📝We've released the MedXpertQA dataset!
huggingface.co/datasets/Tsi...
📚Check out more details:
Preprint: arxiv.org/pdf/2501.18362
Github: github.com/TsinghuaC3I/...
09.02.2025 02:19 — 👍 2 🔁 0 💬 0 📌 0
Check out the details!
📒Preprint: arxiv.org/pdf/2501.18362
🗃️Data files will be released shortly at: github.com/TsinghuaC3I/...
04.02.2025 13:33 — 👍 0 🔁 0 💬 0 📌 0

We also found that reasoning process errors & perceptual errors (in MM) take up a large percentage of model errors. Error cases provide further insights into the challenges models still face regarding clinical reasoning:
04.02.2025 13:33 — 👍 0 🔁 0 💬 1 📌 0

💡Clinical reasoning facilitates model reasoning evaluation beyond math & code. We annotate MedXpertQA questions as Reasoning/Understanding based on required reasoning complexity.
Comparing 3 inference-time scaled models against their backbones, we find distinct improvements in the Reasoning subset:
04.02.2025 13:32 — 👍 0 🔁 0 💬 1 📌 0
Benchmark construction process - 38k original ➡️ 4k+ final questions
- Filtering for difficulty and diversity using responses from humans + 8 AI experts
- Question rewriting & option set expansion to lower data leakage risk
- Human expert proofreading & error correction
04.02.2025 13:31 — 👍 0 🔁 0 💬 1 📌 0

We improve clinical relevance through
⭐️Medical specialty coverage: MedXpertQA includes questions from 20+ exams of medical licensing level or higher
⭐️Realistic context: MM is the first multimodal medical benchmark to introduce rich clinical information with diverse image types
04.02.2025 13:31 — 👍 0 🔁 0 💬 1 📌 0


Compared with rapidly saturating benchmarks like MedQA, we raise the bar with harder questions and a sharper focus on medical reasoning.
Full results evaluating 17 LLMs, LMMs, and inference-time scaled models:
04.02.2025 13:30 — 👍 0 🔁 0 💬 1 📌 0
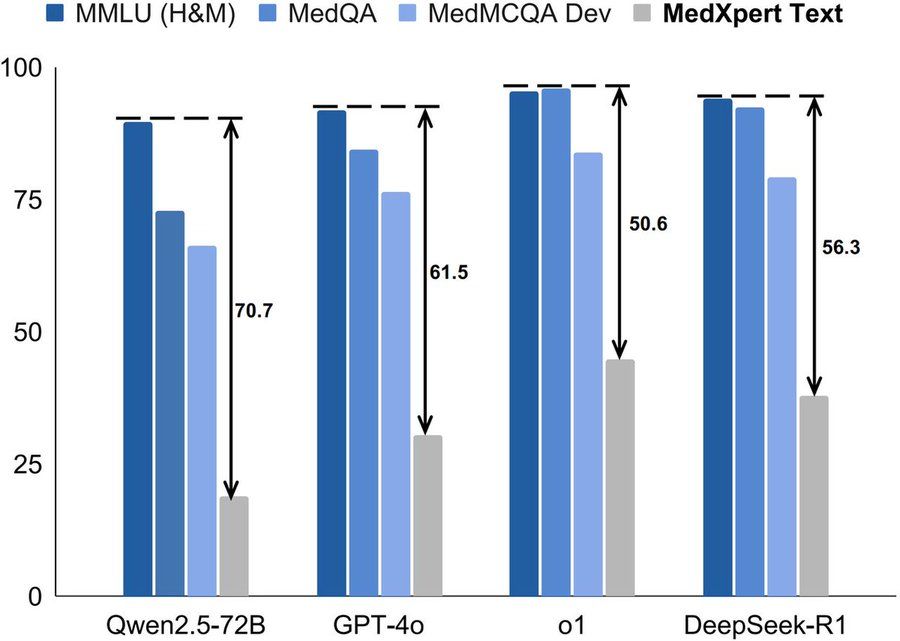
📈How far are leading models from mastering realistic medical tasks? MedXpertQA, our new text & multimodal medical benchmark, reveals gaps in model abilities
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
04.02.2025 13:29 — 👍 4 🔁 1 💬 1 📌 1
Physician, educator, historian, author, podcaster, researcher at Beth Israel Deaconess Medical Center and Harvard Medical School, host of histmed podcast Bedside Rounds, associate editor at NEJM AI, studies 🤖+🧠. 🖖🚲
I talk about computational #openscience communication and science publishing. On the jupyterbook.org & @mystmd.org teams, co-founder of @curvenote.com & @continuous.foundation.
Stanford Medicine is an integrated academic health system comprising the Stanford School of Medicine and adult and pediatric health care delivery systems. Together, they advance biomedicine through research, education, and patient care: med.stanford.edu
Chemical biologist, basketball aficianado, proud homebody. I take my science, not my posts, seriously. Personal account.
Edward and Virginia Taylor Professor of Chemistry, Princeton University. Excited to study the chemistry and biology of the elements! Find out more about us at https://chrischang.chemistry.princeton.edu
Cornell C&CB PhD candidate • Ithaca College grad • NSF Fellow • mass spec nerd • she/her
Chemical biologist @ LLJRC | Covalent drug discovery, chemoproteomics, target engagement assays, medicinal chemistry, etc.
Chemical biology of protein post-translational modifications. https://www.cup.lmu.de/oc/kielkowski/
Asst Prof @ UW-Madison Biochemistry. Protein Engineering, Chemical Biology, Proteomics, Proteases, Enzymology.
Professor of Chemical Biology and Molecular Therapeutics at UC Berkeley
Assistant Professor at Leiden University. Covalent inhibitors and chemoproteomics for antibiotics. Views my own. he/him/his. https://orcid.org/0000-0001-5420-4824
Associate Professor at UCLA, all things chemical biology, chemoproteomic-, covalent-, cysteine- and redox-related
CEO of Precigenetics
Cancer drug discovery at the speed of light.
Assistant Professor, UCSD. Induced proximity, medicinal chemistry, chemical proteomics. https://fergusonlab.ucsd.edu
Assistant Professor at University of Zurich, Head of Precision Proteomics Center at SIAF in Davos
National lab scientist studying cancer drug resistance through machine learning techniques centered around integration of mass spec (e.g. #proteomics technologies). Recreational skier/climber exploring the Pacific Northwest. Views my own.⛷️🧗🏼👩🏼🔬
PI interested in signaling, phosphoproteomics and human diseases
Godfrey D. Stobbe Professor of Bioinformatics at U of Michigan. Trained as a theoretical physicist, now focusing on proteomics and proteogenomics. https://fragpipe.nesvilab.org/
Riley Research Group at the University of Washington, led by @nmriley.bsky.social. Mass Spec, Chem Bio, Cancer, Extracellular (Glyco)biology.
Bringing Proteoforms to Life (sm)
Our Mission is to promote collaboration, education, and innovative research that will accelerate the comprehensive analysis of all human proteoforms. ctdp.org