Ten Years of D3D12
For those of us that have been using it from the start, it can be hard to believe that Direct3D 12 has been around for nearly ten years now. Windows 10 was released on July 29th 2015, and D3D12 has be...
I've got a new blog post for all of you fine folks! It runs through the additions to D3D12 since it was released, and finishes up with some of the things that have changed for me personally in my code.
(And yes it's really been 10 years 👴).
therealmjp.github.io/posts/ten-ye...
08.09.2025 00:49 — 👍 154 🔁 52 💬 7 📌 2
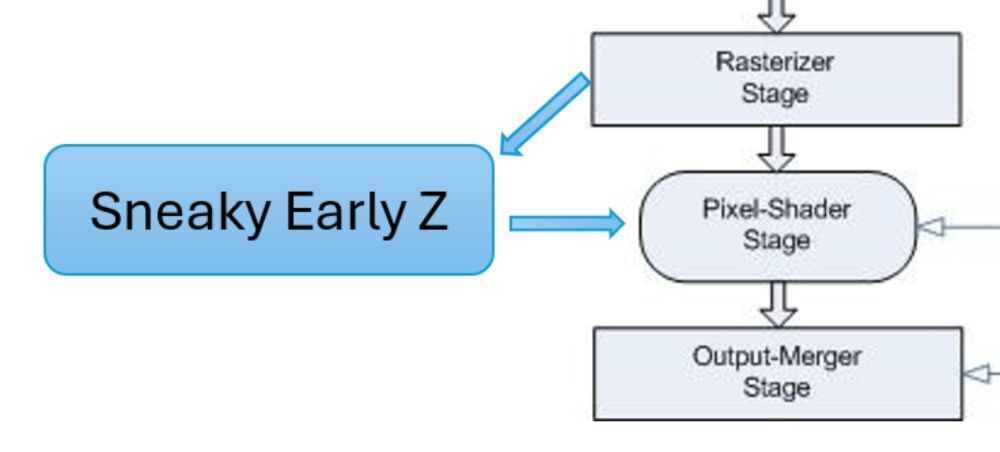
bind groups suck because they are essentially descriptor sets, and descriptor sets suck because they make a thing that should be easy, extremely difficult
20.03.2025 01:45 — 👍 4 🔁 1 💬 1 📌 0
In case it's useful, a while back I wrote a cubemap prefilter shader for GGX: github.com/voithos/quar...
I can't recall if I verified its output with any rigor, but it looked reasonable enough at the time (I mostly wrote it as a learning experience).
27.04.2025 06:50 — 👍 1 🔁 1 💬 0 📌 0
Oblivion isn't my favorite TES but the remaster feels so damn fresh after the recent RPGs, and I see people on Steam share my opinion. Plus I'm getting like 200 FPS on a laptop!
Great job, Bethesda, now do Morrowind!
24.04.2025 03:18 — 👍 11 🔁 1 💬 0 📌 0

Graphics Programming weekly - Issue 389 - April 27th, 2025 www.jendrikillner.com/post/graphic...
28.04.2025 13:16 — 👍 52 🔁 18 💬 0 📌 0

In game screenshot of the game X-Com above, with a blocky screenshot showing the collision view below it approximating the solidness of the visual view

In game screenshot of the game X-Com above, with a blocky screenshot showing the collision view below it approximating the solidness of the visual view. The screenshot is highlighting a glitch where diagonals allow peering into closed areas due to a quirk of how collision is done
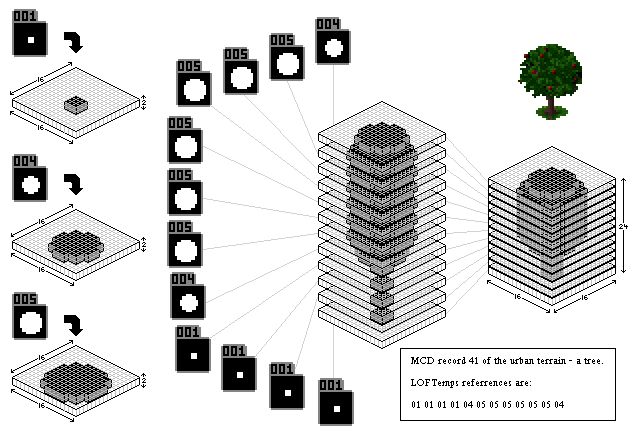
A graphic showing how a tree’s collision in X-Com is defined by vertical slices of predefined patterns

The 112 predefined pattern slices X-Com uses for collision
this is pretty cool. the original X-Com was a 2D isometric game but the collision system itself was 3D. objects in the world would have collisions defined by vertical stacks of predefined patterns. this allowed the game to do accurate line of sight and hit detection. very cool!
