Thanks! I tried an initial exploration but ran into stability issues, so for now it's future work
28.04.2025 06:33 — 👍 0 🔁 0 💬 0 📌 0
Haha yeah it kinda looks like paying respects
17.02.2025 10:25 — 👍 0 🔁 0 💬 1 📌 0
Thanks!
17.02.2025 10:24 — 👍 0 🔁 0 💬 0 📌 0
Basically there are p prototypes, at each batch there are n samples (patch tokens). You assign samples to prototypes via a simple dot product and you push prototypes slightly towards their assigned samples.
To prevent empty clusters we use a Sinkhorn-Knopp like in SwAV
17.02.2025 10:24 — 👍 1 🔁 0 💬 1 📌 0
Hi! It's a custom process, very similar to the heads of DINO and SwAV.
The idea is to cluster the whole distribution of model outputs (not a single sample or batch) with an online process that is slightly updated after each iteration (like a mini-batch k-means)
17.02.2025 10:21 — 👍 1 🔁 0 💬 1 📌 0
Thanks a lot!
17.02.2025 10:15 — 👍 0 🔁 0 💬 0 📌 0
As always thank you to all the people who helped me, Federico Baldassarre, Maxime Oquab, @jmairal.bsky.social , Piotr Bojanowski
With this third paper I’m wrapping up my PhD. An amazing journey, thanks to the excellent advisors and colleagues!
14.02.2025 18:04 — 👍 10 🔁 0 💬 3 📌 0
Code and weights are Apache2 so don’t hesitate to try it out!
If you have torch you can load the models in a single line anywhere
