This new image editing model from Black Forest Labs called **FLUX.1 Kontext** is really good. I ran some experiments on photos of Doggo, and couldn't believe how well it could maintain character consistent across multiple turns of editing.
https://notesbylex.com/absurdly-good-doggo-consistency-wit…
01.06.2025 23:25 — 👍 0 🔁 0 💬 0 📌 0
Learning to Reason without External Rewards (aka Self-confidence Is All You Need)
Turns out we can just use the LLM's internal sense of confidence as the reward signal to train a reasoning model, no reward model / ground-truth examples / self-play needed.
Amazing.
https://notesbylex.com/learning…
01.06.2025 23:25 — 👍 0 🔁 0 💬 0 📌 0
"My new hobby: watching AI slowly drive Microsoft employees insane" https://old.reddit.com/r/ExperiencedDevs/comments/1krttqo/my_new_hobby_watching_ai_slowly_drive_microsoft/
22.05.2025 06:43 — 👍 0 🔁 0 💬 0 📌 0
A cool approach to iteratively improving generated images, using o3 as an LLM-judge to generate targeted masks for improvements: https://simulate.trybezel.com/research/image_agent
21.05.2025 22:34 — 👍 0 🔁 0 💬 0 📌 0
If Trump was really looking out for Elon, he would have posted that on Twitter.
11.03.2025 12:10 — 👍 0 🔁 0 💬 0 📌 0
You're giving them way too much credit. Trump has always had really really bad ideas, but this time around there are no adults in government to shut them down, only sycophantic yes men.
11.03.2025 11:12 — 👍 1 🔁 0 💬 0 📌 0
All that pep talk just to make social media content.
10.03.2025 20:24 — 👍 3 🔁 0 💬 0 📌 0
Can you link me to it? Surprisingly hard to Google for.
09.03.2025 01:01 — 👍 0 🔁 0 💬 1 📌 0

Teaser figures in ACL template papers
Teaser figures in ACL template papers. GitHub Gist: instantly share code, notes, and snippets.
ARR deadline is coming up! If you're wondering how to make a beautiful full-width teaser figure on your first page, above the abstract, in LaTeX, check out this gist I made showing how I do it!
gist.github.com/michaelsaxon...
12.02.2025 21:35 — 👍 7 🔁 1 💬 0 📌 0

🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
12.02.2025 17:33 — 👍 23 🔁 5 💬 1 📌 2
"As a former tech lead at Meta for 6 years... I got 'meets all' or 'exceeds' every single half except the one in which I took parental leave."
www.reddit.com/r/business/c...
12.02.2025 19:58 — 👍 0 🔁 0 💬 0 📌 0
Won't someone please think of the child processes?
10.02.2025 03:32 — 👍 14 🔁 0 💬 0 📌 0
Media Watch has Chas derangement syndrome!
08.02.2025 03:49 — 👍 0 🔁 0 💬 0 📌 0
Really awesome work and big thank you for sharing it on Bluesky!
07.02.2025 23:35 — 👍 1 🔁 0 💬 0 📌 0