28.12.2024 15:47 — 👍 364 🔁 108 💬 7 📌 10
ShaderGlass 1.0 has been released! Big update! 🚨
Apply shaders to any app on your desktop: gaming, pixel art and video. 📺
Free and open source! Links in reply.
21.02.2025 04:15 — 👍 1800 🔁 683 💬 55 📌 58

Graphics Programming weekly - Issue 378 - February 9th, 2025 www.jendrikillner.com/post/graphic...
10.02.2025 14:29 — 👍 88 🔁 27 💬 0 📌 1
Introduction to Computer Graphics course notes touching upon topics such as rasterisation, PBR, raytracing, image and geometry processing and fluid simulation perso.liris.cnrs.fr/nicolas.bonn...
29.01.2025 20:53 — 👍 54 🔁 13 💬 1 📌 1
TerminateProcess() monitored by a another watchdog process?
31.01.2025 04:44 — 👍 0 🔁 0 💬 1 📌 0
More like a sign of a burnout.
31.01.2025 04:42 — 👍 0 🔁 0 💬 1 📌 0
OK, AMD's Reshape is amazing. Clearing out so many errors that I would have previously struggled for days and days to catch in the past. Thanks so much @gpuopen.bsky.social, @aurolou.bsky.social, @miguel-oenp.bsky.social and everyone who had a hand in creating this one ❤️
29.01.2025 03:18 — 👍 16 🔁 1 💬 1 📌 0
Real-Time Ray Tracing of Micro-Poly Geometry with Hierarchical Level of Detail
Judging by the Blackwell whitepaper, RTX Mega Geometry is an implementation of ideas from this HPG 2023 paper by Carsten Benthin and me. It is cool to see this broadly deployed so soon. Hopefully, cross-vendor standardization will be just as swift.
momentsingraphics.de/HPG2023.html
29.01.2025 20:40 — 👍 79 🔁 15 💬 1 📌 0
I love how Microsoft deprecated _ReadWriteBarrier(), but there's no alternative for it except "use std::atomic instead".
So std::atomic has to push/pop deprecation warnings every time it needs to call it.
04.12.2024 18:50 — 👍 8 🔁 1 💬 0 📌 0
RESTIR is one of those moments in computer graphics where a method is too useful to ignore, but too complex to fit in a textbook paragraph - and with time, the explanation simplifies and it becomes canon. This course by Chris Wyman is a huge effort to explain and simplify
20.11.2024 15:13 — 👍 59 🔁 9 💬 2 📌 1
GitHub - redorav/hlslpp: Math library using HLSL syntax with multiplatform SIMD support
Math library using HLSL syntax with multiplatform SIMD support - redorav/hlslpp
HLSL++ reached 600 stars today. I started the project because I didn't like the interface of the math library we had at Tt. I understand why though, it's a lot of effort. Thank you to everyone who finds it useful and contributed.
github.com/redorav/hlslpp
19.11.2024 09:14 — 👍 53 🔁 9 💬 0 📌 0

Still one of the most accessible explanations of the rendering equation out there
18.11.2024 20:26 — 👍 144 🔁 31 💬 1 📌 0

Graphics Programming weekly - Issue 366 - November 17th, 2024 www.jendrikillner.com/post/graphic...