The repo is a flat folder of like 10 files, it should be pretty readable
14.02.2025 18:04 — 👍 5 🔁 0 💬 1 📌 0

Qualitatively the features are pretty good imo
DINOv2+reg still has artifacts (despite my best efforts), while the MAE features are mostly color, not semantics (see shadow in the first image, or rightmost legs in the second)
CAPI has both semantic and smooth feature maps
14.02.2025 18:04 — 👍 3 🔁 0 💬 1 📌 0
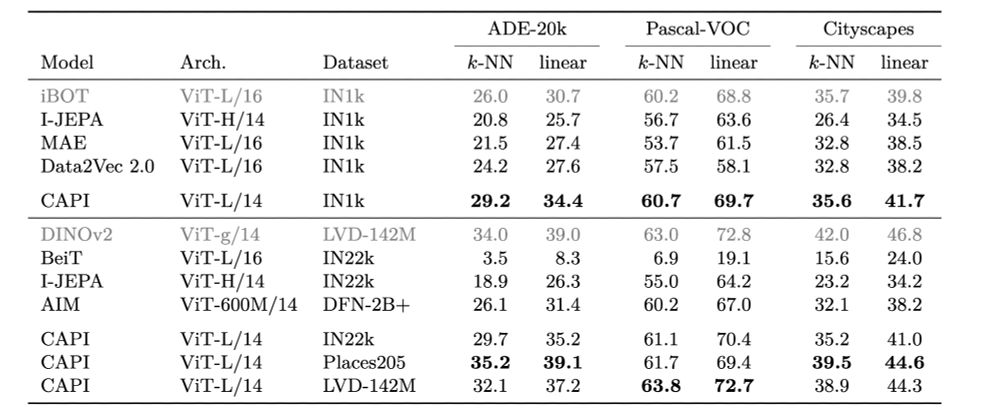
But segmentation is where CAPI really shines: it even beats DINOv2+reg in some cases, esp. on k-nn segmentation
Compared to baselines, again, it’s quite good, with eg +8 points compared to MAE trained on the same dataset
14.02.2025 18:04 — 👍 3 🔁 0 💬 1 📌 0
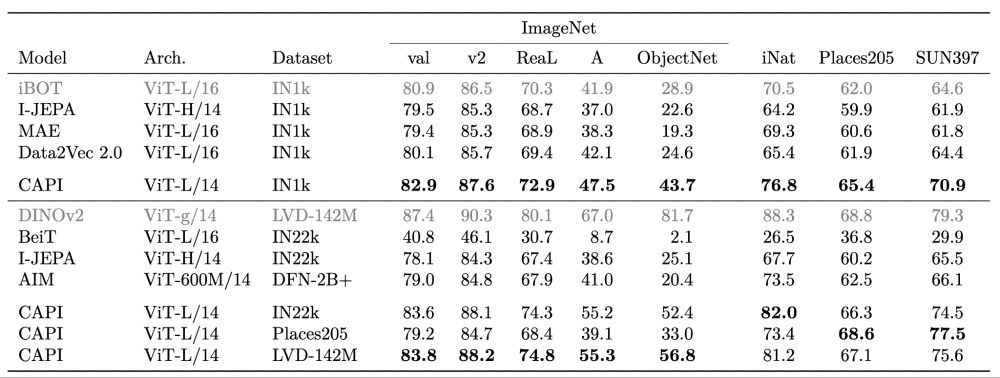
We test 2 dataset settings: “pretrain on ImageNet1k”, and “pretrain on bigger datasets”
In both we significantly improve over previous models
Training on a Places205, is better for scenes (P205, SUN) but worse for object-centric
14.02.2025 18:04 — 👍 3 🔁 0 💬 1 📌 1
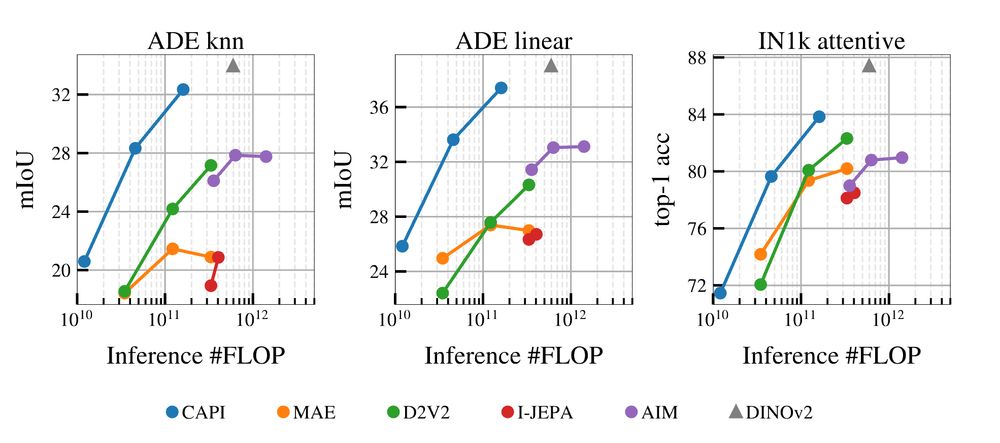
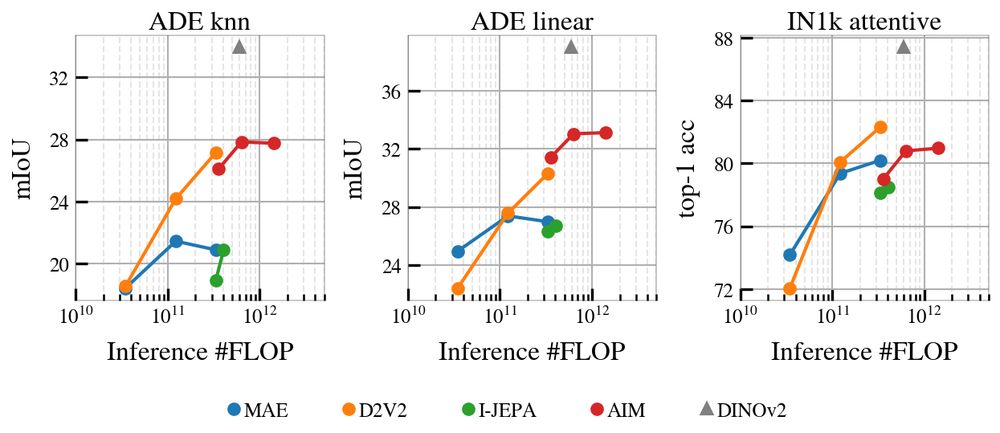
Enough talk, we want numbers. I think they are really good! CAPI is not beating DINOv2+reg yet, but it sounds possible now. it closes most of the 4-points gap between previous MIM and DINOv2+reg, w/ encouraging scaling trends.