Example of injecting Wait token into the model generation.
A hilariously simple repro of OpenAI's test-time scaling paradigm called "Budget Scaling": end the thinking when your token budget is met, or append "Wait" to the model's generation to keep thinking, allowing the model to fix incorrect reasoning steps.
arxiv.org/abs/2501.19393
03.02.2025 06:14 — 👍 0 🔁 0 💬 0 📌 0
True.
31.01.2025 05:49 — 👍 1 🔁 0 💬 0 📌 0
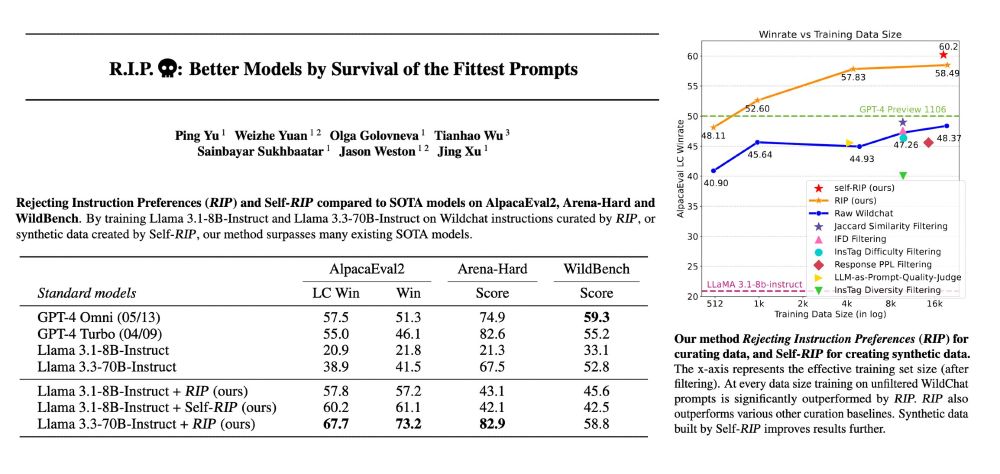
Abstract and figures from paper R.I.P.: Better Models by Survival of the Fittest Prompts
A method for evaluating data for preference optimisation.
Rejecting Instruction Preferences (RIP) can filter prompts from existing training sets or make high-quality synthetic datasets. They see large performance gains across various benchmarks compared to unfiltered data.
arxiv.org/abs/2501.18578
31.01.2025 05:21 — 👍 0 🔁 0 💬 0 📌 0
GitHub - Jiayi-Pan/TinyZero: Clean, accessible reproduction of DeepSeek R1-Zero
Clean, accessible reproduction of DeepSeek R1-Zero - Jiayi-Pan/TinyZero
A reproduction of Deepseek R1-Zero.
"The recipe:
We follow DeepSeek R1-Zero alg -- Given a base LM, prompts and ground-truth reward, we run RL.
We apply it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number."
github.com/Jiayi-Pan/Ti...
30.01.2025 20:05 — 👍 0 🔁 0 💬 0 📌 0
Reasoning models can be useful for generating high-quality few-shot examples:
1. generate 10-20 examples from criteria in different styles with r1/o1/CoT, etc
2. have a model rate for each example based on quality + adherence.
3. filter/edit top examples by hand
Repeat for each category of output.
29.01.2025 04:32 — 👍 0 🔁 0 💬 0 📌 0

My dog Doggo, a stag hound X bull arab, chilling in the grass
Happy dog.
28.01.2025 21:36 — 👍 2 🔁 0 💬 0 📌 0
The Illustrated DeepSeek-R1
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
27.01.2025 20:22 — 👍 71 🔁 22 💬 1 📌 4
So DeepSeek found a way to train a gpt4 quality model for *only* 6M worth of Nvidia hardware, and the market thinks this is bad for Nvidia?
27.01.2025 19:53 — 👍 1 🔁 0 💬 0 📌 0
Trump's Achilles heel is that he's a sucker for compliments and flattery. Just tell him how smart and good at business he is, and you'll get whatever you want from him.
You can see the billionaires leaning into that approach this time around, and it really seems to be working for them.
24.01.2025 22:57 — 👍 0 🔁 0 💬 0 📌 0
Imo the Google AI summaries are really helpful. The usefulness of an LLM increases substantially when it can reference its sources
24.01.2025 00:07 — 👍 0 🔁 0 💬 0 📌 0
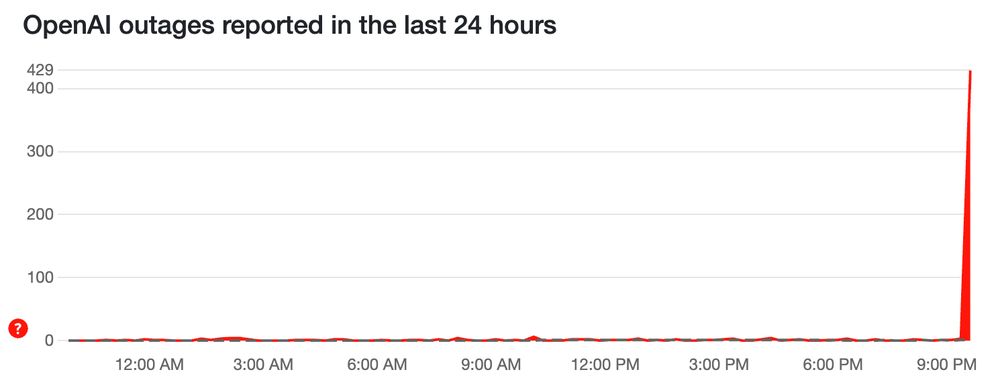
It's a chart of OpenAI outages reported in last 24 hours by Down Detector (which is just user reports). In the last few minutes, there's a huge spike.
ChatGPT seems to be down.
23.01.2025 11:54 — 👍 1 🔁 0 💬 0 📌 0