18.11.2024 16:05 — 👍 141 🔁 36 💬 2 📌 1
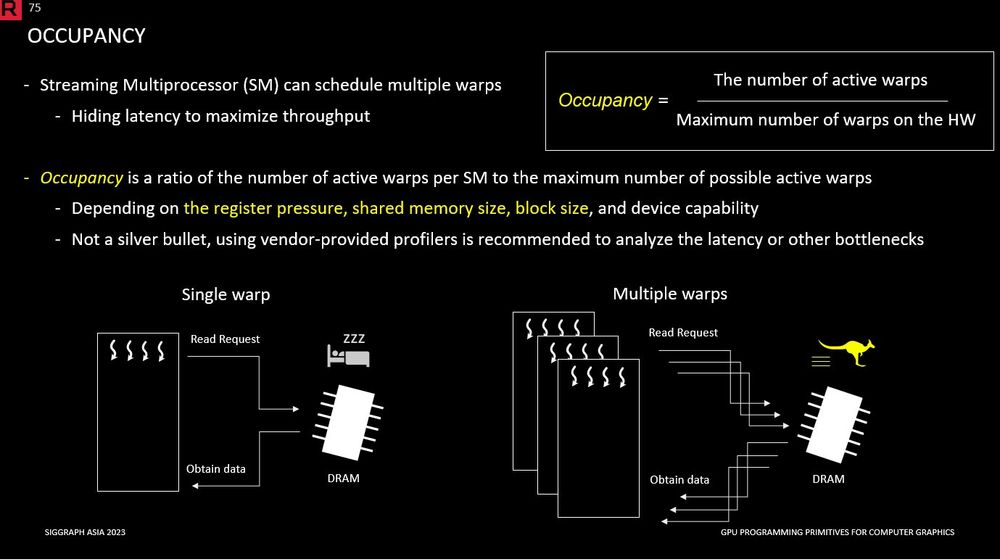
Nice summary of occupancy as a way to hide mem latency, but it is not the only (and sometimes not the best) way. Helping the compiler to add more instructions between the mem read issue and the data use by for eg partially unrolling a loop might help as well (from gpu-primitives-course.github.io)
17.11.2024 12:46 — 👍 81 🔁 10 💬 2 📌 1
YouTube video by Valve
Half-Life 2: 20th Anniversary Documentary
valve has published a 2-hour documentary for the 20th anniversary of hl2. currently watching it.
i was jazzed from literally the first seconds, when i saw the shots and heard that eastern european accent, because i knew it was viktor antonov.
www.youtube.com/watch?v=YCjN...
17.11.2024 21:17 — 👍 21 🔁 2 💬 2 📌 0
GitHub - jbikker/tinybvh: Single-header BVH construction and traversal library.
Single-header BVH construction and traversal library. - jbikker/tinybvh
tiny_bvh.h 0.9.1 adds support for using a custom alloc/free:
github.com/jbikker/tiny...
As the Dutch say: "Voor u verandert er verder niets", i.e. the lib has good default options that it will use transparently unless you insist on exerting that kind of control.
18.11.2024 13:56 — 👍 16 🔁 3 💬 0 📌 0
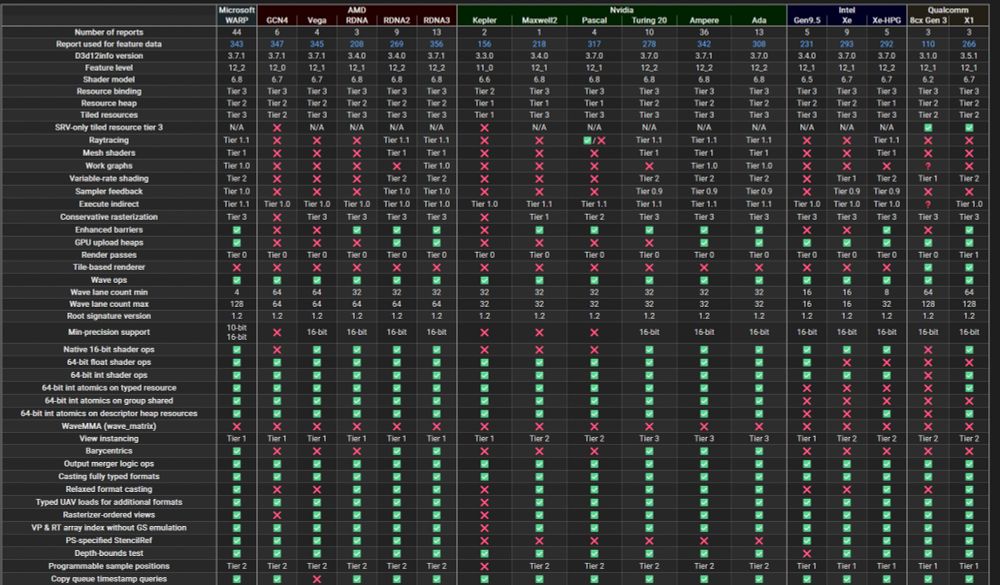
I feel the need to shout out this awesome D3D12 feature table that a few people from the DirectX discord put together: d3d12infodb.boolka.dev/FeatureTable...
