-gram, with some innovative algorithmic twists. Really proud to turn an academic research project into a real LLM product, it’s been a truly amazing experience.
Check out infini-gram: infini-gram.io
09.04.2025 15:56 — 👍 2 🔁 0 💬 0 📌 0
Try OLMoTrace in Ai2 Playground with our OLMo 2 models: playground.allenai.org
If OLMoTrace gives you new insight into how LLMs behave, we’d love you to share your use case! 💡Take a screenshot, post the thread link if you like, and don’t forget to tag
@allen_ai
09.04.2025 13:37 — 👍 3 🔁 0 💬 1 📌 0
Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
09.04.2025 13:37 — 👍 41 🔁 5 💬 1 📌 2
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
09.04.2025 13:16 — 👍 59 🔁 12 💬 4 📌 13
📰Google Cloud moves deeper into open source AI with Ai2 partnership:
“Many were wary of using AI models unless they had full transparency into models’ training data and could customize the models completely. Ai2’s models allow that.”
08.04.2025 17:50 — 👍 5 🔁 1 💬 1 📌 0
(4/4) Searching in OLMo 2's training data is now available in both our web interface and the API endpoint.
Plus, OLMo 2 32B Instruct is a very strong model. Let's do real science with it 🧪
08.04.2025 14:50 — 👍 0 🔁 0 💬 0 📌 0
(3/4) We know the pain point in LLM research in academia: We don't know what's in the training data of these LLMs (GPT, Llama, etc) and what's not; we can only speculate.
So we made the full training data of OLMo 2 and OLMoE searchable, including pre-training and post-training.
08.04.2025 14:50 — 👍 0 🔁 0 💬 1 📌 0
GitHub - liujch1998/infini-gram
Contribute to liujch1998/infini-gram development by creating an account on GitHub.
(2/4) Check out the source code of infini-gram here: github.com/liujch1998/infini-gram
If you are new to infini-gram, you might want to start with exploring our web interface infini-gram.io/demo and API endpoint infini-gram.io/api_doc
08.04.2025 14:50 — 👍 0 🔁 0 💬 1 📌 0
As infini-gram surpasses 500 million API calls, today we're announcing two exciting updates:
1. Infini-gram is now open-source under Apache 2.0!
2. We indexed the training data of OLMo 2 models. Now you can search in the training data of these strong, fully-open LLMs.
🧵 (1/4)
08.04.2025 14:50 — 👍 1 🔁 0 💬 1 📌 1
Stay tuned... Wednesday, at #GoogleCloudNext and online 👀
07.04.2025 18:59 — 👍 2 🔁 1 💬 0 📌 0

A list of paper authors for 2 OLMo 2 Furious.
Buckle your seatbelt — we've released the OLMo 2 paper to kick off 2025 🔥. Including 50+ pages on 4 crucial components of the LLM development pipeline.
06.01.2025 20:28 — 👍 37 🔁 6 💬 1 📌 0

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
03.01.2025 16:02 — 👍 69 🔁 17 💬 2 📌 1
Yes we’ve read your paper and there’s so many interesting findings! Let’s grab coffee at Neurips
09.12.2024 20:11 — 👍 2 🔁 0 💬 0 📌 0
(8/n) ... and senior authors @soldni.bsky.social @nlpnoah.bsky.social @mechanicaldirk.bsky.social Pang Wei Koh, Jesse Dodge, Hanna Hajishirzi
09.12.2024 17:07 — 👍 0 🔁 0 💬 0 📌 0
(7/n) This work wouldn’t have been possible without my awesome co-first author @akshitab.bsky.social, wonderful colleagues @awettig.bsky.social @davidheineman.com @oyvind-t.bsky.social @ananyahjha93.bsky.social ...
09.12.2024 17:07 — 👍 0 🔁 0 💬 1 📌 0
(6/n) Compared to existing work, our method accurately predicts performance on individual tasks, is designed to work on arbitrary overtrained regimes, and is compute-efficient.
Paper link: arxiv.org/abs/2412.04403
09.12.2024 17:07 — 👍 2 🔁 0 💬 1 📌 0
(5/n) We have loads of interesting analyses! Check out our paper to find out:
* variance analysis of task accuracy and its impact on prediction error
* impact of using even less compute to make prediction
* ablating the many design choices in our method and exploring alternatives
09.12.2024 17:07 — 👍 0 🔁 0 💬 1 📌 0
(4/n) We can predict the task accuracy of OLMo 2 7B and 13B (after pretraining and before mid-training) within an absolute error of 2 points on four tasks – MMLU, HellaSwag, PIQA, and Social IQa. Error on other tasks is a bit higher, and we aim to improve them in future work.
09.12.2024 17:07 — 👍 0 🔁 0 💬 1 📌 0
Research Engineer at Ai2
https://akshitab.github.io/
Research scientist at Meta on the llama team
Thinking about language models
Past: PhD at NYU, fellow at Harvard’s Kempner Institute
Breakthrough AI to solve the world's biggest problems.
› Join us: http://allenai.org/careers
› Get our newsletter: https://share.hsforms.com/1uJkWs5aDRHWhiky3aHooIg3ioxm
Ph.D. student at @jhuclsp, human LM that hallucinates. Formerly @MetaAI, @uwnlp, and @AWS they/them🏳️🌈 #NLProc #NLP Crossposting on X.
Science of language models @uwnlp.bsky.social and @ai2.bsky.social with @PangWeiKoh and @nlpnoah.bsky.social. https://ianmagnusson.github.io
5th year PhD student at UW CSE, working on Security and Privacy for ML
PhD student @ MIT | Previously PYI @ AI2 | MS'21 BS'19 BA'19 @ UW | zhaofengwu.github.io
Will irl - PhD student @ NYU on the academic job market!
Using complexity theory and formal languages to understand the power and limits of LLMs
https://lambdaviking.com/ https://github.com/viking-sudo-rm
A LLN - large language Nathan - (RL, RLHF, society, robotics), athlete, yogi, chef
Writes http://interconnects.ai
At Ai2 via HuggingFace, Berkeley, and normal places
My account is @soldaini.net
AI professor at Caltech. General Chair ICLR 2025.
http://www.yisongyue.com
PhDing at Princeton Language and Intelligence. Working on memory / control / agent.
Prev: Meta AI, ASAPP, Cornell, NTU (Taiwan)
howard50b.github.io
Postdoc in AI at the Allen Institute for AI & the University of Washington.
🌐 https://valentinapy.github.io
I (try to) do NLP research. Antipodean abroad.
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
Research in NLP (mostly LM interpretability & explainability).
Assistant prof at UMD CS + CLIP.
Previously @ai2.bsky.social @uwnlp.bsky.social
Views my own.
sarahwie.github.io
PhD student in Information Science @uwischool.bsky.social | Human-AI interaction & Cognitive Psych | Middlebury College ‘22
katelynmei.com
Ph.D. @WisconsinCS @WIDiscovery | Previously BS/MS @uwcse, @Meta @Google
Research: AI for Creativity, Active Learning, Data Efficient Learning (jifanz.github.io)
📖 PhD Student in Robotics at ETH Zürich
🔍 Computer Vision, 3D Reconstruction, Structure-from-Motion, SLAM, Geometry























