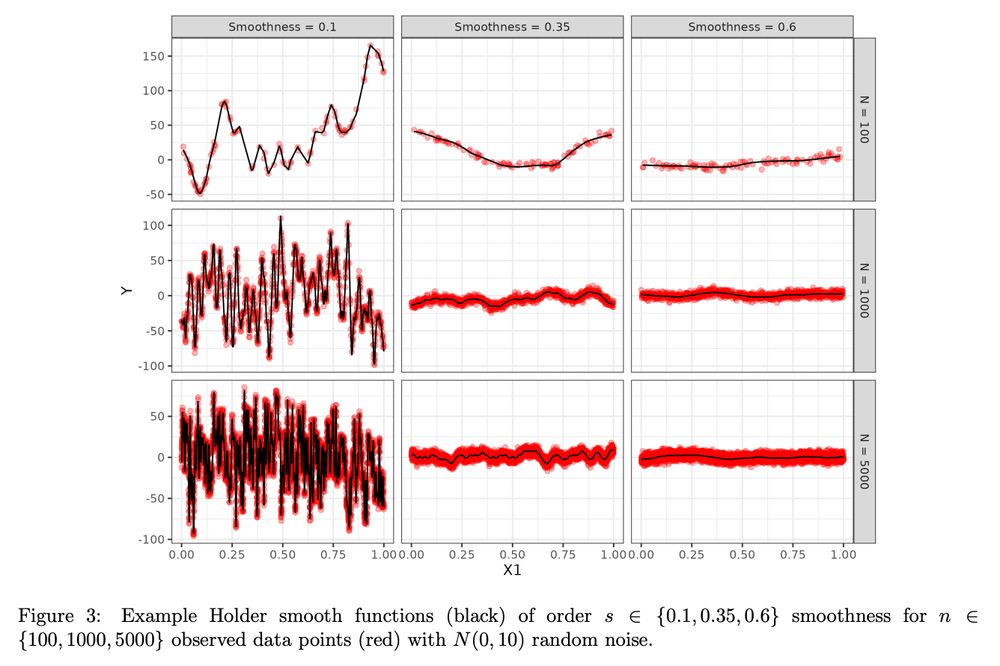
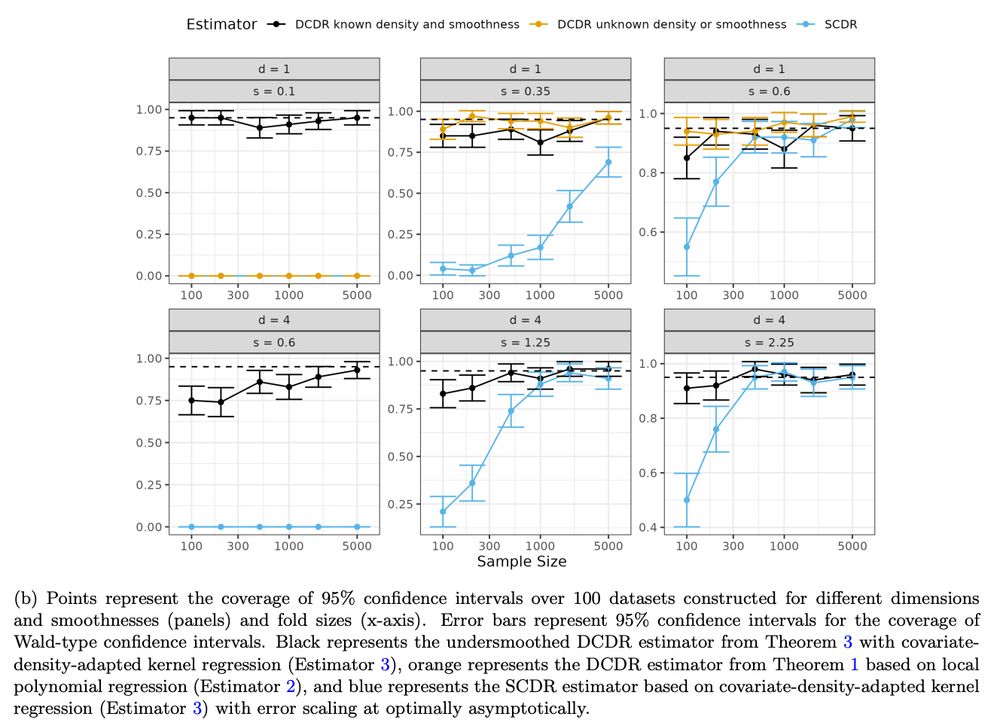
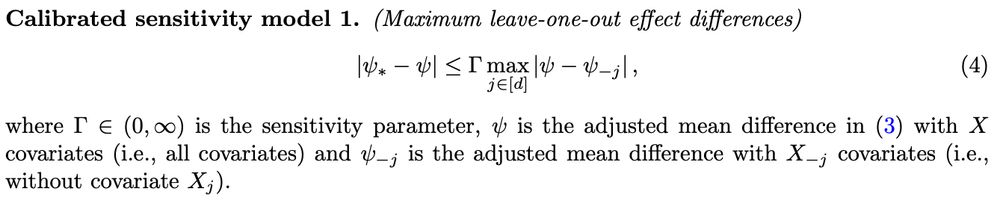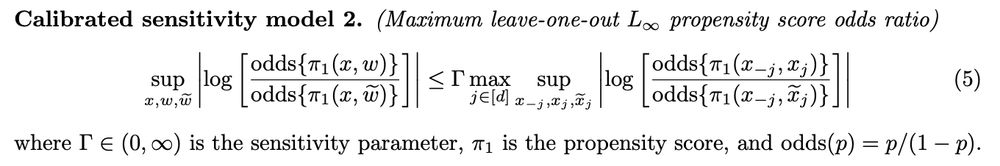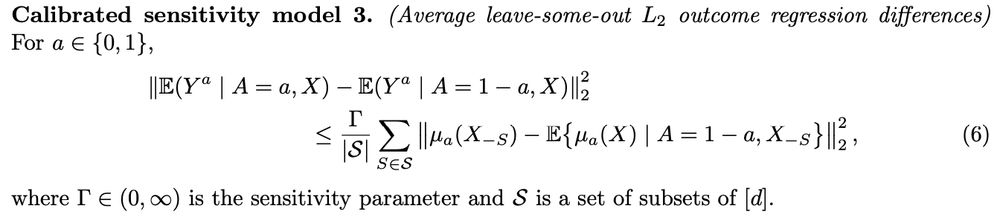New paper with @herbps10.bsky.social!
25.09.2025 20:25 — 👍 7 🔁 0 💬 0 📌 0
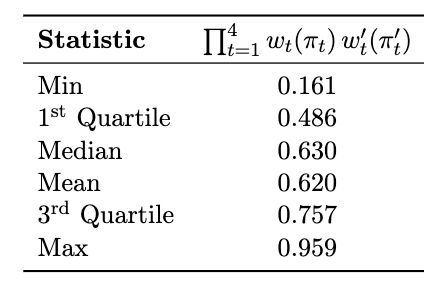
Distribution of cumulative weights, with one for each subject.
Although estimator is complex, some nice properties arise from the construction: in particular, we can examine distribution of cumulative weights across subjects, like in single-timepoint weighting
16.07.2025 22:36 — 👍 0 🔁 0 💬 0 📌 0
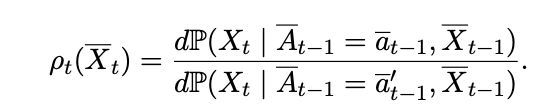
Covariate density ratio across two target regimes
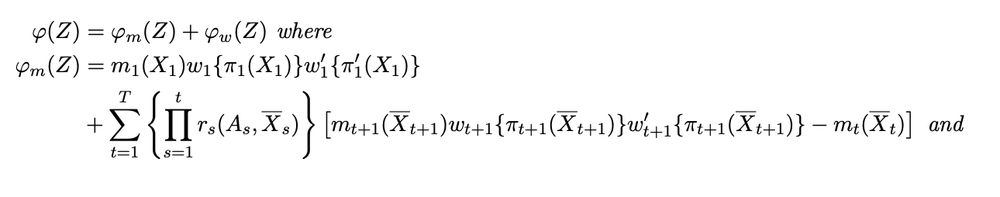
First half of EIF
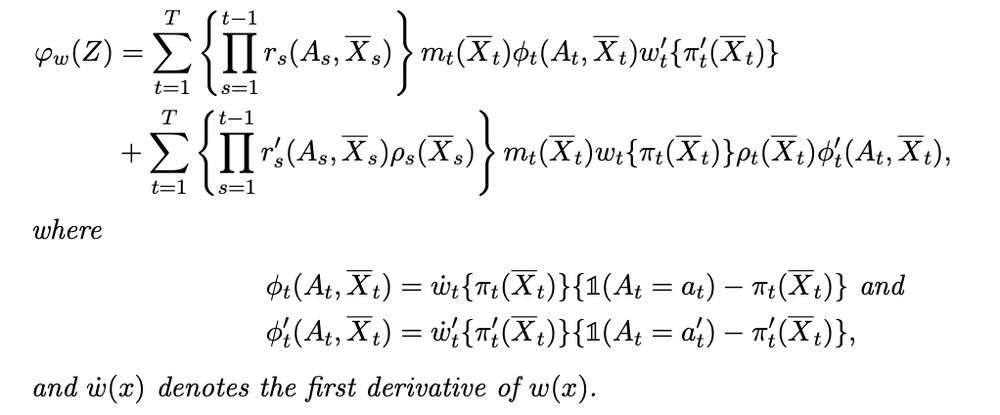
Second half of EIF, w/ additional novel term involving covariate density ratio across regimes
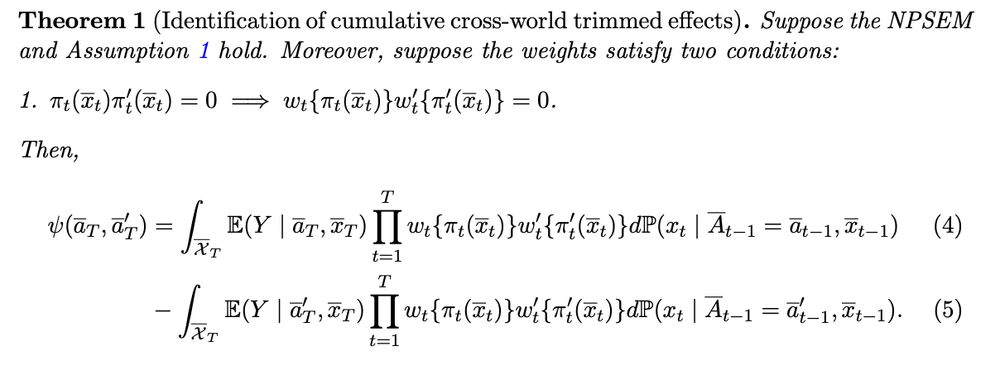
ID. No positivity needed. Just need weights to behave well, which is possible by construction (eg, overlap, trimming)