18.11.2024 02:23 — 👍 122 🔁 38 💬 1 📌 2
"Real-time denoising of importance sampled direct lighting", MSc thesis describing the denoising approach used for ReSTIR DI in Northlight engine for Alan Wake 2, also nice summary and reference for various denoising techniques aaltodoc.aalto.fi/server/api/c...
18.11.2024 17:59 — 👍 31 🔁 3 💬 0 📌 0
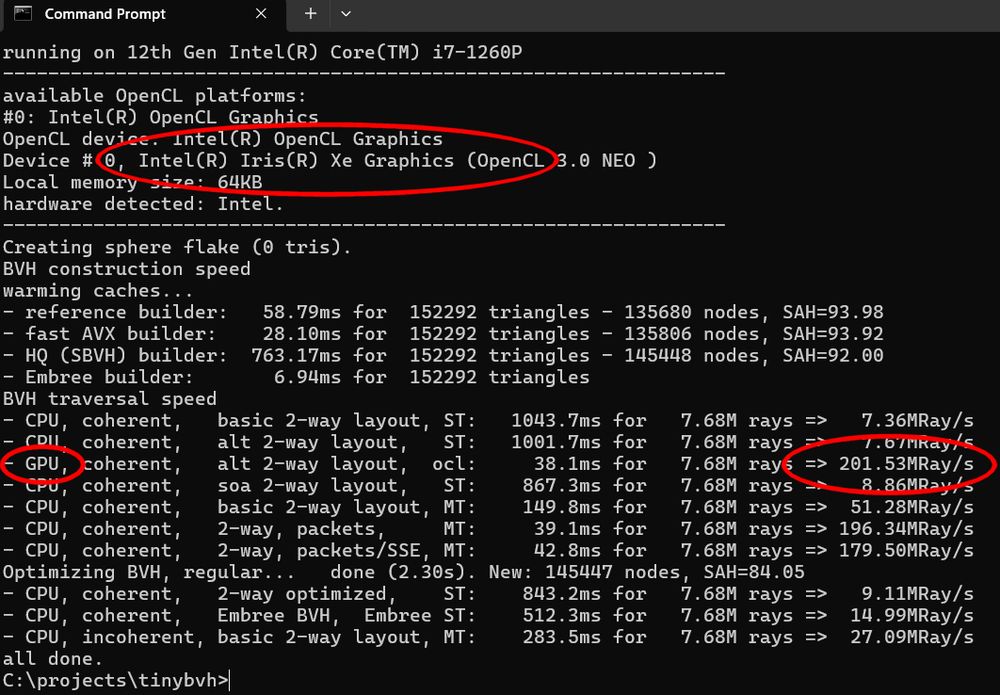
tiny_bvh.h, speedtest app: First OpenCL BVH traversal kernel is now available, for the 'Aila & Laine' 2-way GPU-friendly format. About 200M rays/s for the sphere flake on Intel Xe integrated graphics.
github.com/jbikker/tiny...
