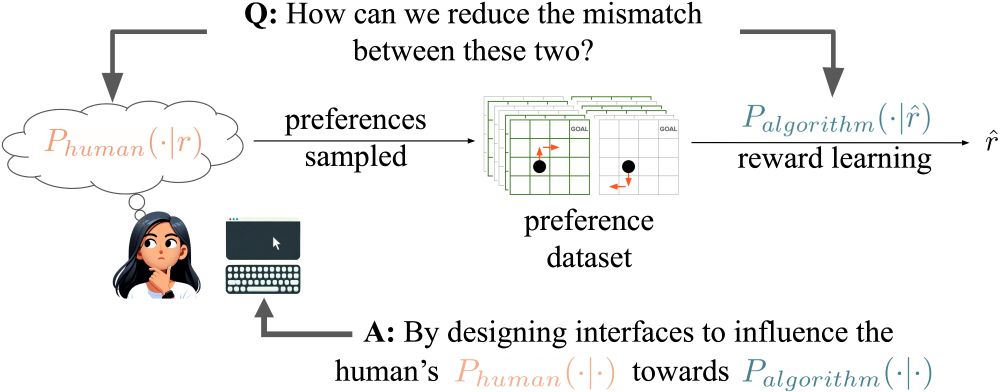
LLMs' sycophancy issues are a predictable result of optimizing for user feedback. Even if clear sycophantic behaviors get fixed, AIs' exploits of our cognitive biases may only become more subtle.
Grateful our research on this was featured in @washingtonpost.com by @nitasha.bsky.social!

Micah Carroll
@micahcarroll.bsky.social
PhD student @ berkeley. https://micahcarroll.github.io/
76 Followers |
36 Following |
1 Posts |
Joined: 21.06.2023 |
1.3257