Cross-world"ness" --> nuances in identification and estimation
- ID: Need strong seq. rand., but still possible w/out positivity
- Est: new EIF for doubly robust estimator involves additional term w/ covariate density ratio across the target regimes
16.07.2025 22:36 — 👍 0 🔁 0 💬 1 📌 0

These fx are
- "Cross-world"
- "Mechanism-relevant" (they target mean diff in POs we care about)
- **Not** "policy-relevant" (they're not implementable)
This tradeoff arises elsewhere (mediation, censoring by death). Ours is another example:
What you want to know != what you can implement
16.07.2025 22:36 — 👍 0 🔁 0 💬 1 📌 0
New paper 📜 We construct longitudinal effects tailored to isolated mean diff in two POs while adapting to positivity violations under both regimes.
Some notes vv
16.07.2025 22:36 — 👍 7 🔁 0 💬 1 📌 0
We show that contrasts in flip effects yield WATEs when t=1 and non-baseline weighting for t>1
We also give some new doubly robust estimation results:
1. typical multiply robust estimator is twice as robust as people had thought
2. new sequentially doubly robust style estimator
12.06.2025 17:15 — 👍 0 🔁 0 💬 0 📌 0
Flip ints are built from a target tx and a weight (eg overlap wt, trimming indicator):
1. If subject would take target tx, do nothing
2. O/w flip subject to target with prob equal to the weight
Allows you to target any regime (eg, always treated) while adjusting to pos violations as needed
12.06.2025 17:15 — 👍 0 🔁 0 💬 1 📌 0
New paper! Weighting is great for addressing positivity violations, but it's unclear how to do it in longitudinal data. We propose a solution: "flip" interventions. These allow for weighing on non-baseline covariates and give effects robust to arbitrary positivity violations.
Highlights below vv
12.06.2025 17:15 — 👍 3 🔁 0 💬 1 📌 0
Excited to present this again at ACIC (Th 1:15pm)!
We realized trimming is a special version of weighting —> we generalized the analysis to longitudinal weighted effects
“Longitudinal weighted and trimmed treatment effects with flip interventions”
Draft:
alecmcclean.github.io/files/long-w...