18.11.2024 19:38 — 👍 14 🔁 3 💬 0 📌 0
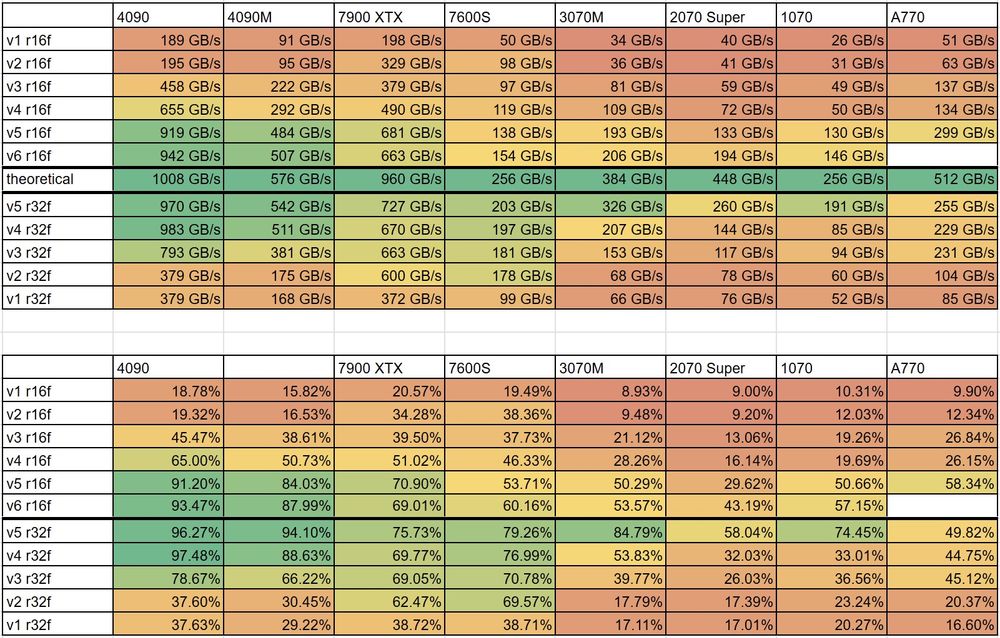
A table showing the experimental results of applying 6 different compute shader versions of a simple 3x3x3 box blur on a 512x512x512 texture using either GL_R16F or GL_R32F internal format for storage for a eight different GPUs spanning several GPU architectures and vendors.
The upper table shows the absolute effective bandwidth (measured as the sum of total bytes read and written divided by execution time), whereas the lower table shows the effective bandwidth relative to the theoretical bandwidth as a percentage.
Each row corresponds to a specific shader variant (except for the "theoretical" row, which displays the theoretical bandwidth according to the GPU specification), and each column corresponds to a specific GPU. The color coding is per column in the upper table, and it's a single color coding on the entire lower table.
Each version will be explained in detail in the subsequent posts.
Version 6 applies uses half precision floating point for the shared memory cache, and the relevant extension does not exist in the Intel drivers for Windows. Likewise this version is not applied to the GL_R32F internal format benchmarks since that would destroy the precision of the backing format anyway.
The code was written and initially tested on a desktop 4090 (the first column), which naturally skews the results a bit since everything was evaluated and tested on that GPU. Had I used another GPU I might have picked slightly different compromises, and the results would have been slightly different.
One interesting observation is that the RTX 4000 series (Ada Lovelace architecture) significantly overperform everything else, with 7900 XTX (RDNA3) slightly behind. A large part of these overwhelmingly efficient results is due to the massive caches these devices sport (72 MiB on the desktop 4090, 64 MiB on the laptop 4090, etc.), which really helps reach peak bandwidth a lot easier.
Let's wrap up this lovely week with a nice technical post
This is the "case study" from my Masterclass at GPC, where I apply a series of optimizations to improve the effective bandwidth of a 3x3x3 blur (a proxy for a huge set of operations on volumetric data)
Check ALT text for (a lot of) context.