14.02.2025 18:04 — 👍 4 🔁 0 💬 2 📌 0
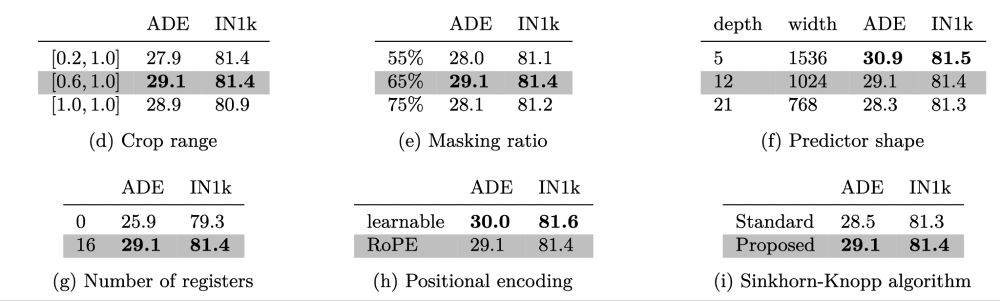
Plenty of other ablations, have fun absorbing the signal. Also the registers are crucial, since we use our own feature maps as targets, so we really don’t want artifacts.
14.02.2025 18:04 — 👍 3 🔁 0 💬 1 📌 0
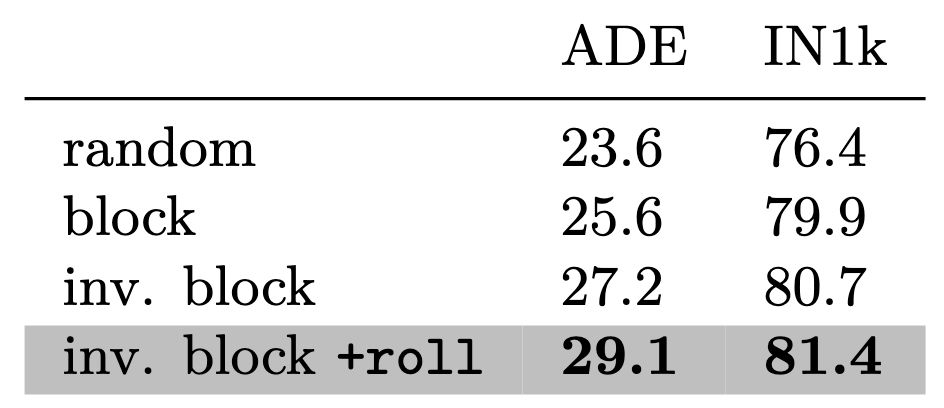
Masking strategy: it makes a big diff.
“Inverse block” > “block” > “random”
*But* w/ inv. block, you will oversample the center to be masked out
→we propose a random circular shift (torch.roll). Prevents that, gives us a good boost.
14.02.2025 18:04 — 👍 3 🔁 0 💬 1 📌 0
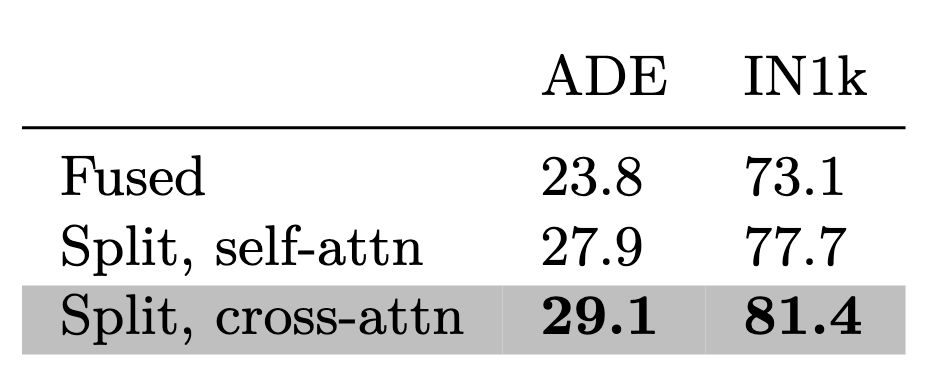
In practice, cross-attn works really well. Not mentioned in the table is that the cross-attn predictor is 18% faster than the self-attn predictor, and 44% faster than the fused one, so that’s a sweet bonus.