13.05.2025 22:26 — 👍 3 🔁 0 💬 0 📌 0

Excited to present on Thursday @eurocim.bsky.social on new work with @idiaz.bsky.social on (smooth) trimming with longitudinal data!
"Longitudinal trimming and smooth trimming with flip and S-flip interventions"
Prelim draft: alecmcclean.github.io/files/LSTTEs...
08.04.2025 15:34 — 👍 5 🔁 3 💬 0 📌 1
link 📈🤖
Bridging Root-$n$ and Non-standard Asymptotics: Dimension-agnostic Adaptive Inference in M-Estimation (Takatsu, Kuchibhotla) This manuscript studies a general approach to construct confidence sets for the solution of population-level optimization, commonly referred to as M-estimation. Sta
15.01.2025 16:46 — 👍 1 🔁 1 💬 0 📌 0

ASA Community
The ASA Community is an online gateway for member collaboration and connection.
📢📢The 4th Lifetime Data Science Conference will take place May 28–30, 2025, at New York Marriott at the Brooklyn Bridge in Brooklyn, NY, USA. This event will feature keynotes by Drs. Nicholas Jewell and Mei-Ling Lee, short courses, 60+ invited sessions, and a banquet on May 29. Register and join us!
15.01.2025 14:37 — 👍 4 🔁 2 💬 0 📌 0

Free Weekly Econometrics Office Hours
Email: rachelleahchilders@gmail.com or Sign up form: https://forms.gle/XS55FASiGGHqAZKa6
Time: Wednesdays 10:00-12:00AM Eastern US (or by appointment)
Location: Zoom Link https://bowdoin.zoom.us/j/96039587180
Who: Anyone. Grad students, researchers, government workers. Private sector is okay but in that case if your question requires work that exceeds the allotted time I may request to negotiate a consulting fee.
What I can probably help with: Theory questions. Research design. Modeling.
Particular expertise: Time series. Causal inference. Bayes. Structural approaches. Machine learning.
Theory: Asymptotics. Statistical learning. Bayes/MCMC. Identification. Decision theory. Semiparametrics.
Fields: I know most about macro (DSGE, heterogeneous agents, VARs, etc), but can follow along in applied micro (labor, development, health, etc) & some finance.
Code: I think in R, can write Julia, and can get by in Python. I am likely to suggest you build a model in Stan. I know Stata but if it’s relevant to your question I suspect you can get better help elsewhere.
For the Spring semester, I am restarting my free weekly open office-hours for anyone in the world with Econometrics questions. Wednesdays 10-12AM Eastern or by appointment; sign up and drop by!
Details and sign up at donskerclass.github.io/OfficeHours....
14.01.2025 12:50 — 👍 22 🔁 7 💬 0 📌 0
Rebecca Farina, Arun Kumar Kuchibhotla, Eric J. Tchetgen Tchetgen
Doubly Robust and Efficient Calibration of Prediction Sets for Censored Time-to-Event Outcomes
https://arxiv.org/abs/2501.04615
09.01.2025 05:06 — 👍 4 🔁 3 💬 0 📌 0
For IV folks: what's a good resource on time-varying 2SLS?
Data = time-varying {covariates, instruments, outcomes}
Asmp: a version of longitudinal 2SLS; ie linear SEM in 1st & 2nd stages, over time
Time-varying data seems to introduce some nuance. Is there a textbook treatment of this?
02.01.2025 15:38 — 👍 0 🔁 0 💬 0 📌 0
@idiaz.bsky.social et al. 2020
arxiv.org/pdf/2006.01366
Generalizes to a large class of ints. Also gives great review of other innovations from 2010s
Bonus: for identification, it uses an NPSEM -- an alternative to SWIGs. NPSEMs come from do-why lit; great for discussing asmps w/ practitioners
30.12.2024 13:45 — 👍 3 🔁 0 💬 0 📌 0

Identification, estimation and approximation of risk under interventions that depend on the natural value of treatment using observational data
2) Young et al. 2014 pmc.ncbi.nlm.nih.gov/articles/PMC...
Ints that depend on natural value of trtment. Very easy-to-read! Appendix B is great on ID.
Further reading: the SWIG papers; primer first (stats.ox.ac.uk/~evans/uai13/Richardson.pdf), and original (R&R '13) when you're feeling brave!
30.12.2024 13:45 — 👍 0 🔁 0 💬 1 📌 0
1) Robins et al. 2004 www.jstor.org/stable/pdf/r...
