Happy to find that I've been selected as an Outstanding Reviewer for CVPR 2025!
11.05.2025 12:44 — 👍 3 🔁 0 💬 0 📌 0
📢 New paper CVPR 25!
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
05.05.2025 13:00 — 👍 28 🔁 20 💬 1 📌 1

⏰ Heads up! The deadline for two #CVPR2025 Autonomous Grand Challenge tracks is May 10th, 2025:
1️⃣ NAVSIM v2 Challenge: huggingface.co/spaces/AGC20...
2️⃣ World Model Challenge by 1X: huggingface.co/spaces/1x-te...
28.04.2025 09:41 — 👍 9 🔁 6 💬 1 📌 0
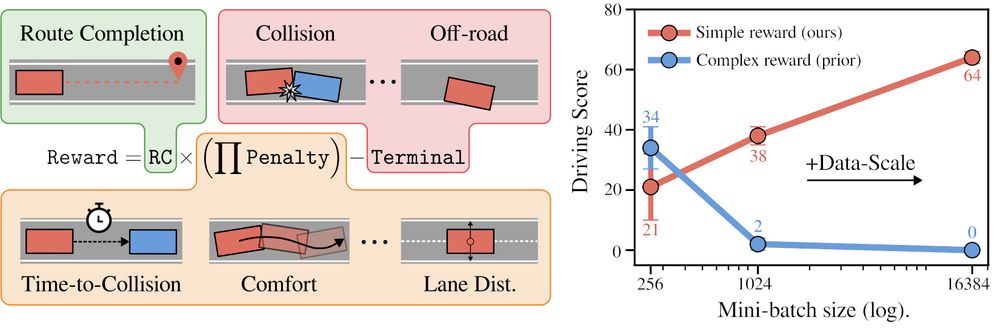
Introducing CaRL: Learning Scalable Planning Policies with Simple Rewards
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
28.04.2025 15:17 — 👍 25 🔁 14 💬 0 📌 1
Sometimes you choose aesthetics over aligned maximum at all axes 😂
27.04.2025 03:01 — 👍 0 🔁 0 💬 1 📌 0
Loft🆙 Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models. We achieve SotA upsampling results for DINOv2. Paper and code:
andrehuang.github.io/loftup-site/
26.04.2025 14:47 — 👍 28 🔁 3 💬 2 📌 0
Sharing another video showing how LoftUp significantly improves DINOv2 features! Works like a charm!
Try it out:
Code: github.com/andrehuang/l...
Paper: arxiv.org/abs/2504.14032
26.04.2025 07:52 — 👍 9 🔁 2 💬 0 📌 0
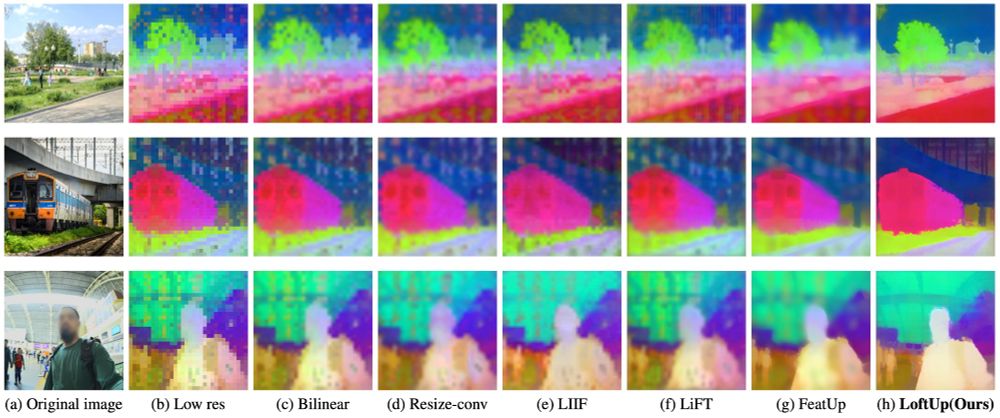
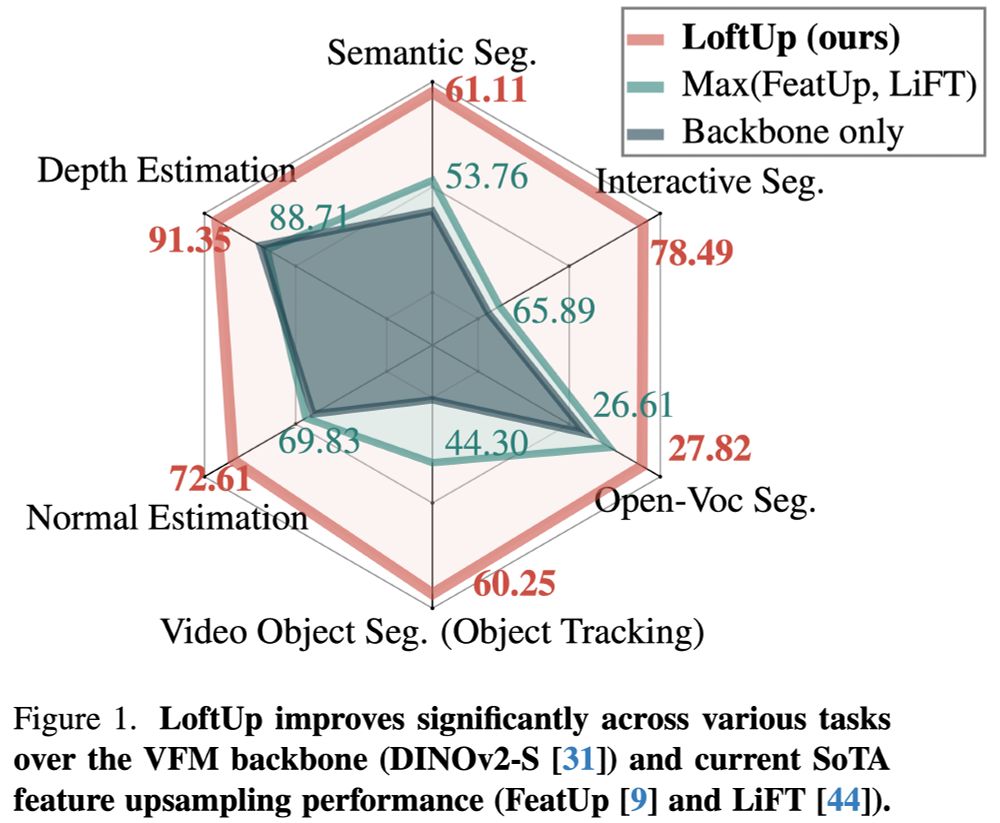
Excited to introduce LoftUp!
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
22.04.2025 07:55 — 👍 19 🔁 5 💬 0 📌 0
How much 3D do visual foundation models (VFMs) know?
Previous work requires 3D data for probing → expensive to collect!