14.02.2025 18:04 — 👍 3 🔁 0 💬 1 📌 0
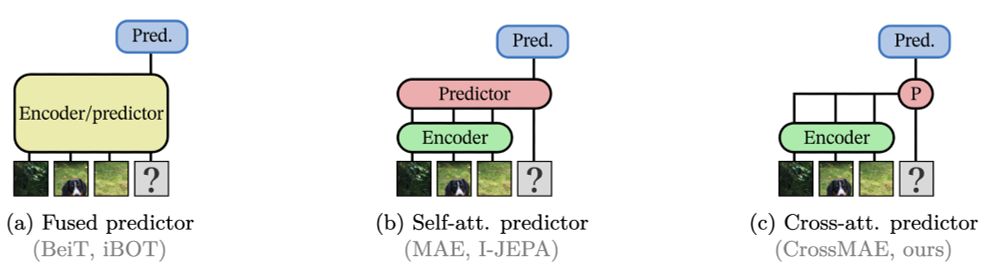
3. Pred arch?
fused (a): 1 transformer w/ all tokens
split (b): enc w/ no [MSK], pred w/ all tokens
cross (c): no patch tokens in pred, cross-attend to them
Patch tokens are the encoder’s problem, [MSK] are the predictor’s problem. Tidy. Good.
14.02.2025 18:04 — 👍 2 🔁 0 💬 1 📌 0
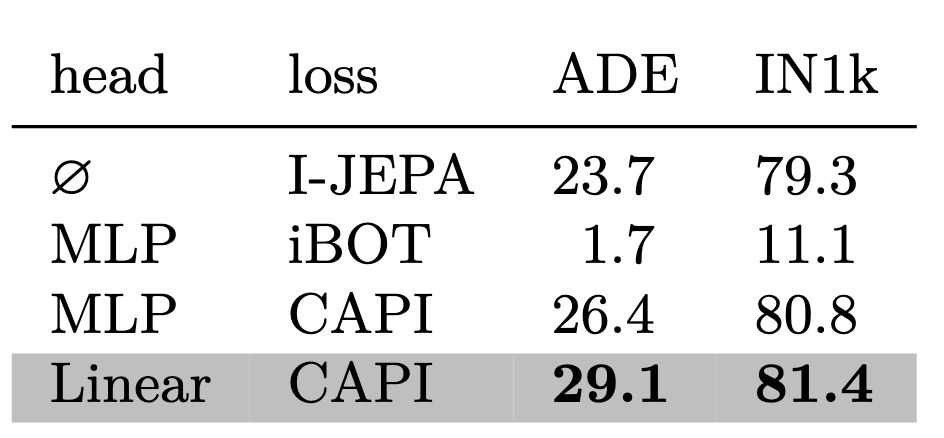
Empirically: using a direct loss is weaker, the iBOT loss does not work alone, using a linear student head to predict the CAPI targets works better than a MLP head.
So we use exactly that.
14.02.2025 18:04 — 👍 4 🔁 0 💬 1 📌 0
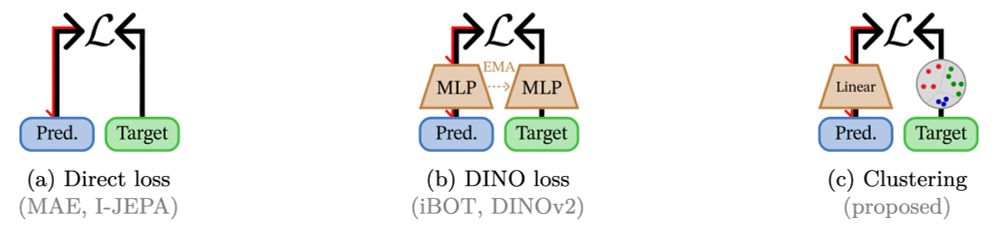
2. Loss?
“DINO head”: good results, too unstable
Idea: preds and targets have diff. distribs, so EMA head does not work on targets → need to separate the 2 heads
So we just use a clustering on the target side instead, and it works
14.02.2025 18:04 — 👍 4 🔁 0 💬 2 📌 0

1. target representation
MAE used raw pixels, BeiT a VQ-VAE. It works, it’s stable. But not good enough.