Addresses or foreshadows lots of subsequent work on time-varying data. The data analysis in Section 6 helped me build intuition for earlier parts of the paper.
30.12.2024 13:45 — 👍 0 🔁 0 💬 1 📌 0
Identification, estimation and approximation of risk under interventions that depend on the natural value of treatment using observational data
Related to lit review in an ongoing project: for complex time-varying ints and identification in epi/bio, I think these three papers are great starting points:
www.jstor.org/stable/pdf/r...
pmc.ncbi.nlm.nih.gov/articles/PMC...
arxiv.org/pdf/2006.01366
Details below. What are other's favorites?
30.12.2024 13:45 — 👍 4 🔁 0 💬 1 📌 0
What's the best paper you read this year?
27.12.2024 17:02 — 👍 35 🔁 4 💬 13 📌 2
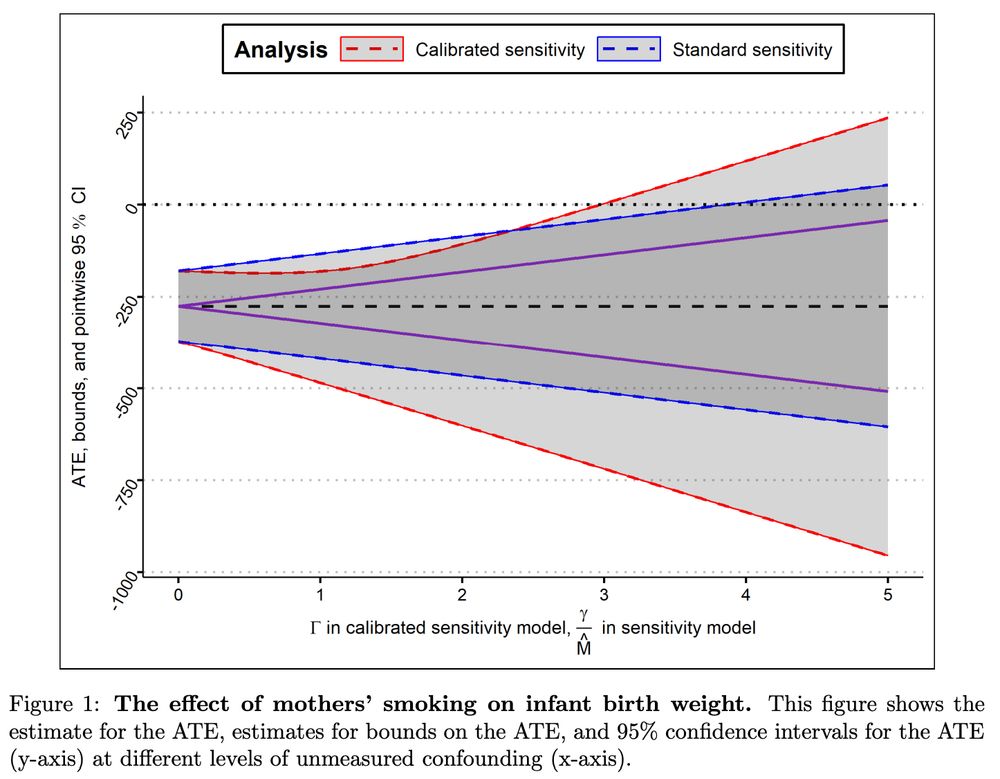
We analyze the effect of mothers’ smoking on infant birthweight, and see that accounting for uncertainty in estimating M alters CIs for ATE.
This was fun work with Edward and Zach Branson (sites.google.com/site/zjbrans...) and was a great project to finish my PhD!
9/9
28.12.2024 11:27 — 👍 1 🔁 0 💬 0 📌 0
Often calibration is somewhat informal w/out accounting for uncertainty in M. However, statistical error in estimating M is first order and can alter confidence intervals! Indeed, if calibration is goal, more intuitive to put M directly in model.
We explore ramifications of this reframing!