Announcing The Stargate Project
Announcing The Stargate Project
"The Stargate Project is a new company which intends to invest $500 billion over the next four years building new AI infrastructure for OpenAI in the United States"
$500 billion! For comparison, the 1960s Apollo project, when adjusted for inflation, cost around $250B.
openai.com/index/announ...
22.01.2025 01:30 — 👍 0 🔁 0 💬 0 📌 0
x.com
"Verified DeepSeek performance on ARC-AGI's Public Eval (400 tasks) + Semi-Private (100 tasks)
DeepSeek V3:
* Semi-Private: 7.3%
* Public Eval: 14%
DeepSeek Reasoner:
* Semi-Private: 15.8%
* Public Eval: 20.5%
Performance is on par, albeit slightly lower, than o1-preview"
x.com/arcprize/sta...
21.01.2025 21:28 — 👍 2 🔁 0 💬 0 📌 0

how_many_rs.md
GitHub Gist: instantly share code, notes, and snippets.
This is gold. DeepSeek-R1's thought process for "how many 'r's in strawberry."
"So positions 3, 8, and 9 are Rs? No, that can't be right because the word is spelled as S-T-R-A-W-B-E-R-R-Y, which has two Rs at the end...
Wait, maybe I'm overcomplicating it...."
gist.github.com/IAmStoxe/1a1...
21.01.2025 04:05 — 👍 3 🔁 1 💬 0 📌 0
The App for Connecting Open Social Web
Mastodon, Bluesky, Nostr, Threads in ONE app, in ONE feed ✨
https://openvibe.social
A free, collaborative, multilingual internet encyclopedia.
wikipedia.org
The official Bluesky profile of On Cinema at the Cinema. Sign up today at https://heinetwork.tv
RL + LLM @ai2.bsky.social; main dev of https://cleanrl.dev/
I (try to) do NLP research. Antipodean abroad.
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
ElonJet | Tracking Elon Musk’s Jet by @jacks.grndcntrl.net
Also follow @spacexjets.grndcntrl.net
Senior Director, Research Scientist @ Meta FAIR + Visiting Prof @ NYU.
Pretrain+SFT: NLP from Scratch (2011). Multilayer attention+position encode+LLM: MemNet (2015). Recent (2024): Self-Rewarding LLMs & more!
Writer http://jalammar.github.io. O'Reilly Author http://LLM-book.com. LLM Builder Cohere.com.
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
Digital Nomad · Historian · Data Scientist · NLP · Machine Learning
Cultural Heritage Data Scientist at Yale
Former Postdoc in the Smithsonian
Maintainer of Python Tutorials for Digital Humanities
https://linktr.ee/wjbmattingly
ML researcher, generally curious human, assembler of broken and lost things
http://machinelearninginpublic.com
Open source LLM fine-tuning! 🦥
Github: http://github.com/unslothai/unsloth Discord: https://discord.gg/unsloth
AI, Cloud, Productivity, Computing, Gaming & Apps ☀️