#Feat2GS @cvprconference.bsky.social 2025 - our idea is to read out 3D Gaussains from VFMs features, thus probe 3D with novel view synthesis.
🔗Page: fanegg.github.io/Feat2GS
31.03.2025 16:06 — 👍 24 🔁 7 💬 1 📌 1
🦣Easi3R: 4D Reconstruction Without Training!
Limited 4D datasets? Take it easy.
#Easi3R adapts #DUSt3R for 4D reconstruction by disentangling and repurposing its attention maps → make 4D reconstruction easier than ever!
🔗Page: easi3r.github.io
01.04.2025 15:21 — 👍 22 🔁 3 💬 2 📌 4
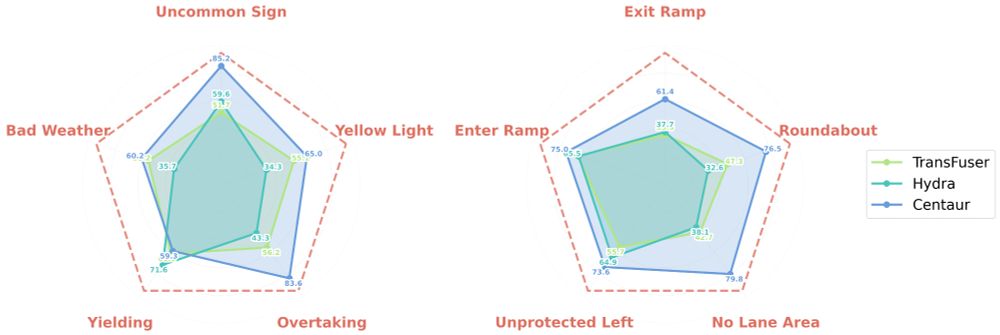
🐎 Centaur, our first foray into test-time training for end-to-end driving. No retraining needed, just plug-and-play at deployment given a trained model. Also, theoretically nearly no overhead in latency with some clever use of buffers. Surprising how effective this is! arxiv.org/abs/2503.11650
17.03.2025 11:03 — 👍 12 🔁 7 💬 1 📌 1

🚀 Names matter! We show that better class names in open-vocabulary segmentation benchmarks greatly improve dataset quality and boost model performance. RENOVATE your dataset labels with our automatic framework! #AI #ComputerVision #NeurIPS24
andrehuang.github.io/renovate/
26.02.2025 14:45 — 👍 32 🔁 6 💬 1 📌 0
Synchronization is ubiquitous in nature and a key mechanism for information processing in the brain. We introduce AKOrN as a dynamical alternative to threshold units, which can be combined with MLPs, CNNs or Transformers. ICLR'25 Oral. Project page: takerum.github.io/akorn_projec...