7/9
28.12.2024 11:27 — 👍 2 🔁 0 💬 1 📌 0

#2 Calibrated sensitivity models arxiv.org/abs/2405.08738
Sensitivity analyses look at how unmeasured confounders (U) alter causal effect estimates (when, eg, trtment not random). To understand U, we can calibrate by estimating analogous ~measured~ conf. (M) by leaving out variables from data
6/9
28.12.2024 11:27 — 👍 1 🔁 0 💬 1 📌 0


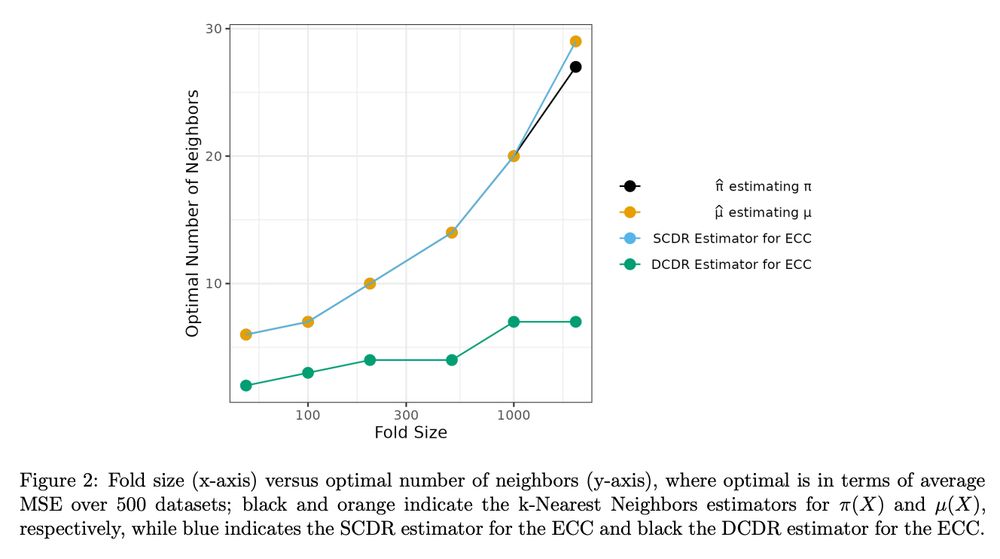
#1 arxiv.org/abs/2403.15175
The DCDR estimator is quite new (2018, arxiv.org/abs/1801.09138). It splits training data and trains nuisance fns on independent folds
It can get faster conv rates than usual DR estimator, which trains nuis funcs on same sample.
We analyze the DCDR est. in detail!
2/9
28.12.2024 11:27 — 👍 0 🔁 0 💬 1 📌 0
Professor of Epidemiology
Emory University
Currently @ Yale, working on causal inference & cutting down on caffeine.
Website: melodyyhuang.com
Statistics & health policy person
research @ Google DeepMind
PhD student at @cmurobotics.bsky.social working on efficient algorithms for interactive learning (e.g. imitation / RL / RLHF). no model is an island. prefers email. https://gokul.dev/. on the job market!
Fostering a dialogue between industry and academia on causal data science.
Causal Data Science Meeting 2025: causalscience.org
https://www.bodegacats.nyc
PhD candidate @Wharton OID. Interests: causal inference, partial identification, fairness, discrimination
Senior Data Analyst at Columbia University Epidemiology // Incoming Biostatistics PhD student at UC Berkeley
PhD student at UC Berkeley studying RL and AI safety.
https://cassidylaidlaw.com
Associate professor at Columbia University
Epidemiology, causal inference, addiction medicine
https://kararudolph.github.io/
Building personalized Bluesky feeds for academics! Pin Paper Skygest, which serves posts about papers from accounts you're following: https://bsky.app/profile/paper-feed.bsky.social/feed/preprintdigest. By @sjgreenwood.bsky.social and @nkgarg.bsky.social
Machine learning researcher at Microsoft Research. Adjunct professor at Stanford.
Machine Learning Professor
https://cims.nyu.edu/~andrewgw
Research @OpenAI. I study Reinforcement Learning. PhD from UT Austin. Previously FAIR Paris, Meta US, NVIDIA, CMU, and IIT Kharagpur.
Website: https://hari-sikchi.github.io/
PhDing @UCSanDiego @NVIDIA @hillbot_ai on scalable robot learning and embodied AI. Co-founded @LuxAIChallenge to build AI competitions. @NSF GRFP fellow
http://stoneztao.com
PhD Student in Machine Learning at CMU.
🐦 twitter.com/steph_milani
🌐 stephmilani.github.io
PhD at Machine Learning Department, Carnegie Mellon University | Interactive Decision Making | https://yudasong.github.io
PhD student | Interested in all things decision-making and learning
PhD at NYU studying reasoning, decision-making, and open-endedness
alum of MIT | prev: Google, MSR, MIT CoCoSci
https://upiterbarg.github.io/