17.11.2024 22:59 — 👍 133 🔁 25 💬 4 📌 4
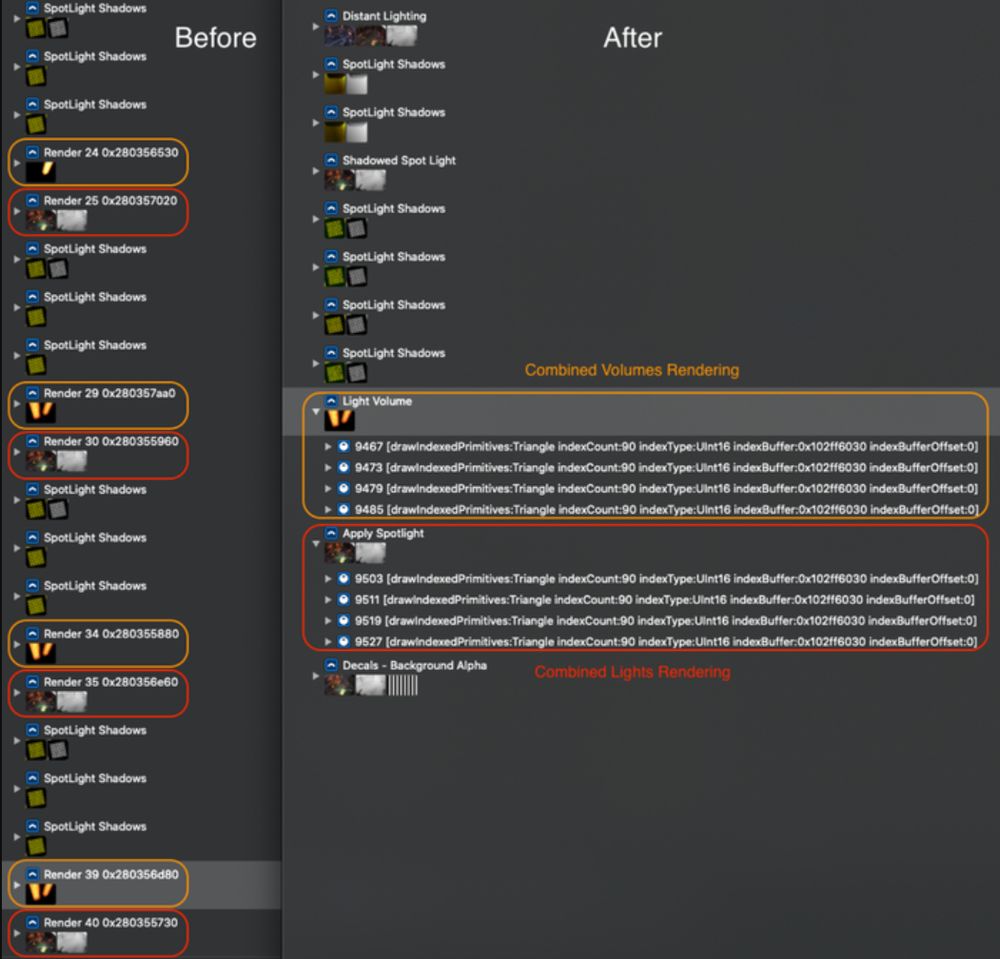
Maybe now is the time to share!
A quick way to reduce bandwidth A LOT when dealing with Deferred Renderer on mobile
Possibly you have non-optimal order of passes when dealing with shadowed lights. This saves 120+MB/frame with 7 lights on iPad
More: www.gamedeveloper.com/game-platfor...
21.10.2024 20:32 — 👍 13 🔁 1 💬 1 📌 0
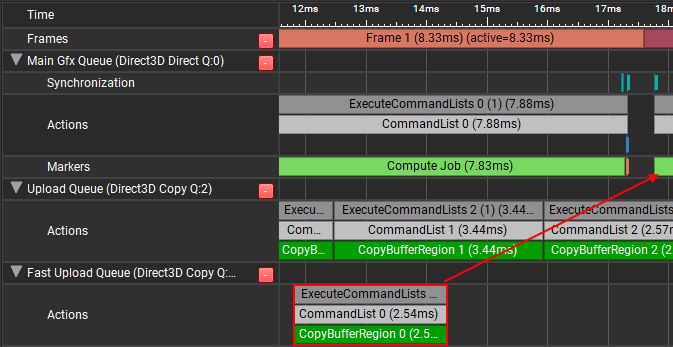
GPU Memory Pools in D3D12
Basics of GPU Memory Integrated/UMA GPUs Dedicated/NUMA GPUs How It Works In D3D12 Common Patterns in D3D12 Textures And The Two-Step Upload Should We Upload Buffers? Working With The COPY Queue Two C...