We use the model we are currently training. Promising (iBOT, D2V2), but super unstable. We do it not because it is easy but because it is hard etc
14.02.2025 18:04 — 👍 3 🔁 0 💬 1 📌 0
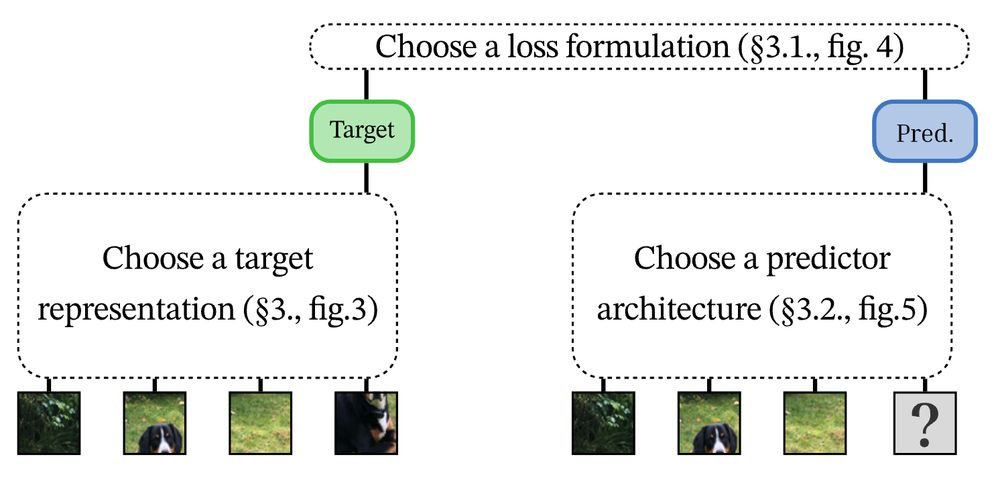
Let’s dissect a bit the anatomy of a mask image model.
1. take an image, convert its patches to representations.
2. given part of this image, train a model to predict the content of the missing parts
3. measure a loss between pred and target
14.02.2025 18:04 — 👍 3 🔁 0 💬 1 📌 0
Language modeling solved NLP. So vision people have tried masked image modeling (MIM).
The issue? It’s hard. BeiT/MAE are not great for representations. iBOT works well, but is too unstable to train without DINO.
→Pure MIM lags behind DINOv2
14.02.2025 18:04 — 👍 4 🔁 0 💬 1 📌 0
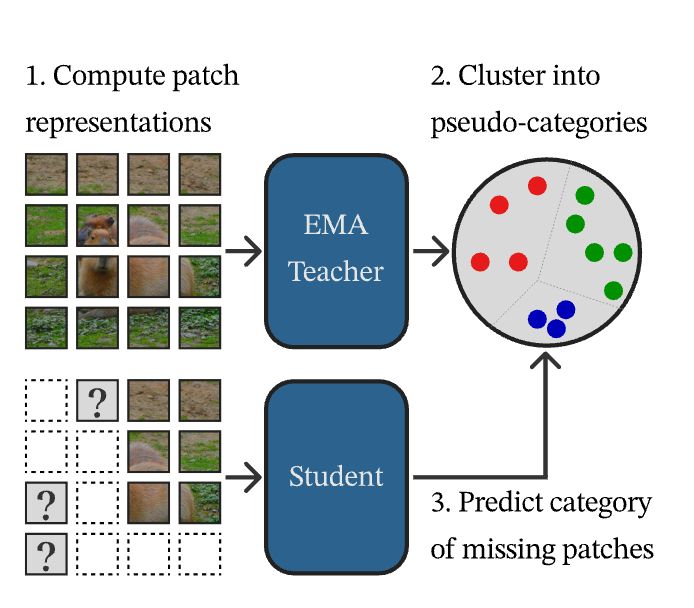
Want strong SSL, but not the complexity of DINOv2?
CAPI: Cluster and Predict Latents Patches for Improved Masked Image Modeling.
14.02.2025 18:04 — 👍 49 🔁 10 💬 1 📌 1
(3/3) LUDVIG uses a graph diffusion mechanism to refine 3D features, such as coarse segmentation masks, by leveraging 3D scene geometry and pairwise similarities induced by DINOv2.