12.02.2025 14:07 — 👍 47 🔁 11 💬 2 📌 2
Official account for IEEE/CVF Conference on Computer Vision & Pattern Recognition. Hosted by @CSProfKGD with more to come.
📍🌎 🔗 cvpr.thecvf.com 🎂 June 19, 1983
Defence, 3D computer vision, EW, GNSS, open source and C++. #NAFO
R&D Lead Engineer at Milrem Robotics.
github.com/valgur
https://katrinrenz.de/
LLMs + Autonomous Driving.
PhD Student at Uni Tübingen with Andreas Geiger.
Previously at Wayve & Uni Oxford, VGG.
PhD Student at Westlake University. 3D/4D Reconstruction, Virtual Humans.
fanegg.github.io
Professor of Computer Vision and AI at TU Munich, Director of the Munich Center for Machine Learning mcml.ai and of ELLIS Munich ellismunich.ai
cvg.cit.tum.de
📖 PhD student in TUM CVG of Prof. Daniel Cremers @dcremers.bsky.social
🤖 3D Computer Vision, SLAM, SfM, 3D Reconstruction
🎓 MSc CS at ETH Zurich
🏠 ganlinzhang.xyz
PhD student at ETH Zurich & University of Tübingen, working on 3D Vision
https://haofeixu.github.io/
ELLIS PhD Student in Computer Vision at TUM with Daniel Cremers and Christian Rupprecht (Oxford), fwmb.github.io, prev. Research Intern at Meta GenAI
@ellis.eu Ph.D. Student @CVG (@dcremers.bsky.social), @visinf.bsky.social & @oxford-vgg.bsky.social | Ph.D. Scholar @zuseschooleliza.bsky.social | M.Sc. & B.Sc. @tuda.bsky.social | Prev. @neclabsamerica.bsky.social
https://christophreich1996.github.io
ELLIS PhD student in machine learning at IMPRS-IS. Continual learning at scale.
sebastiandziadzio.com
Group Leader in Tübingen, Germany
I’m 🇫🇷 and I work on RL and lifelong learning. Mostly posting on ML related topics.
Large Models, Multimodality, Continual Learning | ELLIS ML PhD with Oriol Vinyals & Zeynep Akata | Previously Google DeepMind, Meta AI, AWS, Vector, MILA
🔗 karroth.com
@ELLISforEurope PhD Student @bethgelab @caml_lab @Cambridge_Uni @uni_tue; Currently SR @GoogleAI; Previously MPhil @Cambridge_Uni, RA @RutgersU, UG @iiitdelhi
vishaal27.github.io
PhD student @ Uni Tübingen | @bethgelab.bsky.social | Computational Neuroscience & ML
We build probabilistic #MachineLearning and #AI Tools for scientific discovery, especially in Neuroscience. Probably not posted by @jakhmack.bsky.social.
📍 @ml4science.bsky.social, Tübingen, Germany
#AI4Science #CompNeuro #NeuroAI #SBI
www.mackelab.org @mackelab.bsky.social
· Prof Uni Tuebingen ML4Science BCCN tue.ai
· Adjunct MPI IS · Fellow ellis.eu
· currently hiring postdocs and PhD students
· sometimes goes for a run
PhD student in machine learning & cognitive science in Munich & Tübingen
Professor in Scalable Trustworthy AI @ University of Tübingen | Advisor at Parameter Lab & ResearchTrend.AI
https://seongjoonoh.com | https://scalabletrustworthyai.github.io/ | https://researchtrend.ai/
PhD student @mackelab.bsky.social - machine learning in (neuro)science. Co-CEO of KI macht Schule gGmbH
ELLIS PhD Student in ML at the University of Tübingen.






