If you all don’t mind, I’m going go shill this blog post I wrote two years ago about dealing with memory pools and uploading from SysRAM->VRAM. It’s one I link to frequently for people starting out in D3D12. And it has fun graphs!
therealmjp.github.io/posts/gpu-me...
20.10.2024 17:29 — 👍 79 🔁 14 💬 2 📌 0
Reporter at Bloomberg | co-host of Triple Click | New York Times bestselling author of Play Nice + Press Reset + Blood, Sweat, and Pixels | jschreier@gmail.com
Wrote the eBook "Understanding the Odin Programming Language". Made the game "CAT & ONION". Check out what I'm up to these days: https://zylinski.se
VP of Undefined Behavior at redpanda.com
Scheveningen 🐚
retro coder
| Castle Matsumoto: https://steam.pm/app/2490030
| Enclosure 3-D: https://steam.pm/app/2128440
| ShaderGlass: https://mausimus.itch.io/shaderglass
| Full Portfolio: https://mausimus.net
CNRS research director in computer graphics, part time assistant prof at Polytechnique
Making pretty pictures with GPUs
https://blog.danielschroeder.me/
Vtuber | Anime & Podcast Producer | Editor | Youtuber | Streamer | Gamedev
If you were followed by this account it means you’re included in the GPU / Rendering List: https://bsky.app/profile/did:plc:eh32b5rpgj3mirsy6cp4tyea/lists/3lbecmqh5ja2m
Please consider pinning the list.
Maintained by @gfxnico.bsky.social
Sokol, Chips, Oryol, Nebula Device, Drakensang (1+2+Online), Project Nomads, Urban Assault, and more (https://www.mobygames.com/person/117426/andre-wei%C3%9Fflog/credits/)
https://github.com/floooh/
@floooh@mastodon.gamedev.place
Blizzard, Activision, Avalanche, Starbreeze, Simbin
(World of Warcraft / (Survival Title) / CoD Vanguard / JustCause3 & 4 / Rage / Syndicate / Race Pro)
github.com/ecilasun/tinysys
@the_cilasun@mastodon.gamedev.place
u/Not_Computer
Principle Tech Artist, Graphics Programmer, general Game Dev, racing snail at Tuatara VFX. (he\him)
https://bgolus.medium.com/
https://ko-fi.com/bgolus
Developer of Iron Lung, Dusk, Squirrel Stapler, Butcher's Creek, and other games. Making an isometric shooter called B.U.G.B.I.T.E
http://szymanski.games
Creators of Bugsnax & Octodad! Out NOW PS5, PS4, EGS, Xbox Series X|S, Windows 10, Steam, and Nintendo Switch eShop! Join our Discord at http://discord.gg/younghorses . Links to our games and places to buy them -> bugsnax.com | octodad.com
🎮 indie tech artist
🏗️ I made Shader Forge & Shapes
🌐 working on https://half-edge.xyz
🔥 shader sorceress
📏 math dork
🎥 rare YouTuber/streamer
📡 ex-founder of @NeatCorp
my kids:
🥪 @toast.acegikmo.com
🥗 @salad.acegikmo.com
🐈⬛ @thor.acegikmo.com
Washed-up renderologist working on #TinyGlade with @anopara.bsky.social; ½ of Pounce Light, ½ making sense ½ the time; he/him; 🦀
graphics & lighting @ naughty dog
3D graphics engineer specializing in mobile and AR. Author of “Metal by Example”
Graphics / Game Developer 🏳️🌈
Senior developer at Microsoft. Demoscener. Babylon.js core team. Technical Emmy Award winner with Golaem. AFOL. Personal views here!
Graphics dev and vegan 🌱
Rendering Engineer @ Traverse Research
Cycle saver and bit juggler
Artisan Cube Crafter
she/her
‘lazy game dev’ or in other words: uses ray tracing.