31.01.2025 09:59 — 👍 12 🔁 1 💬 2 📌 0
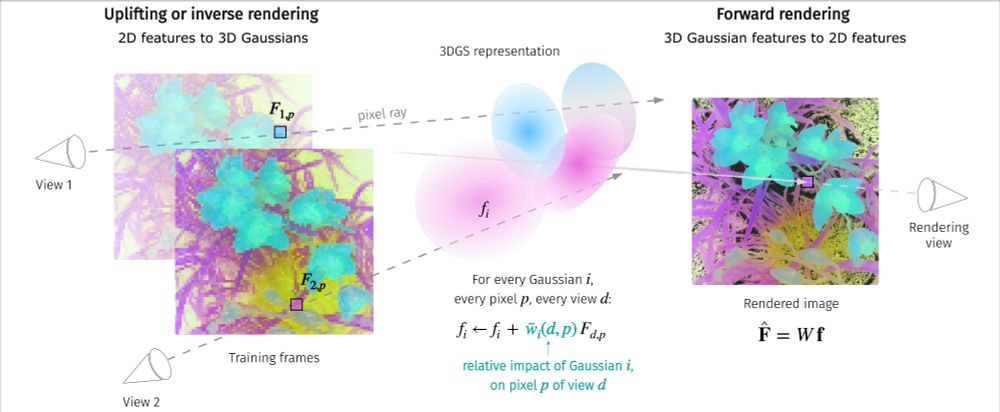
Illustration of the inverse and forward rendering of 2D visual features produced by DINOv2.
(2/3) We propose a simple, parameter-free aggregation mechanism, based on alpha-weighted multi-view blending of 2D pixel features in the forward rendering process.
31.01.2025 09:59 — 👍 10 🔁 1 💬 1 📌 0
(1/3) Happy to share LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes, that uplifts visual features from models such as DINOv2 (left) & CLIP (mid) to 3DGS scenes. Joint work w. @dlarlus.bsky.social @jmairal.bsky.social
Webpage & code: juliettemarrie.github.io/ludvig
31.01.2025 09:59 — 👍 66 🔁 16 💬 1 📌 2
YouTube video by 3Blue1Brown
How They Fool Ya (live) | Math parody of Hallelujah
"Patterns fool ya" I guess
www.youtube.com/watch?v=NOCs...
07.01.2025 14:23 — 👍 5 🔁 0 💬 0 📌 0
Hash functions are really useful to uniquely encode stuff without collision huh
07.01.2025 14:15 — 👍 5 🔁 0 💬 1 📌 0

At least there's diversity of opinions
27.12.2024 18:56 — 👍 13 🔁 1 💬 1 📌 0
Makes the most normal videos on YouTube.
Also a cohort on MinnMax.
https://jacobgeller.com/
Postdoc at Kyutai
https://juliettemarrie.github.io
Transactions on Machine Learning Research (TMLR) is a new venue for dissemination of machine learning research
https://jmlr.org/tmlr/
The place where your nature photos impact science & conservation around the world. Free, nonprofit, & community-powered. 🪲🐌🌿
Research scientist at Meta AI, working on decoding brain signals 🧠
Researcher in machine learning, optimization, computer vision, image and signal processing
PhD Student at Valeo.ai and Telecom Paris
Research scientist at Naver Labs Europe. https://mbsariyildiz.github.io/
Back to France after some time in sunny California and happy Copenhagen. Mistral, Photoroom, Meta (xformers, FairScale, R&D), EyeTribe (acq) Mostly writing around AI
Research Scientist at @Apple. Previous: @Meta (FAIR), @Inria, @MSFTResearch, @VectorInst and @UofG . Egyptian 🇪🇬
Interested in machine learning for 3D data, with a focus on unsupervised learning, interpretability, and real-time!
Senior researcher at IMAGINE (ENPC, LIGM).
Machine learning & computer vision for 3D + geospatial + historical data.
loiclandrieu.com
2nd Year PhD Student from Imagine-ENPC/IGN/CNES
Working on Self-supervised Cross-modal Geospatial Learning.
Personal WebPage: https://gastruc.github.io/
he/him; Researcher at NAVER LABS Europe. Greek, resident a Barcelona. https://www.skamalas.com/
Senior Research Scientist at Valeo.ai (@valeoai.bsky.social)
https://gidariss.github.io/
PhD student in visual representation learning at Valeo.ai and Sorbonne Université (MLIA)
Research Multimodal Generative AI, and now robotics.
Generating MNIST digits for a decade.
Senior scientist at valeo.ai
AI Research Scientist at Valeo.ai | prev. Sorbonne U | https://yuan-yin.github.io | posts in en/fr/zh
Research Scientist | Naver Labs Europe | Prev.: Ph.D. Student @ valeo.ai & IRISA OBELIX | Interested in the intersection of computer vision and frugal learning.
Website: bjoernmichele.com

























